







![9
How to avoid this mistake...
• Kramer could have ensured that he never made this mistake in the first
place by setting up his prompt to show exactly where he was. For
unix/linux, put in your .profile, or .bash_profile.
If using the bash shell:
export PS1="[$(whoami)@$(hostname)]$ “
For sqlplus, it is the sqlprompt setting:
MIKE6:system:mike61> show sqlp
sqlprompt "MIKE6:system:mike61> "
It is setup in a sqlplus admin file:
[oracle@mikek5 oracle]$ tail -2 $ORACLE_HOME/sqlplus/admin/glogin.sql
set sqlprompt "_user 'at' _connect_identifier> "](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-9-320.jpg)
























































































































































































































































































![291
Block Dumps – Data Section
ntab=1 Number of tables= 1 (2+ for clusters)
nrow=14 Number of rows = 14
frre=-1 First free row index entry – 1 (add 1)
fsbo=0x2e Free space begin offset
fseo=0x18fb Free space end offset
avsp=0x1d3b Available block space = 1d3b = 7483
tosp=0x1de0 Space avail. post commit=1de0=7648
0xe:pti[0] nrow=14 offs=0 Table Info
0x12:pri[0] offs=0x18fb (6395)Row Info Record 0
0x14:pri[1] offs=0x1921 (6433)Row Info Record 1
… Row Info Records 2–13
block_row_dump: Row Data is Next!](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-291-320.jpg)

![293
Block Dumps – output from udump
tab 0, row 13, @0x1b0b
tl: 39 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 50 23
col 1: [ 6] 4d 49 4c 4c 45 52
col 2: [ 5] 43 4c 45 52 4b
col 3: [ 3] c2 4e 53
col 4: [ 7] 77 b6 01 17 01 01 01
col 5: [ 2] c2 0e
col 6: *NULL*
col 7: [ 2] c1 0b…](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-293-320.jpg)




![298
Block Dumps – Data Section
DUMP OUTPUT - EMPNO:
col 0: [ 3] c2 50 23
Hex to Decimal: Col0 = EMPNO = 7934
50 (Hex) = 80 (Decimal) – 1 = 79
23 (Hex) = 35 (Decimal) – 1 = 34
c2: Number in the thousands (c2 is exponent)](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-298-320.jpg)
![299
Block Dumps – Data Section
DUMP OUTPUT - ENAME:
col 1: [ 6] 4d 49 4c 4c 45 52
Hex to Character: Col1 = ENAME = MILLER
4d (Hex) = M (Character)
49 (Hex) = I (Character)
4c (Hex) = L (Character)
4c (Hex) = L (Character)
45 (Hex) = E (Character)
52 (Hex) = R (Character)](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-299-320.jpg)
![300
Block Dumps – Data Section
DUMP OUTPUT - JOB:
col 2: [ 5] 43 4c 45 52 4b
Hex to Character: Col2 = JOB = CLERK
43 (Hex) = C (Character)
4c (Hex) = L (Character)
45 (Hex) = E (Character)
52 (Hex) = R (Character)
4b (Hex) = K (Character)](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-300-320.jpg)
![301
Block Dumps – Data Section
DUMP OUTPUT - MGR:
col 3: [ 3] c2 4e 53
Hex to Decimal: Col3 = MGR = 7782
4e (Hex) = 78 (Decimal) – 1 = 77
53 (Hex) = 83 (Decimal) – 1 = 82](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-301-320.jpg)
![302
Block Dumps – Data Section
DUMP OUTPUT - HIREDATE:
col 4: [ 7] 77 b6 01 17 01 01 01
Hex to Decimal: Col4 = HIREDATE = 23-JAN-82
77 (Hex) = 119 (Decimal) – 100 = 19
B6 (Hex) = 182 (Decimal) – 100 = 82
01(Hex) = 1 (Decimal) <month>
17 (Hex) = 23 (Decimal) <day>
01 01 01 (Hex) = This is the Hour, Minute, Second
(none were entered when the date was entered…default)](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-302-320.jpg)
![303
Block Dumps – Data Section
DUMP OUTPUT - SAL:
col 5: [ 2] c2 0e
Hex to Decimal: Col5 = SAL = 1300
0e (Hex) = 14 (Decimal) – 1 = 13
c2 = add two zero‟s](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-303-320.jpg)

![305
Block Dumps – Data Section
DUMP OUTPUT - DEPTNO:
col 7: [ 2] c1 0b
Hex to Decimal: Col7 = DEPTNO= 10
0B (Hex) = 11 (Decimal) – 1 = 10
c1 = number in the tens](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-305-320.jpg)


























![334
Dump the EMP2 block (Partial)
block_row_dump:
tab 0, row 0, @0x1f5d
tl: 43 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 4b 64
col 1: [ 5] 41 4c 4c 45 4e A L L E N
col 2: [ 8] 53 41 4c 45 53 4d 41 4e
col 3: [ 3] c2 4d 63
col 4: [ 7] 77 b5 02 14 01 01 01
col 5: [ 2] c2 11
col 6: [ 2] c2 04
col 7: [ 2] c1 1f](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-334-320.jpg)
![335
Dump the EMP2 block (Partial)
tab 0, row 1, @0x1f36
tl: 39 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 50 23
col 1: [ 6] 4d 49 4c 4c 45 52 M I L L E R
col 2: [ 5] 43 4c 45 52 4b
col 3: [ 3] c2 4e 53
col 4: [ 7] 77 b6 01 17 01 01 01
col 5: [ 2] c2 0e
col 6: *NULL*
col 7: [ 2] c1 0b
end_of_block_dump](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-335-320.jpg)








![344
Dump the UNDO Block (Partial)
********************************************************************************
UNDO BLK:
xid: 0x0004.02a.000012ff seq: 0xa9e cnt: 0x7 irb: 0x7 icl: 0x0 flg: 0x0000
...
Rec #0x7 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: …
uba: 0x00800353.0a9e.04 ctl max scn: 0x0000.00432655 prv tx scn: 0x0000.00432656
txn start scn: scn: 0x0000.00432731 logon user: 0
prev brb: 8389454 prev bcl: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
op: Z
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0040e1d2 hdba: 0x0040e1d1
itli: 2 ispac: 0 maxfr: 4863
tabn: 0 slot: 1(0x1) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 1
col 1: [ 6] 4d 49 4c 4c 45 52 Here‟s the UNDO: M I L L E R](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-344-320.jpg)


![347
Dump the UNDO Block (Partial)
********************************************************************************
UNDO BLK:
xid: 0x0004.02a.000012ff seq: 0xa9e cnt: 0x7 irb: 0x7 icl: 0x0 flg: 0x0000
...
