NLU Tech Talk with KorBERT
7 likes2,106 views

2019/09/05 LGCNS AI Tech Talk for NLU (feat.KorQuAD) - ETRI 언어지능연구실 임준호님 - NLU Tech Talk with KorBERT






![Copyright© 2017 by ETRI
(1) BERT 기술 소개
• Pre-training 학습 난이도
Word2Vec (fastText) BERT
Vocab. 332,733 개 (한국어 형태소) 30,000 개
입력
좌/우 n개 단어 (예: 좌/우 4개)
- target 단어 미입력
512 sequence
- target word masking + two sentences
출력 Target 단어
Masked LM task: target 단어
Next Sentence Prediction task: next sentence 여부
함수
Domain 및 Range
Cardinality
Domain: 332,7334 (약 1.23e22)
Range: 332,733
Domain: 30,000512 (약 1.93e2292)
Range of masked LM task: 30,000
Range of NSP task 2
모델 FFNN (dim X vocab) Transformer (12 layer / 24 layer)
데이터 150M 형태소 (위키백과) Wikipedia (2.5B words) + BookCorpus (800M words)
open a [MASK] account
open a [MASK] account
open a [MASK] account](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-7-320.jpg)
![Copyright© 2017 by ETRI
(1) BERT 기술 소개
• Transformer 모델
백설공주가
독사과를
먹었다.
FFNNQ (FFNNK)T
FFNNV
Softmax ( )
Weight of
독사과를 - 백설공주가
Weight of
독사과를 – 먹었다.
Weighted
sum
BERT base 모델 파라미터
- 512 sequence
- 12 layer
- 768 hidden / 12 heads (64 per head)
BERT base 모델
- Input ∈ R512*768
[per each layer]
- FFNNQ, FFNNK ∈ R768*64 (12개)
- FFNNV ∈ R768*64 (12개)](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-8-320.jpg)

![Copyright© 2017 by ETRI
(1) BERT 기술 소개
• Pre-training 학습 instance 예제
INFO:tensorflow:*** Example ***
INFO:tensorflow:tokens: [CLS] 장 서 희/NNP_ 는/JX_ 지나/VV_ [MASK] [MASK] [MASK] '/SS_ 인 /VV_ [MASK] 아 가 씨/NNG_ [MASK] 에서
/JKB_ 악 녀/NNG_ 은 아리 영/NNG_ [MASK] [MASK] 하/XSV_ 어/EC_ 연기/NNG_ 대상/NNG_ 의/JKG_ 대상/NNG_ [MASK] 차지/NNG_ 하/XSV_ 었
/EP_ 고/EC_ ,/SP_ 고 현정/NNP_ 은/JX_ '/SS_ 미 실/NNG_ æ 로/JKB_ 2009/SN_ MBC/SL_ 연기/NNG_ 대상/NNG_ 에서/JKB_ 대상/NNG_ [MASK] 를
/JKO_ 품/NNG_ 에/JKB_ 안/VV_ 았/EP_ 다/EF_ ./SF_ [SEP] 순 스케/NNP_ 는/JX_ "/SS_ 맨유/NNG_ 가/JKS_ 셀 틱 전/NNG_ 에/JKB_ 후보/NNG_ 선수
/NNG_ 들/XSN_ 을/JKO_ [MASK] [MASK] ㄴ다/EF_ 고 하/VV_ 어도/EC_ 톱/NNG_ 클래스/NNG_ 의/JKG_ inematic/SL_ 이/VCP_ 라는/ETM_ [MASK]
을/JKO_ 부인/NNG_ [MASK] [MASK] [MASK] 없/VA_ [MASK] [MASK] 때문/NNB_ 에/JKB_ 16/SN_ 강/NNG_ 진출/NNG_ 의/JKG_ 가능/NNG_ 성
/XSN_ 이/JKS_ 0/SN_ [MASK] 가/JKS_ 될 때/NNG_ 까지/JX_ coph [MASK] 하/XSV_ 지/EC_ 않/VX_ 겠/EP_ 다/EF_ "/SS_ 는/JX_ 각오/NNG_ 를/JKO_
전하/VV_ [MASK] 다/EF_ ./SF_ [SEP]
INFO:tensorflow:input_ids: 2 331 253 894 18 115 4 4 4 26 326 206 4 186 201 2924 4 27 1544 1822 620 7279 1028 4 4 9 20 637 527 13 527
4 926 9 12 23 17 194 7844 21 26 227 912 16312 31 1204 953 637 ... 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 (512개)
INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ... 0 0 0 0 0 (512개)
INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 ... (512개)
INFO:tensorflow:masked_lm_positions: 6 7 8 12 16 23 24 31 39 43 51 74 75 81 83 86 89 90 91 93 94 105 110 111 122 0 0 ... (77개)
INFO:tensorflow:masked_lm_ids: 10 2010 39 20 26 28 471 11 21 26 7896 907 3058 7125 121 33 40 35 55 8 7 81 638 3803 12 0 0 ... (77개)
INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0
0.0 0.0 ... (77개)
INFO:tensorflow:next_sentence_labels: 1](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-10-320.jpg)
![Copyright© 2017 by ETRI
(1) BERT 기술 소개
• 비고: Masking 전략
– 15% of the token positions at random for prediction
• 80% of the time, replace with [MASK]
• 10% of the time, replace random word
• 10% of the time, keep same
학습 데이터: 33억 단어
사전: 3만 vocab
Masking:15% random (40 epoch)](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-11-320.jpg)
![Copyright© 2017 by ETRI
(1) BERT 기술 소개
• 비고: Random Short Sequence
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""Creates `TrainingInstance`s for a single document."""
document = all_documents[document_index]
# Account for [CLS], [SEP], [SEP]
max_num_tokens = max_seq_length – 3
# We *usually* want to fill up the entire sequence since we are padding
# to `max_seq_length` anyways, so short sequences are generally wasted
# computation. However, we *sometimes*
# (i.e., short_seq_prob == 0.1 == 10% of the time) want to use shorter
# sequences to minimize the mismatch between pre-training and fine-tuning.
# The `target_seq_length` is just a rough target however, whereas
# `max_seq_length` is a hard limit.
target_seq_length = max_num_tokens
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
…
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
…](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-12-320.jpg)







![Copyright© 2017 by ETRI
(2.1) BERT 이후 최근 연구 결과
• BERT update: Whole word masking model (Google)
– Key points
Input Text the man jumped up , put his basket on phil ##am ##mon ' s head
Original
Masked Input
[MASK] man [MASK] up , put his [MASK] on phil [MASK] ##mon ' s head
Whole Word
Masked Input
the man [MASK] up , put his basket on [MASK] [MASK] [MASK] ' s head](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-20-320.jpg)














![Copyright© 2017 by ETRI
(3) Some Questions
• (4) 미해결 문제 (selected from too many items)
– [Document-level QA] Google Natural Questions
Source of questions
The questions consist of real anonymized, aggregated queries issued
to the Google search engine. Simple heuristics are used to filter
questions from the query stream. Thus the questions are “natural”, in
that they represent real queries from people seeking information.
Task definition
The input to a model is a question together with an entire Wikipedia
page. The target output from the model is: 1) a long-answer (e.g., a
paragraph) from the page that answers the question, or alternatively
an indication that there is no answer on the page; 2) a short answer
where applicable. The task was designed to be close to an end-to-end
question answering application.](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-36-320.jpg)
![Copyright© 2017 by ETRI
(3) Some Questions
• (4) 미해결 문제 (selected from too many items)
– [Multi-hop QA] HotpotQA
• A Dataset for Diverse, Explainable Multi-hop Question Answering
Key features
- require finding and reasoning over multiple
supporting documents to answer
- provide sentence-level supporting facts
required for reasoning, allowing QA systems to
reason with strong supervision and explain the
predictions](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-37-320.jpg)
![Copyright© 2017 by ETRI
(3) Some Questions
• (4) 미해결 문제 (selected from too many items)
– [IR] Latent Retrieval for Weakly Supervised Open Domain
Question Answering (Google)
Table 5: Main results:
End-to-end exact match
for open-domain question
answering from question-
answer pairs only. Datasets
where question askers
know the answer behave
differently from datasets
where they do not.