* Rec #0x7 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: 0(0x00000000)
*-----------------------------
uba: 0x00800353.0a9e.04 ctl max scn: 0x0000.00432655 prv tx scn: 0x0000.00432656
txn start scn: scn: 0x0000.00432731 logon user: 0
KDO undo record:
KTB Redo
...
col 1: [ 6] 4d 49 4c 4c 45 52 UNDO RECORD: M I L L E R
* Rec #0x8 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: 0(0x00000000)
*-----------------------------
KDO undo record:
KTB Redo
op: C uba: 0x00800353.0a9e.07
...
col 1: [ 5] 41 4c 4c 45 4e UNDO RECORD: A L L E N
End dump data blocks tsn: 1 file#: 2 minblk 851 maxblk 851](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-347-320.jpg)








![356
Bitmap Indexes
row#0[8010] flag: ---D-, lock: 2
col 0; len 1; (1): 31
col 1; len 6; (6): 02 40 2d 60 00 00
col 2; len 6; (6): 02 40 2d 60 00 07
col 3; len 1; (1): 00
row#1[7989] flag: ---D-, lock: 2
col 0; len 1; (1): 31
col 1; len 6; (6): 02 40 2d 60 00 00
col 2; len 6; (6): 02 40 2d 60 00 07
col 3; len 2; (2): c8 03
row#2[7968] flag: -----, lock: 2
col 0; len 1; (1): 31
col 1; len 6; (6): 02 40 2d 60 00 00
col 2; len 6; (6): 02 40 2d 60 00 07
col 3; len 2; (2): c8 07
Indexed value consist of 5 lines:
row#0: Row identification
col 0: Indexed value - length in hex.
col 1: Rowid for the first occurrence
of the indexed value.
col 2: Rowid for the last occurrence
of the indexed value
col 3: Actual bitmap which will have
1 where value occurred in range
between first and last rowid,
otherwise 0 in swap byte
notification, first byte usually cx
where x in (8,…,f). When all slots
for cf filled, new segment starts.
Oracle engine will place a lock on
blocks containing indexed value.](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-356-320.jpg)
![357
Insert 64 records / Dump is taken:
row#0[8008] flag: -----, lock: 0
col 0; len 1; (1): 31
col 1; len 6; (6): 02 40 2d 60 00 00
col 2; len 6; (6): 02 40 2d 60 00 3f
col 3; len 9; (9): cf ff ff ff ff ff ff ff ff
Another insert:
row#0[8007] flag: -----, lock: 0
col 0; len 1; (1): 31
col 1; len 6; (6): 02 40 2d 60 00 00
col 2; len 6; (6): 02 40 2d 60 00 40
col 3; len 10; (10): cf ff ff ff ff ff ff ff ff 00
Bitmap Indexes](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-357-320.jpg)
































![391
Node being Evicted NOT
Lack of CPU... Interconnect Failure
Log Files:
$CRS_HOME/log/inst1/cssd/ocssd.log - node 1
$CRS_HOME/log/inst2/cssd/ocssd.log - node 2
If you look at the log file on node 1, which was the master node at that time, you will see :
[ CSSD]2007... >WARNING: clssnmPollingThread: node inst2 (2) at 50% heartbeat fatal, eviction in 29.730 seconds
[ CSSD]2007... >WARNING: clssnmPollingThread: node inst2 (2) at 75% heartbeat fatal, eviction in 14.710 seconds
[ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 5.690 seconds
[ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 4.690 seconds
[ CSSD]2007...>TRACE: clssnmPollingThread: node inst2 (2) is impending reconfig
[ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 3.680 seconds
[ CSSD]2007...>TRACE: clssnmPollingThread: diskTimeout set to (57000)ms impending reconfig status(1)
...etc
[ CSSD]2007...>TRACE: clssnmReadDskHeartbeat: node(2) is down. rcfg(17) ...Disk lastSeqNo(1038569)
[ CSSD]2007...>TRACE: clssnmCheckDskInfo: node(2) disk HB found, network state 0, disk state(3) misstime(770)
[ CSSD]2007...>TRACE: clssnmReadDskHeartbeat: node(2) is down. rcfg(17) ... Disk lastSeqNo(1038570)
[ CSSD]2007...>TRACE: clssnmCheckDskInfo: node(2) misstime(760) state(0). Smaller(1) cluster node 2. mine is 3. (2/1)
[ CSSD]2007...>TRACE: clssnmEvict: Start
[ CSSD]2007...>TRACE: clssnmEvict: Evicting node 2, birth 10, death 17, killme 1
[ CSSD]2007...>TRACE: clssnmEvict: Evicting Node(2), timeout(190)](https://image.slidesharecdn.com/ohio11gridkramerpresent-240712205019-a471671f/85/ohio11_grid_kramer_present-pdf-Statspack-391-320.jpg)































ohio11_grid_kramer_present.pdf Statspack
- 1. 1 Rich Niemiec (rich@tusc.com), Rolta TUSC (www.rolta.com www.tusc.com) (Thanks: Sridhar Avantsa, Mark Komine, Andy Mendelsohn, Debbie Migliore, Maria Colgan, Kamal Talukder. Steven Tyler, Roger Daltrey, Joe Perry, Aerosmith) Oracle Disclaimer: The following is intended to outline Oracle's general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle's products remains at the sole discretion of Oracle. Oracle Database 11g Best New Features, Grid Tuning, Block Level Tuning Ohio 2011
- 2. 2 Audience Knowledge • Oracle9i Experience ? • Oracle9i RAC Experience? • Oracle10g Experience? • Oracle Database 11g Experience? • Goals – Tuning Tips including block level & AWR / Grid Tuning – Focus on a few nice features of Oracle 10g & 11g • Non-Goals – Learn ALL aspects of Tuning Oracle
- 3. What if Kramer was your DBA & Seinfeld Tuned your Database? “Jerry, I can‟t find my backup”
- 4. 4 Overview • Kramer‟s missing Backup • George‟s Untuned System • Elaine‟s Untouched System • Jerry‟s Perfect Tuning Plan • Statspack / AWR – Top Waits – Load Profile – Latch Waits – Top SQL – Instance Activity – File I/O • The Future: EM & ADDM • 11g New Features • Helpful Block Level, V$/X$ /(Mutexes) • Summary
- 5. 5 Kramer doesn‟t have a Backup My Junior DBA is getting the backup right now!
- 6. 6 What Kramer did... • He was logged into production vs. test • He deleted some production data • His backup tape was at Jerry‟s apartment • He taped a Lady Gaga song over the backup tape. • He never actually tested the backup so the older backup tapes don‟t work either • He doesn‟t have a DR site
- 7. 7 Jerry reminds Kramer what he could have done to prevent all of this... • The backup should have been in a secure location • With 10g or 11g encrypt the backup so it will always be protected • Could have used Oracle‟s Flashback and get deleted data back • Data Guard allows you to fail over to a new sight. • Test your recovery & DR to ensure it will work
- 8. 8 Jerry reminds Kramer what he could have done to prevent all of this... • Just because a database may need to be recovered, do not delete the "corrupted" database if possible. – First, take a backup taken of the "corrupt" database. – If the restore does not work and you did not backup the "corrupt" database, you may have nothing to work with. • When trouble shooting a problem query never let operations reboot the instance. • Never startup a standby database in normal mode. • Never apply catpatch to a standby database. Only run the catpatch on the primary.
- 9. 9 How to avoid this mistake... • Kramer could have ensured that he never made this mistake in the first place by setting up his prompt to show exactly where he was. For unix/linux, put in your .profile, or .bash_profile. If using the bash shell: export PS1="[$(whoami)@$(hostname)]$ “ For sqlplus, it is the sqlprompt setting: MIKE6:system:mike61> show sqlp sqlprompt "MIKE6:system:mike61> " It is setup in a sqlplus admin file: [oracle@mikek5 oracle]$ tail -2 $ORACLE_HOME/sqlplus/admin/glogin.sql set sqlprompt "_user 'at' _connect_identifier> "
- 10. 10 George Doesn‟t Tune Anything Instead of proactively tuning are you depending on other means to save you?