BERTQ / BERTB : inverse close
task (ICT) pre-training
Top-k Retrieval : use Locality
Sensitive Hashing algorithm](https://image.slidesharecdn.com/02etri-190919052132/85/NLU-Tech-Talk-with-KorBERT-38-320.jpg)

NLU Tech Talk with KorBERT
- 1. Copyright© 2017 by ETRI 2019. 09. 05. 임 준 호 언어지능연구실 / 한국전자통신연구원 국가전략프로젝트– 엑소브레인 SW 개발 NLU Tech Talk with KorBERT
- 2. Copyright© 2017 by ETRI 목차 • (1) BERT 기술 소개 • (2) KorBERT 소개 • (3) Some Questions
- 3. Copyright© 2017 by ETRI 시작하기에 앞서 • Paper Reading Tip – (1) 논문에서 해결하고자 하는 문제가 무엇인가? • 기존 연구 / 제안 방법 / 실험 결과 – (2) 딥러닝 모델의 경우, • 곱하기/더하기 대상이 무엇인가? 차원(dimension)이 어떻게 바뀌는가? – CNN (with max-pooling) – RNN – Self-Attention – (3) 모델을 구성 요소 별로 나눠서 생각해보기 • 필수적인 요소와 부가적인 요소 구분하여 생각해보기
- 4. Copyright© 2017 by ETRI (1) BERT 기술 소개 • BERT에서 해결하고자 하는 문제 = contextual representation – 문제점 • 딥러닝 자연어처리에서 단어를 벡터로 표현하는 워드임베딩은 필수적임 – 심볼인 단어를 실수 벡터로 표현해야 뉴럴넷(i.e. FFNN) 적용 가능 • 기존 워드임베딩 접근 방법은 문맥을 고려하지 못하는 한계를 지님 – 접근 방법 • 입력 문장(N개 단어)에 대해서, 뉴럴넷을 적용한 결과(N개 출력)를 단어의 문맥 반영 벡터로 활용 <기존 워드임베딩 접근방법 > (context free manner) open a bank account open a bank account open a bank account bank 문맥벡터 <BERT 접근방법 > (contextual representation)
- 5. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Contextual Representation 적용 전/후 – 적용 전 • 응용 태스트 별 별도의 딥러닝 모델과 학습 데이터를 이용하여 모델 개발 – 적용 후 • 1) 대용량 Raw 데이터로부터 공통 언어모델(Language Model) 미리 학습 (pre-train) • 2) 학습된 공통 모델을 응용 태스크 별로 재학습(fine-tuning)하여 적용 Task 학습데이터 Task 별 딥러닝 모델 (예: MRC의 경우, 단락-질문 사이 Attention) 대용량 Raw 데이터 Self-Attention 기반 딥러닝 모델 (N개의 입력 토큰 사이의 N x N Attention) Task 학습데이터 <기존 접근방법> <BERT 접근방법> Task Supervision Task Supervision Language Model Self-Supervision
- 6. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Pre-training 단계 (언어모델 학습) – 1) 공백 단어 예측 • 입력 문장 중, 15%의 단어를 masking 후 해당 단어를 맞추는 태스크 • BERT 특징: 양방향 정보를 이용한 단어 예측 – 기존 연구: 단어 예측 시, 단일 방향의 정보만 고려 – 2) 문장 선후관계 예측 • 임의의 두 문장에 대해, 두 문장이 선/후 관계가 맞는지 맞추는 태스크 – (비고) 두 태스크 모두 별도의 정답 말뭉치 없이 대용량 원시 말뭉치로부 터 자동으로 생성 가능 양방향 기반 단어 예측을 위하여 BERT에서 제안한 학습방법
- 7. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Pre-training 학습 난이도 Word2Vec (fastText) BERT Vocab. 332,733 개 (한국어 형태소) 30,000 개 입력 좌/우 n개 단어 (예: 좌/우 4개) - target 단어 미입력 512 sequence - target word masking + two sentences 출력 Target 단어 Masked LM task: target 단어 Next Sentence Prediction task: next sentence 여부 함수 Domain 및 Range Cardinality Domain: 332,7334 (약 1.23e22) Range: 332,733 Domain: 30,000512 (약 1.93e2292) Range of masked LM task: 30,000 Range of NSP task 2 모델 FFNN (dim X vocab) Transformer (12 layer / 24 layer) 데이터 150M 형태소 (위키백과) Wikipedia (2.5B words) + BookCorpus (800M words) open a [MASK] account open a [MASK] account open a [MASK] account