- 11. 11 George doesn‟t Tune Anything... • George doesn‟t believe in backups; It slows down the system. • He uses the “kill -9” for anything slow • George doesn‟t patch things especially security • He uses default passwords for speed and so he doesn‟t have to change any application code. • He tries not to do anything that requires actual work to be done • He never tells anyone that he‟s going to bring down the system, he just does a “oops, it crashed” with a Shutdown Abort when he needs to bring it down.
- 12. 12 Jerry‟s Advice to George... • Default passwords should be changed at database creation time. • Good design beats ad-hoc design. – Don't work in a black box when tuning. – Establish priorities and work on what is important to the business. – Set goals so that everyone knows if success is achieved. • Setting production databases in noarchivelog mode and then relying on exports or cold backups. – No way to recover lost data if crash occurs after the backups. – Recommend turning archivelog mode ON and use RMAN or hot backups instead. – Need to validate, test & regularly review backup & DR plans • Installing Oracle Enterprise Edition downloaded from technet.oracle.com and not buying any Oracle Support can be a problem. You can't really patch this.
- 13. 13 Jerry‟s Advice to George... • In George‟s system you might find alert log, trace files, or reports from end users of errors that have been occurring for a long time but were not addressed. Then the problem either grew into something larger or due to changes in the business these issues grow into something much larger. • Cleanup is not occurring on destination directories (bdump, cdump, udump, adump). • Leaves temp to grow a ridiculously huge size. This just trains the developers to write un-optimized queries. • NEVER go without a development environment • George also never tests anything. How times have we been called in to fix in a production environment that would have been caught and corrected BEFORE they were a production problem if only some basic testing had been done?
- 14. 14 11g changes … fyi only… When you specify the ORACLE_BASE environment variable during install, Oracle also uses this value to set the DIAGNOSTIC_DEST (required for upgrade from previous version) parameter which includes all ADR directories (alert, trace, incident, cdump, hm (health monitor) etc.). As of Oracle11gR1, the CORE_DUMP_DEST, BACKGROUND_DUMP_DEST, and USER_DUMP_DEST are replaced with DIAGNOSTIC_DEST. In the following output, ORACLE_BASE is set to u01/app/oracle and DIAGNOSTIC_DEST is set to /u01/app/oracle/diag:
- 15. 15 Query V$DIAG_INFO in 11g select name, value from v$diag_info; NAME VALUE ---------------------- ----------------------------------------------- Diag Enabled TRUE ADR Base /u01/app/oracle ADR Home /u01/app/oracle/diag/rdbms/o11gb/O11gb Diag Trace /u01/app/oracle/diag/rdbms/o11gb/O11gb/trace Diag Alert /u01/app/oracle/diag/rdbms/o11gb/O11gb/alert Diag Incident /u01/app/oracle/diag/rdbms/o11gb/O11gb/incident Diag Cdump /u01/app/oracle/diag/rdbms/o11gb/O11gb/cdump Health Monitor /u01/app/oracle/diag/rdbms/o11gb/O11gb/hm Default Trace File /u01/app/oracle/diag/rdbms/o11gb/O11gb/trace/O11gb_ora_17776.trc Active Problem Count 0 Active Incident Count 0 11 rows selected.
- 16. 16 Elaine Doesn‟t Work past 5 PM Are you available when they need you? When you are available, are you easy to deal with?
- 17. 17 Elaine doesn‟t Work past 5 PM... • Elaine doesn‟t understand the concept of the DBA. • She doesn‟t understand the dedication needed • If users have a problem after 5 PM, they wait until tomorrow for a solution. • Elaine doesn‟t have the time each day to do the required maintenance tasks needed • Elaine really wants to be (and should be) an Ad-hoc query user, but wants the salary of a DBA. • She advises others to never accept a job as DBA, you can never escape!!! She advises other DBAs to never give out home#/pager/cell number to developers...
- 18. 18 Jerry‟s Advice to Elaine... • Don‟t set the max_dump_file_size set to the default (unlimited). Can take over file system if trace generated is bigger than the destination. Can set this in K, M, or G. • Don‟t use Oracle 8i/9i settings in a 10g or 11g instance. Take advantage of new features and get rid of backward compatibility kernel settings. • She has RAC, but has no redundancy on the private interconnect. Having the private interconnect compete with other public network traffic is a bad thing. • NEVER apply a patch without testing in development first • NEVER move code into production without test in development
- 19. 19 Jerry‟s Advice to Elaine... • ALWAYS document your environment, changes to the environment, and custom code – this makes life easier for those of us who have to support it • Her datafiles are set to autoextend unlimited. Then you find out that the file systems they reside on are limited. An Oracle Error is triggered when Oracle tries to resize and can't find the space. Clients do this all the time because they rely on DBCA. • Don‟t rely on the UNIX administrator‟s word that the filesystems underneath are I/O tuned. A good DBA should actually do the LUN recommendation, i.e. R1+0 for Oracle, R5 for backups, etc. Check File I/O for issues.
- 20. 20 Jerry is the Productive DBA Can you stay up 63 hours? You won‟t need to in the future!
- 21. 21 Jerry‟s Secret to Tuning; AWR Report and Grid Control • Jerry is the Master Tuning Expert • He Knows The Oracle • He Leverages what he learned in Statspack • He Learned what‟s new in AWR Report • He applies his tuning skills to Grid Control • He Pro-actively tunes to head off problems • He Re-actively tunes when needed • He lets Grid Control Tune for him • He‟s put his knowledge into Grid Control so that he can be more productive. He‟s running Exadata!
- 22. Know the Oracle
- 23. 23 Oracle Firsts – Innovation! 1979 First commercial SQL relational database management system 1983 First 32-bit mode RDBMS 1984 First database with read consistency 1987 First client-server database 1994 First commercial and multilevel secure database evaluations 1995 First 64-bit mode RDBMS 1996 First to break the 30,000 TPC-C barrier 1997 First Web database 1998 First Database - Native Java Support; Breaks 100,000 TPC-C 1998 First Commercial RDBMS ported to Linux 2000 First database with XML 2001 First middle-tier database cache 2001 First RDBMS with Real Application Clusters 2004 First True Grid Database 2005 First FREE Oracle Database (10g Express Edition) 2006 First Oracle Support for LINUX Offering 2007 Oracle 11g Released! 2008 Oracle Exadata Server Announced (Oracle buys BEA) 2009 Oracle buys Sun – Java; MySQL; Solaris; Hardware; OpenOffice 2010 Oracle announces MySQL Cluster 7.1, Exadata V2-8, Exalogic 2011 Storage Expansion Rack, Database Appliance, SPARC SuperCluster T4-4
- 24. 24 • The Focus has been Acquisitions and gaining Market Share • Oracle 11g Database extends an already large lead – Easier to Manage the Database – Better Grid Control – Self Tuning through a variety of tools (Makes 1 person equal 10) – Better Security/Encryption & Recoverability via Flashback – Better Testing Tools (Real Application Testing) • Andy Mendelsohn is still the database lead • Releases of Siebel, PeopleSoft, JDE and Oracle12 Apps. • New Oracle BI Suite & Acquisition of Hyperion • Acquisition of BEA, SUN In 2007: Version 11g was Released
- 25. 25 Oracle gets Sun: Java, MySQL, Solaris, OpenOffice, Hardware, Storage Tech
- 26. 26 Oracle Setting the Rules!
- 27. 27 Tuning - Leverage ALL of your Knowledge Do Developers think of this when they think of their Data
- 28. 28 Tuning in General • Both an Art and a Science – You make miracles! • Exceptions often rule the day…Not a “one size fits all” • Hardware & Architecture must be right for your application or it will be difficult to succeed. • Enterprise Manager (also 3rd party products) are best for simple tuning and ongoing maintenance. • V$/X$ are best for drilling deep into problems • 11g Enterprise Manager radically makes you better!
- 29. 29 Grid Control: Run the AWR Report (Many examples follow referencing this)
- 30. 30 Check Regularly 1. Top 5 wait events 2. Load Profile 3. Instance Efficiency Hit Ratios 4. Wait Events 5. Latch Waits 6. Top SQL 7. Instance Activity 8. File I/O 9. Memory Allocation 10. Undo
- 31. 31 AWR – Load Profile
- 32. 32 AWR – Waits / Instance Efficiency
- 33. 33 Statspack (old/free way) – Top 5 Wait Events (Top is 3T) Top 5 Timed Events ~~~~~~~~~~~~~~~~~~ % Total Event Waits Time (s) Ela Time --------------------------- ------------ ----------- -------- db file sequential read 399,394,399 2,562,115 52.26 CPU time 960,825 19.60 buffer busy waits 122,302,412 540,757 11.03 PL/SQL lock timer 4,077 243,056 4.96 log file switch 188,701 187,648 3.83 (checkpoint incomplete)
- 34. 34 Top Wait Events Things to look for… Wait Problem Potential Fix Sequential Read Indicates many index reads – tune the code (especially joins); Faster I/O; Don‟t over index or overuse indexes. Scattered Read Indicates many full table scans–index, tune the code; cache small tables; Faster I/O Free Buffer Increase the DB_CACHE_SIZE; shorten the checkpoint; tune the code to get less dirty blocks, faster I/O, use multiple DBWR‟s. Buffer Busy Segment Header – Add freelists (if inserts) or freelist groups (esp. RAC). Use ASSM.
- 35. 35 Statspack - Top Wait Events Things to look for… Wait Problem Potential Fix Buffer Busy Data Block – Separate „hot‟ data; potentially use reverse key indexes; fix queries to reduce the blocks popularity, use smaller blocks, I/O, Increase initrans and/or maxtrans (this one‟s debatable) Reduce records per block. Buffer Busy Undo Header – Add segments or increase size of segment area (auto undo) Buffer Busy Undo block – Commit more (not too much) Larger segments/area. Try to fix the SQL.
- 36. 36 Statspack - Top Wait Events Things to look for… Wait Problem Potential Fix Enqueue - ST Use LMT‟s or pre-allocate large extents Enqueue - HW Pre-allocate extents above HW (high water mark.) Enqueue – TX Increase initrans and/or maxtrans (TX4) on (transaction) the table or index. Fix locking issues if TX6. Bitmap (TX4) & Duplicates in Index (TX4). Enqueue - TM Index foreign keys; Check application (trans. mgmt.) locking of tables. DML Locks.
- 37. 37 Transactions Moving through Oracle: ITL & Undo Blocks Why INITRANS Matter!
- 38. 38 User 1 – Updates Row# 1&2 User 3 updates Row 3 (There are also In Memory Updates (IMU) in 11g) • User1 updates a row with an insert/update/delete – an ITL is opened and xid tracks it in the data block. • The xid ties to the UNDO header block which ties to the UNDO data block for undo. • If user2 wants to query the row, they create a clone and rollback the transaction going to the undo header and undo block. • If user3 wants to update same row (they wait). If user 3 wants to update different row then they open a second ITL with an xid that maps to an undo header that maps to an undo block. Cache Layer 2 Transaction Layer XID 01 XID 02 2 Row 3 1 Row 1 1 Row 2 Lock Byte ITL 1 ITL 2 User1 Request User3 Request XID 02 ITL 2 Row 3 2 Row 3
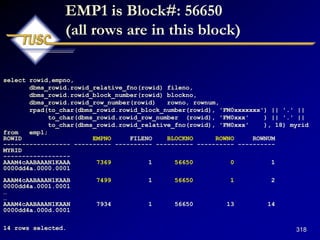
- 39. Log Buffers (Chain Latch) n 1 2 3 Shared Pool SGA Cache Buffers Buffer Cache Buffer Header Hash Buckets Only ONE block on the Hash Chain! Only 1 user - EMP1 buffer header (So far it‟s clean and only 1 copy)
- 40. 40 Let‟s watch the EMP1 buffer header (So far it‟s clean and only 1 copy) select lrba_seq, state, dbarfil, dbablk, tch, flag, hscn_bas,cr_scn_bas, decode(bitand(flag,1), 0, 'N', 'Y') dirty, /* Dirty bit */ decode(bitand(flag,16), 0, 'N', 'Y') temp, /* temporary bit */ decode(bitand(flag,1536), 0, 'N', 'Y') ping, /* ping (to shared or null) bit */ decode(bitand(flag,16384), 0, 'N', 'Y') stale, /* stale bit */ decode(bitand(flag,65536), 0, 'N', 'Y') direct, /* direct access bit */ decode(bitand(flag,1048576), 0, 'N', 'Y') new /* new bit */ from x$bh where dbablk = 56650 order by dbablk; LRBA_SEQ STATE DBARFIL DBABLK TCH FLAG HSCN_BAS ---------- ---------- ---------- ---------- ---------- ---------- ---------- CR_SCN_BAS D T P S D N ---------- - - - - - - 0 1 1 56650 0 35659776 4294967295 0 N N N N N N
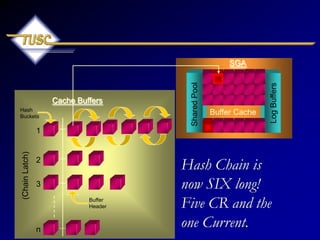
- 41. Log Buffers (Chain Latch) n 1 2 3 Shared Pool SGA Cache Buffers Buffer Cache Buffer Header Hash Buckets Hash Chain is now SIX long! Five CR and the one Current. Many Users inserting/querying (Many versions of the block)
- 42. 42 Insert in 6 other sessions & drive x$bh up to the max of 6 versions of block LRBA_SEQ STATE DBARFIL DBABLK TCH FLAG HSCN_BAS ---------- ---------- ---------- ---------- ---------- ---------- ---------- CR_SCN_BAS D T P S D N ---------- - - - - - - 0 3 1 56650 1 524416 0 4350120 N N N N N N 0 3 1 56650 1 524416 0 4350105 N N N N N N 365 1 1 56650 7 33562633 4350121 0 Y N N N N N 0 3 1 56650 1 524416 0 4350103 N N N N N N 0 3 1 56650 1 524416 0 4350089 N N N N N N 0 3 1 56650 1 524288 0 4350087 N N N N N N
- 43. 43 Why only 6 versions of a Block? (more on this later…) select a.ksppinm, b.ksppstvl, b.ksppstdf, a.ksppdesc from x$ksppi a, x$ksppcv b where a.indx = b.indx and substr(ksppinm,1,1) = '_' and ksppinm like '%&1%' order by ksppinm; KSPPINM ------------------------------------------------------------------------------- KSPPSTVL ------------------------------------------------------------------------------- KSPPSTDF --------- KSPPDESC ------------------------------------------------------------------------------- _db_block_max_cr_dba 6 TRUE Maximum Allowed Number of CR buffers per dba
- 44. 44 AWR – ITL Issues
- 45. 45 What are you Waiting on? Is this your Ad-Hoc Query User or Network Administrator?