- 8. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Transformer 모델 백설공주가 독사과를 먹었다. FFNNQ (FFNNK)T FFNNV Softmax ( ) Weight of 독사과를 - 백설공주가 Weight of 독사과를 – 먹었다. Weighted sum BERT base 모델 파라미터 - 512 sequence - 12 layer - 768 hidden / 12 heads (64 per head) BERT base 모델 - Input ∈ R512*768 [per each layer] - FFNNQ, FFNNK ∈ R768*64 (12개) - FFNNV ∈ R768*64 (12개)
- 9. Copyright© 2017 by ETRI (1) BERT 기술 소개 • BERT 모델 Pre-training 입력/출력 NSP Mask LM Mask LM Mask LM Masked Sentence A Masked Sentence B MASK 원문: my dog is cute / he likes playing MASK MASK MASK MASK MASK Transformer Layer #1 Transformer Layer #12 … Weight 학습 (NSP + Mask LM loss)
- 10. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Pre-training 학습 instance 예제 INFO:tensorflow:*** Example *** INFO:tensorflow:tokens: [CLS] 장 서 희/NNP_ 는/JX_ 지나/VV_ [MASK] [MASK] [MASK] '/SS_ 인 /VV_ [MASK] 아 가 씨/NNG_ [MASK] 에서 /JKB_ 악 녀/NNG_ 은 아리 영/NNG_ [MASK] [MASK] 하/XSV_ 어/EC_ 연기/NNG_ 대상/NNG_ 의/JKG_ 대상/NNG_ [MASK] 차지/NNG_ 하/XSV_ 었 /EP_ 고/EC_ ,/SP_ 고 현정/NNP_ 은/JX_ '/SS_ 미 실/NNG_ æ 로/JKB_ 2009/SN_ MBC/SL_ 연기/NNG_ 대상/NNG_ 에서/JKB_ 대상/NNG_ [MASK] 를 /JKO_ 품/NNG_ 에/JKB_ 안/VV_ 았/EP_ 다/EF_ ./SF_ [SEP] 순 스케/NNP_ 는/JX_ "/SS_ 맨유/NNG_ 가/JKS_ 셀 틱 전/NNG_ 에/JKB_ 후보/NNG_ 선수 /NNG_ 들/XSN_ 을/JKO_ [MASK] [MASK] ㄴ다/EF_ 고 하/VV_ 어도/EC_ 톱/NNG_ 클래스/NNG_ 의/JKG_ inematic/SL_ 이/VCP_ 라는/ETM_ [MASK] 을/JKO_ 부인/NNG_ [MASK] [MASK] [MASK] 없/VA_ [MASK] [MASK] 때문/NNB_ 에/JKB_ 16/SN_ 강/NNG_ 진출/NNG_ 의/JKG_ 가능/NNG_ 성 /XSN_ 이/JKS_ 0/SN_ [MASK] 가/JKS_ 될 때/NNG_ 까지/JX_ coph [MASK] 하/XSV_ 지/EC_ 않/VX_ 겠/EP_ 다/EF_ "/SS_ 는/JX_ 각오/NNG_ 를/JKO_ 전하/VV_ [MASK] 다/EF_ ./SF_ [SEP] INFO:tensorflow:input_ids: 2 331 253 894 18 115 4 4 4 26 326 206 4 186 201 2924 4 27 1544 1822 620 7279 1028 4 4 9 20 637 527 13 527 4 926 9 12 23 17 194 7844 21 26 227 912 16312 31 1204 953 637 ... 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 (512개) INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ... 0 0 0 0 0 (512개) INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 ... (512개) INFO:tensorflow:masked_lm_positions: 6 7 8 12 16 23 24 31 39 43 51 74 75 81 83 86 89 90 91 93 94 105 110 111 122 0 0 ... (77개) INFO:tensorflow:masked_lm_ids: 10 2010 39 20 26 28 471 11 21 26 7896 907 3058 7125 121 33 40 35 55 8 7 81 638 3803 12 0 0 ... (77개) INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 ... (77개) INFO:tensorflow:next_sentence_labels: 1