- 46. 46 Statspack – Top 25 • Tuning the top 25 buffer get and top 25 physical get queries has yielded system performance gains of anywhere from 5 percent to 5000 percent. • The SQL section of the statspack report tells you which queries to potentially tune first. • The top 10 of your SQL statements should usually not be more than 10 percent of your buffer gets or disk reads.
- 47. 47 Statspack – Top SQL (Top 2 are 5T & 3T of reads!!) Buffer Gets Executions Gets per Exec %Total Time(s) Time (s) Hash Value --------------- ------------ -------------- ------ ------- -------- 627,226,570 117 5,360,910.9 4.7 9627.09 10367.04 Module: JDBC Thin Client SELECT * FROM (select d1.tablespace_name, d1.owner, d1.segment_t ype, d1.segment_name, d1.header_file, d1.extents, d1.bytes, d1.b locks, d1.max_extents , d1.next_extent from sys.dba_segments d1 where d1.segment_type != 'CACHE' and tablespace_name not in (s elect distinct tablespace_name from sys.dba_rollback_segs) orde 409,240,446 175,418 2,332.9 3.1 ####### 59430.83 Module: ? @sap10ci (TNS V1-V3) SELECT "TABNAME" , "VARKEY" , "DATALN" , "VARDATA" FROM "KAPOL" WHERE "TABNAME" = :A0 AND "VARKEY" LIKE :A1 ORDER BY "TABNAME" , "VARKEY"
- 48. 48 AWR – Top SQL (Top 1 is 2T – Second one only 250M)
- 49. 49 Statspack - Latch Waits Latch Free – Latches are low-level queueing mechanisms (they‟re accurately referred to as mutually exclusion mechanisms) used to protect shared memory structures in the System Global Area (SGA). • Latches are like locks on memory that are very quickly obtained and released. • Latches are used to prevent concurrent access to a shared memory structure. • If the latch is not available, a latch free miss is recorded.
- 50. 50 New in 11g – Mutexes • Oracle uses mutexes (mutual exclusion) instead of library cache latches and library cache pin latches to protect objects. We still have the shared pool latch. • A mutex requires less memory space and fewer instructions. • Mutexes take advantage of CPU architecture that has “compare and swap” instructions. • With a mutex, if I have the resource and you can‟t get it after trying a specified number of times (spins), you sleep and try again a very short time later • In 10g Oracle used mutexes for pins: you could use the undocumented parameter: _kks_use_mutex_pin=false (not in 11g).
- 51. 51 “Cursor: Pin S”: related Bugs and when fixed in Oracle 10g, 11g & 12 (future version) NBBug Fixed Description 9499302 11.1.0.7.7, 11.2.0.2, 12.1.0.0 Improve concurrent mutex request handling 9591812 11.2.0.2.2, 12.1.0.0 Wrong wait events in 11.2 ("cursor: mutex S" instead of "cursor: mutex X") 6904068 11.2.0.2 High CPU usage when there are "cursor: pin S" waits (Windows – fixed 11.2.0.2) 7441165 10.2.0.5/11.2.0.2 Prevent preemption while holding a mutex (fix only works on Solaris) 88575526 10.2.0.4, 11.1.0.7 Session spins / OERI after 'kksfbc child completion' wait – (Windows only)
- 52. 52 Statspack – Latch/Mutex Waits – fyi Much better in 11g!! Latch Free – • Most latch problems are related to: – The failure to use bind variables: library cache mutex (latch in 10g) – Slow redo log disks or contention (log file sync) – Buffer cache contention issues (cache buffers lru chain) – Hot blocks in the buffer cache (cache buffers chains). • There are also latch waits related to bugs; check Support for bug reports if you suspect this is the case (oracle.com/support). • When latch miss ratios are greater than 0.5 percent, you should investigate the issue. • In memory updates have changed things for the better!
- 53. 53 Statspack - Latch Waits - fyi Latch Activity for DB: ORA9I Instance: ora9i Snaps: 1 -2 Pct Avg Wait Pct Get Get Slps Time NoWait NoWait Latch Requests Miss /Miss (s) Requests Miss ------------------------ -------------- ------ ------ ------ ------------ ------ KCL freelist latch 4,924 0.0 0 cache buffer handles 968,992 0.0 0.0 0 cache buffers chains 761,708,539 0.0 0.4 21,519,841 0.0 cache buffers lru chain 8,111,269 0.1 0.8 19,834,466 0.1 library cache 67,602,665 2.2 2.0 213,590 0.8 redo allocation 12,446,986 0.2 0.0 0 redo copy 320 0.0 10,335,430 0.1 user lock 1,973 0.3 1.2 0
- 54. 54 Cursor Sharing - 8.1.6+ If v$sqlarea looks like this: select empno from rich778 where empno =451572 select empno from rich778 where empno =451573 select empno from rich778 where empno =451574 select empno from rich778 where empno =451575 select empno from rich778 where empno =451576 Use cursor_sharing=force (sqlarea goes to this): select empno from rich778 where empno =:SYS_B_0
- 55. 55 Mutex waits… • A “pin” is when a session wants to re-execute a statement that‟s in the library cache. • Cursor: “Pin S wait on X mutex”; the session needs a mutex in share mode on a resource and someone has it in exclusive mode. • The library cache mutex serializes access to objects in the library cache. Every time a SQL or PL/SQL procedure, package, function, or trigger is executed, this library cache mutex is used to search the shared pool for the exact statement so that it can be reused. • Shared pool latch / library cache mutex issues occur when space is needed in the library cache (loads with library cache load latch) • You can also investigate the views V$MUTEX_SLEEP and V$MUTEX_SLEEP_HISTORY for more information.
- 56. 56 Instance Activity – AWR/Statspack Statistic Total per Second per Trans --------------------------------- ------------------ -------------- ---------- branch node splits 7,162 0.1 0.0 consistent gets 12,931,850,777 152,858.8 3,969.5 current blocks converted for CR 75,709 0.9 0.0 db block changes 343,632,442 4,061.9 105.5 db block gets 390,323,754 4,613.8 119.8 hot buffers moved to head of LRU 197,262,394 2,331.7 60.6 leaf node 90-10 splits 26,429 0.3 0.0 leaf node splits 840,436 9.9 0.3 logons cumulative 21,369 0.3 0.0 physical reads 504,643,275 5,965.1 154.9 physical writes 49,724,268 587.8 15.3 session logical reads 13,322,170,917 157,472.5 4,089.4 sorts (disk) 4,132 0.1 0.0 sorts (memory) 7,938,085 93.8 2.4 sorts (rows) 906,207,041 10,711.7 278.2 table fetch continued row 25,506,365 301.5 7.8 table scans (long tables) 111 0.0 0.0 table scans (short tables) 1,543,085 18.2 0.5
- 57. 57 Instance Activity Terminology… - fyi only Statistic Description Session Logical Reads All reads cached in memory. Includes both consistent gets and also the db block gets. Consistent Gets These are the reads of a block that are in the cache. They are NOT to be confused with consistent read (cr) version of a block in the buffer cache (usually the current version is read). Db block gets These are block gotten to be changed. MUST be the CURRENT block and not a CR block. Db block changes These are the db block gets (above) that were actually changed. Physical Reads Blocks not read from the cache. Either from disk, disk cache or O/S cache; there are also physical reads direct which bypass cache using Parallel Query (not in hit ratios).
- 58. 58 File I/O Tablespace ------------------------------ Av Av Av Av Buffer Av Buf Reads Reads/s Rd(ms) Blks/Rd Writes Writes/s Waits Wt(ms) -------------- ------- ------ ------- ------------ -------- ---------- ------ PSAPSTABI 14,441,749 171 7.9 1.0 521,275 6 1,234,608 6.2 PSAPVBAPD 13,639,443 161 6.2 1.7 10,057 0 2,672,470 4.2 PSAPEDII 11,992,418 142 5.3 1.0 83,757 1 4,115,714 4.4 PSAPEDID 10,617,042 125 8.1 1.0 64,866 1 3,728,009 6.4 PSAPROLL 998,328 12 13.2 1.0 8,321,252 98 285,060 65.7 • Reads should be below 14ms
- 59. 59 AWR – File I/O
- 60. 60 11g New Features & Grid Control
- 61. Testing the Future Version Version 11.1.0.6.0 of the Database Version 11.2.0.1.0 of the Database for Release 2 Examples
- 62. 62 Oracle Database 11g Release 1: Upgrade Paths Source Database Target Database 9.2.0.4.0 (or higher) 11.1.x 10.1.0.2.0 (or higher) 11.1.x 10.2.0.1.0 (or higher) 11.1.x Source Database Upgrade Path for Target Database Target Database 7.3.3.0.0 (or lower) 7.3.4.x --> 9.2.0.8 11.1.x 8.0.5.0.0 (or lower) 8.0.6.x --> 9.2.0.8 11.1.x 8.1.7.0.0 (or lower) 8.1.7.4 --> 9.2.0.8 11.1.x 9.0.1.3.0 (or lower) 9.0.1.4 --> 9.2.0.8 11.1.x Direct Upgrade Path In-Direct Upgrade Path
- 63. 63 Database Upgrade Assistant (DBUA) • Command Line Option to Auto Extend System Files • Express Edition Upgrade to others • Integration with Oracle Database 11g Pre- upgrade Tool • Moving Data Files into ASM, SAN, and Other File Systems • Oracle Base and Diagnostic Destination Configuration
- 64. 64 Database Upgrade Assistant (DBUA) • DBUA checks before the upgrade: • Invalid user accounts or roles • Invalid data types or invalid objects • De-supported character sets • Adequate resources (rollback segments, tablespaces, and free disk space) • Missing SQL scripts needed for the upgrade • Listener running (if Oracle Enterprise Manager Database Control upgrade or configuration is requested) • Oracle Database software linked with Database Vault option. If Database Vault is enabled, Disable Database Vault before upgrade.
- 65. 65 The New Version – Life is Good! $ sqlplus ***/*** SQL*Plus: Release 11.1.0.6.0 - Production on Tue Oct 30 11:21:04 2007 Copyright (c) 1982, 2007, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL> startup ORACLE instance started. Total System Global Area 422670336 bytes Fixed Size 1300352 bytes Variable Size 306186368 bytes Database Buffers 109051904 bytes Redo Buffers 6131712 bytes Database mounted. Database opened.
- 66. 66 Or... Use 11g EM...
- 67. 67 Database Information - UP! 11gR1 Monitor Database (UP) Users are Definitely Using it! We have an alert – we logged on as SYS
- 68. 68 Database Information - UP! 11gR2 Monitor Database (UP) Users are Using it! Click on the HA Console Restart Enabled (Restart Database, ASM, Listener after restart of Software/Hardware)
- 69. 69 Database Information - UP! High Availability Console - 11gR2 Events that are an issue Flash Recovery Usage
- 71. 71 Automatic Memory Management (AMM) MEMORY_TARGET in 11g • First there was some Automatic Memory Mgmt - 9i – SGA_MAX_SIZE introduced in 9i – Dynamic Memory – No more Buffers – DB_CACHE_SIZE – Granule sizes introduced - _ksm_granule_size • Then came SGA_TARGET – 10g – Oracle Applications recommends setting this for SGA – Set minimums for key values (Data Cache / Shared Pool) • Now there is MEMORY_TARGET – 11g – SGA + PGA all in one setting; Still set minimums
- 72. 72 SGA & PGA will be MEMORY_TARGET
- 73. 73 Automatically sized SGA Components that Use SGA_TARGET Component Initialization Parameter Fixed SGA None Shared Pool SHARED_POOL_SIZE Large Pool LARGE_POOL_SIZE Java Pool JAVA_POOL_SIZE Buffer Cache DB_CACHE_SIZE Streams Pool STREAMS_POOL_SIZE
- 74. 74 Manually Sized SGA Components that Use SGA_TARGET Component Initialization Parameter Log buffer LOG_BUFFER (pfile only in 10g) Keep Pool DB_KEEP_CACHE_SIZE Recycle Pool DB_RECYCLE_CACHE_SIZE Block caches DB_nK_CACHE_SIZE Program Global Area (now in MEMORY_TARGET): Aggregate PGA PGA_AGGREGATE_TARGET
- 75. 75 Moving from SGA_TARGET to: MEMORY_TARGET SQL> sho parameter target NAME TYPE VALUE ------------------------------------ ------------- ------------------------------ memory_max_target big integer 0 memory_target big integer 0 pga_aggregate_target big integer 110M sga_target big integer 250M
- 76. 76 Moving from SGA_TARGET to: MEMORY_TARGET ALTER SYSTEM SET MEMORY_MAX_TARGET=360M SCOPE=SPFILE; (shutdown/startup) ALTER SYSTEM SET MEMORY_TARGET=360M SCOPE=SPFILE; ALTER SYSTEM SET SGA_TARGET=0; (or set a minimum) ALTER SYSTEM SET PGA_AGGREGATE_TARGET=0; (or set a minimum) SQL> sho parameter target NAME TYPE VALUE ------------------------------------ ------------- ------------------------------ memory_max_target big integer 360M memory_target big integer 360M pga_aggregate_target big integer 0 sga_target big integer 0
- 77. 77 Moving from SGA_TARGET to: MEMORY_TARGET (set minimums) ALTER SYSTEM SET SGA_TARGET=200M; ALTER SYSTEM SET PGA_AGGREGATE_TARGET=100M; SQL> sho parameter target NAME TYPE VALUE ------------------------------------ ------------- ------------------------------ memory_max_target big integer 360M memory_target big integer 360M pga_aggregate_target big integer 100M sga_target big integer 200M
- 78. 78 Moving from SGA_TARGET to: MEMORY_TARGET - EM
- 79. Buffer Cache & Result Cache
- 80. 80 First, A quick review: Flush Buffer Cache • The new 10g feature allows the flush of the buffer cache. It is NOT intended for production use, but rather for system testing purposes. • This can help you in your tuning needs or as a band-aid if you have „free buffer‟ waits (there are better ways to fix this like writing more often or increasing the DB_CACHE_SIZE) • Note that any Oracle I/O not done in the SGA counts as a physical I/O. If your system has O/S caching or disk caching, the actual I/O that shows up as physical may indeed be a memory read outside of Oracle. • To flush the buffer cache perform the following: SQL> ALTER SYSTEM FLUSH BUFFER_CACHE;
- 81. 81 Flush Buffer Cache Example select count(*) from tab1; COUNT(*) ----------------- 1147 Execution Plan ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1) 1 0 SORT (AGGREGATE) 2 1 TABLE ACCESS (FULL) OF 'TAB1' (TABLE) (Cost=4 Card=1147) Statistics ---------------------------------------------------------- 0 db block gets 7 consistent gets 6 physical reads
- 82. 82 Flush Buffer Cache Example select count(*) from tab1; (Run it again and the physical reads go away) COUNT(*) ----------------- 1147 Execution Plan ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1) 1 0 SORT (AGGREGATE) 2 1 TABLE ACCESS (FULL) OF 'TAB1' (TABLE) (Cost=4 Card=1147) Statistics ---------------------------------------------------------- 0 db block gets 7 consistent gets 0 physical reads
- 83. 83 Flush Buffer Cache Example ALTER SYSTEM FLUSH BUFFER_CACHE; System altered. select count(*) from tab1; (Flush the cache and the physical reads are back) COUNT(*) ----------------- 1147 Execution Plan ----------------------------------------------------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1) 1 0 SORT (AGGREGATE) 2 1 TABLE ACCESS (FULL) OF 'TAB1' (TABLE) (Cost=4 Card=1147) Statistics ---------------------------------------------------------- 0 db block gets 7 consistent gets 6 physical reads
- 84. 84 The Result Cache • Function Results of queries and query fragments can be cached in memory for future executions. – Choose calculations that frequently run – Choose data that does NOT frequently change • RESULT_CACHE & RELIES_ON clauses • Takes its memory from the Shared Pool – Set with RESULT_CACHE_MAX_SIZE – RESULT_CACHE_MODE=force (auto/manual) • DBMS_RESULT_CACHE.FLUSH to clear • Is NOT passed between RAC/Grid nodes • Check the docs for other Restrictions & Rules!!