- 11. Copyright© 2017 by ETRI (1) BERT 기술 소개 • 비고: Masking 전략 – 15% of the token positions at random for prediction • 80% of the time, replace with [MASK] • 10% of the time, replace random word • 10% of the time, keep same 학습 데이터: 33억 단어 사전: 3만 vocab Masking:15% random (40 epoch)
- 12. Copyright© 2017 by ETRI (1) BERT 기술 소개 • 비고: Random Short Sequence def create_instances_from_document( all_documents, document_index, max_seq_length, short_seq_prob, masked_lm_prob, max_predictions_per_seq, vocab_words, rng): """Creates `TrainingInstance`s for a single document.""" document = all_documents[document_index] # Account for [CLS], [SEP], [SEP] max_num_tokens = max_seq_length – 3 # We *usually* want to fill up the entire sequence since we are padding # to `max_seq_length` anyways, so short sequences are generally wasted # computation. However, we *sometimes* # (i.e., short_seq_prob == 0.1 == 10% of the time) want to use shorter # sequences to minimize the mismatch between pre-training and fine-tuning. # The `target_seq_length` is just a rough target however, whereas # `max_seq_length` is a hard limit. target_seq_length = max_num_tokens if rng.random() < short_seq_prob: target_seq_length = rng.randint(2, max_num_tokens) … truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng) …
- 13. Copyright© 2017 by ETRI (1) BERT 기술 소개 • Fine-tuning 단계 (응용 태스크 적용) – 언어처리, 텍스트 분류, 기계독해 등에 적용 • 언어처리: 개체명인식, 구문분석 등 언어처리 문제에 적용 • 문장분류: 단일 문장 주제 분류 또는 두 문장 사이의 유사성 분석 문제에 적용 • 기계독해: 질문과 단락을 입력 받은 후, 단락에서 정답 경계 인식 문제에 적용
- 14. Copyright© 2017 by ETRI (1) BERT 기술 소개 • 실험 결과 – 한 줄 요약: SOTA @ 2018-10
- 15. Copyright© 2017 by ETRI (2) KorBERT 소개 • (2.1) BERT 이후 최근 연구 결과 • (2.2) 한국어에 적합한 Vocab. 생성 및 KorBERT 학습 • (2.3) KorBERT 활용
- 16. Copyright© 2017 by ETRI (2) KorBERT 소개에 앞서 • 엑소브레인 프로젝트 소개 – 전문가(예: 변호사, 변리사)와 지식 소통이 가능한 언어지능 SW • 한국어 분석, 단답형QA 기술의 OpenAPI 공개를 통한 생태계 활성화 병행 • 엑소브레인 OpenAPI 소개 – 중소·벤처 기업, 학교, 개인 개발자 등의 다양한 응용 개발 촉진과 관련 산업 의 생태계 활성화 및 인력 양성 지원 목적 • http://aiopen.etri.re.kr/ • 2017.10.30 서비스 시작 – API 사용 통계 (2019.08.27 기준) • 기관 수: 1,004 기관 • 사용자 수: 2,617 명 • 누적 일 평균 사용량: 39,820건 • 최근 7일 일 평균 사용량: 69,848건 • KorBERT 다운로드: 251건
- 17. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • BERT pre-training 관련 최근 연구 결과 – (2019.04) ERNIE: Enhanced Representation through Knowledge Integration – (2019.05) BERT update: Whole word masking model – (2019.07) SpanBERT: Improving Pre-training by Representing and Predicting Spans – (2019.07) RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 18. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • (기타) 언어모델 pre-training 관련 최근 연구 결과 – (2019.06) XLNet: Generalized Autoregressive Pretraining for Language Understanding – (2019.05) Unified Language Model Pre-training for Natural Language Understanding and Generation – (2019.05) MASS: Masked Sequence to Sequence Pre-training for Language Generation – (2019.03) Cloze-driven Pretraining of Self-attention Networks
- 19. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • ERNIE: Enhanced Representation through Knowledge Integration (Baidu) – Key points: masking strategy • Basic-level masking • Entity-level masking • Phrase-level masking
- 20. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • BERT update: Whole word masking model (Google) – Key points Input Text the man jumped up , put his basket on phil ##am ##mon ' s head Original Masked Input [MASK] man [MASK] up , put his [MASK] on phil [MASK] ##mon ' s head Whole Word Masked Input the man [MASK] up , put his basket on [MASK] [MASK] [MASK] ' s head
- 21. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • SpanBERT: Improving Pre-training by Representing and Predicting Spans (Univ. Washington, Univ. Princeton, Facebook) – Key points • Span Masking • Span Boundary Objective • Single-Sequence Training
- 22. Copyright© 2017 by ETRI (2.1) BERT 이후 최근 연구 결과 • RoBERTa: A Robustly Optimized BERT Pretraining Approach (Facebook) – Key points • Static vs. Dynamic Masking • Model Input Format and Next Sentence Prediction – SEGMENT-PAIR+NSP – SENTENCE-PAIR+NSP – FULL-SENTENCES (no NSP) – DOC-SENTENCES (no NSP) • Training with large batches
- 23. Copyright© 2017 by ETRI (2.2) 한국어에 적합한 Vocab. 구축 및 KorBERT 학습 • (1) 대용량 말뭉치 수집 – 총 23.5GB / 약 47억개 형태소 수집 – 유형: 위키백과 및 신문기사 (약 15년 분량) 등 • (2) Vocab 구축 – 형태소 단위 모델 및 wordpiece 단위 모델 병렬 구축 및 비교 • (3) Pre-training 학습 데이터 생성 – 대용량 말뭉치 대상 Mask LM 및 NSP task 데이터 생성 • (4) Pre-training 학습 수행