- 85. 85 Result Cache Performance Example Query (1M Row Test) select * from (select * from (select t.country_name, t.city_name, sum(t.salary) a_sum, max(t.salary) a_max from emps t group by t.country_name, t.city_name) order by a_max desc) where rownum < 2;
- 86. 86 Result Cache Example Performance Step 1 - In Session 1- Executed query without hint and it returned an elapsed time of 3.80 seconds (not cached). Step 2 - In Session 2 – Executed query without hint and it returned an elapsed time of 3.20 seconds (not cached).
- 87. 87 Result Cache Example Performance Step 3 - In Session 2 Executed query with the RESULT_CACHE hint and it returned an elapsed time of 3.18 seconds (cache it). Step 4 - In Session 1 Executed query without the RESULT_CACHE hint, but with RESULT_CACHE_MODE=force and it returned an elapsed time of 0.86 seconds (cached!!).
- 88. 88 Result Cache Example Query From the Oracle Docs • The RELIES_ON Clause specifies tables or views that the Function Results are dependent on. -- Package specification CREATE OR REPLACE PACKAGE HR IS ... type DeptInfoRec IS RECORD (avgSal NUMBER, numberEmployees NUMBER); -- Function declaration FUNCTION GetDeptInfo (dept_id NUMBER) RETURN DeptInfoRec RESULT_CACHE; ... END HR;
- 89. 89 Result Cache Example Query From the Oracle Docs PACKAGE BODY HR IS ... -- Function definition FUNCTION GetDeptInfo (dept_id NUMBER) RETURN DeptInfoRec RESULT_CACHE RELIES_ON (EMP); IS result DeptInfoRec; BEGIN SELECT AVG(sal), count(*) INTO result FROM EMP WHERE deptno = dept_id; RETURN result; END; ... END HR;
- 90. 90 The Result Cache – V$ Views • V$RESULT_CACHE_STATISTICS – Displays the amount of memory to help you determine memory currently allocated to the result cache. Other V$ views: • V$RESULT_CACHE_MEMORY • V$RESULT_CACHE_OBJECTS • V$RESULT_CACHE_DEPENDENCY
- 91. 91 The Result Cache – FYI Only Digging Deeper KSPPINM KSPPSTVL KSPPDESC -------------------------------------- -------- -------------------------------- _result_cache_auto_execution_threshold 1 result cache auto execution threshold _result_cache_auto_size_threshold 100 result cache auto max size allowed _result_cache_auto_time_threshold 1000 result cache auto time threshold _result_cache_block_size 1024 result cache block size _result_cache_bypass FALSE bypass the result cache _result_cache_hash_buckets 1024 hash bucket count _result_cache_invalid 0 post-invalidation usage allowance _result_cache_max_result 100 maximum result size as percent of cache size _result_cache_remote_expiration 0 maximum life time (min) for any result using a remote object _result_cache_timeout 60 maximum time (sec) a session
- 92. 92 Tuning Tools – FYI Only DBMS_XPLAN • Use DBMS_XPLAN to query the execution plan – Automatically queries the last plan in PLAN_TABLE – uses a TABLE() function with another pipelined function – Operation text truncation might be a problem – Will give additional information after plan • Highlight filter vs join conditions, if plan table is current • Displays warning message of old version plan table is being used – In 11g, a procedure for SQL Plan Baselines (we‟ll cover these later). DBMS_XPLAN.DISPLAY_SQL_PLAN_BASELINE ( sql_handle IN VARCHAR2 := NULL, plan_name IN VARCHAR2 := NULL, format IN VARCHAR2 := 'TYPICAL') <„BASIC‟/‟ALL‟> RETURN dbms_xplan_type_table;
- 93. 93 Tuning Tools – FYI Only DBMS_XPLAN DBMS_XPLAN Example: Select * from table (dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost | Pstart| Pstop | -------------------------------------------------------------------------------------- | 0 | UPDATE STATEMENT | | 328 | 2296 | 2 | | | | 1 | UPDATE | JOURNAL_LINE | | | | | | | 2 | PARTITION RANGE ALL| | | | | 1 | 4 | | 3 | TABLE ACCESS FULL | JOURNAL_LINE | 328 | 2296 | 2 | 1 | 4 | -------------------------------------------------------------------------------------- Note: cpu costing is off, 'PLAN_TABLE' is old version 11 rows selected
- 95. 95 The Virtual Column • The value of the virtual column is a derived expression. – Can be derived from columns of the same table or from constants – Can include SQL or user-defined PL/SQL functions • Virtual column DATA is NOT PHYSICALLY STORED. • You CAN NOT explicitly write to a virtual column • You CAN create a PHYSICAL index (result is function- based index) or partition on a virtual column <unlike a computed column in SQL Server or other databases> • If you UPDATE columns of a virtual column and it has an index, then it will be computed on the UPDATE vs. on the SELECT (very important from a tuning standpoint). • Index Organized and External Tables can NOT have virtual columns.
- 96. 96 The Virtual Column create table emp_rich (empno number(4), sal number(7,2), yearly_sal generated always as (sal*12), deptno number(2)); Table created. insert into emp_rich(empno, sal, deptno) select empno, sal, deptno from scott.emp; 14 rows created.
- 97. 97 The Virtual Column select * from emp_rich; EMPNO SAL YEARLY_SAL DEPTNO ------------ ----------- ------------------- ---------------- 7369 800 9600 20 7499 1600 19200 30 7521 1250 15000 30 7566 2975 35700 20 7654 1250 15000 30 7698 2850 34200 30 ...
- 99. 99 The Invisible Index • Set an index to VISIBLE or INVISIBLE – ALTER INDEX idx INVISIBLE; – ALTER INDEX idx VISIBLE; – CREATE INDEX... INVISIBLE; • Great to turn off indexes for a while when you think they‟re not being used, but BEFORE you drop them. • Can use INDEX (to override invisibility) or NO_INDEX (to override visibility) hints to override either setting. • The index IS MAINTAINED during DML • Great for testing!