- 24. Copyright© 2017 by ETRI (2.2) 한국어에 적합한 Vocab. 구축 및 KorBERT 학습 • Vocab. 구축 고려사항 – 수량: 최대 3만 여개의 vocab. 구축 – Vocab entry가 통계적으로 일정 빈도 이상 발생 필요 – UNK 발생 최소화 • Vocab 구축 후보 – (1) 음절 단위 사전 구축 • 예: 한 / 국 / 어_ / 단 / 어 / 는_ / 형 / 태 / 소 / 로_ / 구 / 성 / 된 / 다 / ._ (15 token) – 영어 character based LM과 유사 – 사전 entry 수 감소 및 표현력 저하 – 동일한 512 seq이더라도, 더 짧은 문장 표현 한계 – (2) Wordpiece 단위 사전 구축 • 예: 한국 / ##어 / 단 / ##어는 / 형태 / ##소로 / 구 / ##성된 / ##다. (9 token) – 조사/어미가 이전 형태소와 결합되는 경우 빈번 – (3) 형태소 단위 사전 구축 • 예: 한국어/NNP_ 단어/NNG_ 는/JX_ 형태소/NNG_ 로/JKB_ 구성/NNG_ 되/XSV_ ㄴ다/EF_ ./SF_ (9 token) – 형태소 분석기 적용 필요
- 25. Copyright© 2017 by ETRI (2.2) 한국어에 적합한 Vocab. 구축 및 KorBERT 학습 • Vocab. 구축 세부 내용 – (1) 어절의 시작 표현 / 끝 표현 구분 • 시작 구분: 한국 ##어 단 ##어는 ... • 끝 구분: 한국 어_ 단 어는_ – (2) 형태소 단위 사전 구축 시, 형태소 태그 사용 여부 • 태그 사용: 한국어/NNP_ 단어/NNG_ 는/JX_ ... • 태그 미사용: 한국어_ 단어_ 는_ ... 구성_ 되_ ㄴ다_ ._ – 사전 구축 결과 • BPE 알고리즘 사용 • 형태소 기반 사전: 30,349 vocabs • Wordpiece 기반 사전: 30,797 vocabs 비고: TTA표준 호환 형태소분석기 사용 필요 <형태소 분석 결과 예> (1) 사용하다: 사용/NNG + 하/XSV <-> 사용하/VV (2) 산다: 살/VV + ㄴ다/EF <-> 산/VV + 다/EF (3) 연구원: 연구/NNG + 원/XSN <-> 연구원/NNG
- 26. Copyright© 2017 by ETRI (2.2) 한국어에 적합한 Vocab. 구축 및 KorBERT 학습 • Pre-training 학습 데이터 생성 – 중요 파라미터 • max_seq_length / masked_lm_prob / max_predictions_per_seq • dupe_factor – Training epoch 보다 큰 dupe factor 사용 Dynamic Masking – (초기) word masking (후기) whole-word masking • Pre-training 학습 수행 – Base 모델 파라미터 • 512 sequence / 12 layer / 768 hidden/ 12 heads (64 per head) – 중요 학습 파라미터 train_batch_size 가능한 최대 크기 (메모리 부족 시, gradient accumulation 적용) max_seq_length 학습 데이터 생성 시 파라미터 (초기 256, 후기 512) max_predictions_per_seq 학습 데이터 생성 시 파라미터 num_train_steps 학습 데이터 생성 instance 수 기반 계산 num_warmup_steps 처음 학습 시 10,000 step (추가 학습 시 -1) learning_rate 처음 학습 시 1e-4 (추가 학습 시 3e-5) weight_decay_rate 0.01
- 27. Copyright© 2017 by ETRI (2.2) 한국어에 적합한 Vocab. 구축 및 KorBERT 학습 • KorBERT 구축 모델 평가
- 28. Copyright© 2017 by ETRI (2.3) KorBERT 활용 • 법률분야 질의응답 시스템
- 29. Copyright© 2017 by ETRI (2.3) KorBERT 활용 • 법률분야 대상 추가 pre-training – 일반분야 언어모델 기반 법률분야 언어모델 구축 • 법률분야 원시 말뭉치: 186MB – 법률분야 기계독해 성능 • 평가셋: 법률분야 GS1000 평가셋 • (법률분야 모델) EM52.0% / F1 79.20% • (일반분야 모델) EM 50.5% / F1 77.19% • KorBERT 기반 검색 단락 재순위화 모듈 개발 – IR 대비 Top1 +16.7% 성능 (IR: 57.0% / 재순위화: 73.7%) – 질문: 대한민국헌법에서 대통령의 임기는 얼마인가? 검색 순위 재순위 순위 재순위 점수 정답 근거단락 1 4 0.0002 70일 내지 40일전 ①대통령의 임기가 만료되는 때에는 임기만료 70일 내지 40일전에 후임자 를 선거한다. 2 2 0.0011 4년 ②원장은 국회의 동의를 얻어 대통령이 임명하고, 그 임기는 4년으로 하며, 1차에 한하여 중임할 수 있다. 3 3 0.0004 중임변경을 위한 헌법개정 ②대통령의 임기연장 또는 중임변경을 위한 헌법개정은 그 헌법개정 제안 당시의 대통령에 대하여는 효력 4 1 0.9997 5년 대통령의 임기는 5년으로 하며, 중임할 수 없다.
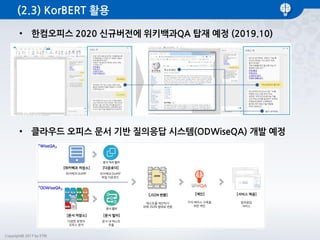
- 30. Copyright© 2017 by ETRI (2.3) KorBERT 활용 • 한컴오피스 2020 신규버전에 위키백과QA 탑재 예정 (2019.10) • 클라우드 오피스 문서 기반 질의응답 시스템(ODWiseQA) 개발 예정
- 31. Copyright© 2017 by ETRI (3) Some Questions • 실시간 서비스를 위한 속도 개선 – Parameter tuning – Quantization, Weights pruning, Knowledge distillation • (1) BERT 모델 구조적 한계 – Fixed sequence length & Expensive computation cost • (2) 외부 지식 / 메모리 활용 필요 – BERT 모델 110M / 340M 파라미터에 모든 지식 저장 • (3) Cross-Encoding 방식 한계 – 사용자 질문마다 모든 정답 후보 단락을 새로 계산해야 함 • (4) 미해결 문제 (selected from too many items) – Document-level QA / Multi-hop QA / IR
- 32. Copyright© 2017 by ETRI (3) Some Questions • (1) Fixed sequence length & Expensive computation cost – Adaptive Attention Span in Transformers (Facebook) • Transformer 모델 기반 character level LM task z : each attention head span (학습 대상) R : 파라미터 (32)
- 33. Copyright© 2017 by ETRI (3) Some Questions • (2) 외부 지식 / 메모리 활용 필요 – Large Memory Layers with Product Keys (Facebook) H=4 memory heads / k = 32 keys per head / |K| = 5122 memory slots Table 3: Perplexity and memory usage for different memory positions in a transformer with 6 layers. Adding a memory in positions 4 or 5 maximizes the performance (layer 1 is the worst).
- 34. Copyright© 2017 by ETRI (3) Some Questions • (3) Cross-Encoding 방식 한계 – #1: Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index ( today talk by Minjoon Seo) – #2: Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers (Facebook) • Given a dialogue context (i.e. conversation history), selects the best next sentence to output from N possible candidates. 정답 단락 BERT 결과 사전 색인 가능
- 35. Copyright© 2017 by ETRI (3) Some Questions • (3) Cross-Encoding 방식 한계 – #2: Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers (Facebook) Pre-training on Reddit, which is a dataset more adapted to dialogue
- 36. Copyright© 2017 by ETRI (3) Some Questions • (4) 미해결 문제 (selected from too many items) – [Document-level QA] Google Natural Questions Source of questions The questions consist of real anonymized, aggregated queries issued to the Google search engine. Simple heuristics are used to filter questions from the query stream. Thus the questions are “natural”, in that they represent real queries from people seeking information. Task definition The input to a model is a question together with an entire Wikipedia page. The target output from the model is: 1) a long-answer (e.g., a paragraph) from the page that answers the question, or alternatively an indication that there is no answer on the page; 2) a short answer where applicable. The task was designed to be close to an end-to-end question answering application.
- 37. Copyright© 2017 by ETRI (3) Some Questions • (4) 미해결 문제 (selected from too many items) – [Multi-hop QA] HotpotQA • A Dataset for Diverse, Explainable Multi-hop Question Answering Key features - require finding and reasoning over multiple supporting documents to answer - provide sentence-level supporting facts required for reasoning, allowing QA systems to reason with strong supervision and explain the predictions
- 38. Copyright© 2017 by ETRI (3) Some Questions • (4) 미해결 문제 (selected from too many items) – [IR] Latent Retrieval for Weakly Supervised Open Domain Question Answering (Google) Table 5: Main results: End-to-end exact match for open-domain question answering from question- answer pairs only. Datasets where question askers know the answer behave differently from datasets where they do not. BERTQ / BERTB : inverse close task (ICT) pre-training Top-k Retrieval : use Locality Sensitive Hashing algorithm
- 39. Copyright© 2017 by ETRI 감사합니다