- 100. 100 The Invisible Index create index deptno_invisible_idx on dept_rich(deptno) invisible; Index created. select count(*) from dept_rich where deptno = 30; (doesn‟t see the index) COUNT(*) -------------- 512 Execution Plan ---------------------------------------------------------- Plan hash value: 3024595593 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2 | 4 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 2 | | | |* 2 | TABLE ACCESS FULL| DEPT_RICH | 512 | 1024 | 4 (0)| 0:00:01 | --------------------------------------------------------------------------------
- 101. 101 The Invisible Index (set visible) alter index dept_rich_inv_idx visible; Index altered. select count(*) from dept_rich where deptno = 30; (it does see the index) COUNT(*) -------------- 512 Execution Plan ---------------------------------------------------------- Plan hash value: 3699452051 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2 | 1 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 2 | | | |* 2 | INDEX RANGE SCAN| DEPT_RICH_INV_IDX | 512 | 1024 |1 (0)| 00:00:01 | ---------------------------------------------------------------------------------------
- 102. 102 The Invisible Index (set visible) select /*+ no_index(dept_rich dept_rich_inv_idx) */ count(*) from dept_rich where deptno = 30; (forces not using the index with hint) COUNT(*) ---------- 512 Execution Plan ---------------------------------------------------------- Plan hash value: 3024595593 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2 | 4 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 2 | | | |* 2 | TABLE ACCESS FULL| DEPT_RICH | 512 | 1024 | 4 (0)| 0:00:01 | --------------------------------------------------------------------------------
- 103. 103 The Invisible Index (check it) alter index dept_rich_inv_idx invisible; Index altered. select index_name, visibility from dba_indexes (or go to USER_INDEXES) where index_name = 'DEPT_RICH_INV_IDX„; INDEX_NAME VISIBILITY -------------------------------- ------------------ DEPT_RICH_INV_IDX INVISIBLE
- 104. Create & Rebuild Index Online
- 105. 105 Create & Rebuild Index Online • You can create/rebuild indexes even when doing DML on the base table, but it‟s better to do during low DML activity. • Prior to Oracle 11g, this required an exclusive lock at the beginning and end of the rebuild. This lock could cause DML delays and performance spike. This lock is no longer required for this operation. • Rebuild is faster than a DROP and CREATE • Basic Syntax: CREATE INDEX index_name ON table (col1,...) ONLINE; Index created. ALTER INDEX index_name REBUILD ONLINE; Index altered.
- 106. 106 Rebuild Index or Coalesce (FYI) Coalesce Example from Oracle Doc.
- 107. 107 Rebuild Index or Coalesce Rebuild: • Quickly move index to another tablespace • Requires more disk space • Creates new index tree and shrinks heights • Change storage/tblspc w/o Coalesce • Can‟t move to another tablespace • Requires much less space than rebuild • Coalesces leaf blocks that are in the same branch • Quickly frees index leaf blocks for use
- 108. Nice Developer Tools/Improvements DDL_LOCK_TIMEOUT PL/SQL Expressions Simple Integer New PL/SQL Packages
- 109. 109 The DDL Lock Timeout • DDL Statements (Create/Alter/Drop) require exclusive locks and thus sometimes fail due to bad timing. • The parameter DDL_LOCK_TIMEOUT specifies the amount of time (in seconds) the DDL statement will wait for the lock before timing out and failing. • The default value is 0, the max value is 100000 (27.77 hours). • Example: alter session set DDL_LOCK_TIMEOUT = 30 Session altered.
- 110. 110 Allow Sequences in PL/SQL Expressions • In Previous Versions needed to retrieve the value of a sequence (CURRVAL / NEXTVAL) by invoking a cursor (explicit or implicit). In 11g: • No cursor is needed so the code is more efficient. • For big jobs – Saves MANY cursors
- 111. 111 Allow Sequences in PL/SQL Expressions OLD Way DECLARE V_NEW_VAL NUMBER; BEGIN SELECT MY_SEQ.NEXTVAL INTO V_NEW_VAL FROM DUAL; END; NEW Way DECLARE V_NEW_VAL NUMBER; BEGIN V_NEW_VAL := MY_SEQ.NEXTVAL; END;
- 112. 112 Simple Integer Data Type • Oracle added the new SIMPLE_INTEGER data type to be more efficient than PLS_INTEGER since the operations are done directly at the hardware level. There is also a built-in NOT NULL condition for SIMPLE_INTEGER. • The performance is larger when the PLS_CODE_TYPE=„NATIVE‟ vs. INTERPRETED • We used a PL/SQL Block to loop through 1 million times incrementing a numeric variable by one. We executed the test for each of these three times. Results: NUMBER: 1.26s PLS_INTEGER: 0.88s SIMPLE_INTEGER: 0.65s
- 113. 113 Additional Enhancements New PL/SQL Packages • DBMS_AUTO_TASK_ADMIN • DBMS_COMPARISON • DBMS_DG • DBMS_EDITIONS_UTILITIES • DBMS_HM (Health Monitor) • DBMS_HPROF • DBMS_MGD_ID_UTL • DBMS_NETWORK_ACL_ADMIN • DBMS_RESCONFIG • DBMS_RESULT_CACHE • DBMS_SQLDIAG (SQL Repair) • DBMS_WORKLOAD_CAPTURE • DBMS_WORKLOAD_REPLAY • DBMS_XA • DBMS_XDBADMIN • DBMS_XEVENT • DBMS_XMLDTD • DBMS_XMLINDEX • DBMS_XMLTRANSLATIONS • SDO_RDF • SDO_RDF_INFERENCE
- 114. 114 Additional Enhancements Enhanced PL/SQL Packages • DBMS_ADVISOR • DBMS_APPLY_ADM • DBMS_AQ • DBMS_AQADM • DBMS_CAPTURE_ADM • DBMS_CDC_PUBLISH • DBMS_CDC_SUBSCRIBE • DBMS_CQ_NOTIFICATION • DBMS_DATA_MINING • DBMS_DATA_MINING_TR ANSFORM • DBMS_DATAPUMP • DBMS_EXPFIL • DBMS_FLASHBACK • DBMS_HS_PASSTHR OUGH • DBMS_LOB • DBMS_LOGSTDBY • DBMS_MGWADM • DBMS_MVIEW • DBMS_PREDICTIVE_ ANALYTICS • DBMS_RESOURCE_M ANAGER • DBMS_RLMGR • DBMS_RULE_ADM • DBMS_SCHEDULER • DBMS_SERVER_ALE RT • DBMS_SESSION • DBMS_SPACE • DBMS_SQL • DBMS_SQLTUNE • DBMS_STATS • DBMS_STREAMS_ ADM • DBMS_TRACE • DBMS_UTILITY • DBMS_WORKLOA D_REPOSITORY • DBMS_XDB • DBMS_XMLSCHE MA • DBMS_XPLAN • UTL_INADDR • UTL_RECOMP • UTL_SMTP • UTL_TCP
- 115. Nice DBA Tool Oracle Secure Files
- 116. 116 Oracle SecureFiles High-Performance Large Objects • High-performance transactional access to large object data –RFID, DICOM medical, CAD, images, 3D spacial –low-latency, high throughput, concurrent access –space-optimized storage • Protect your valuable data ... Keep large objects in the database! –transactions –transparent encryption –compression and de-duplication –database-quality security, reliability, and scalability • Better security, single view and management of data • Superset of LOB interfaces – easy migration
- 117. 117 Oracle Secure Files Better Performance than LOBs… Read Performance Write Performance 0 .0 1 0 .1 1 10 10 0 Mb/Sec 0 .0 1 0 .1 1 10 10 0 Mb/Sec File Size (Mb) File Size (Mb) Secure Files Linux Files Secure Files Linux Files Adding Files using New Disk Space – 2x fast than LOBs Adding Files using Deleted Space – 22x faster than LOBs PL/SQL Reads – 6x Faster than LOBs Your mileage will vary....
- 118. ADDM Enhancements (Automatic Database Diagnostic Monitor)
- 119. 119 ADDM enhancements • Global ADDM so that Diagnostics are done across the entire cluster • Emergency ADDM for use when database is hung • On any granularity – Database Cluster – Database Instance – Specific Target (such as host, ASM...etc.) • Over a specified time NOT tied to a pair of snapshots
- 120. 120 ADDM Briefly Specific Database Instance We have 5 ADDM Findings Check them Here
- 121. 121 ADDM Briefly Top ADDM Findings Click a Single Timeframe Let’s Check the Hard Parse Issue
- 123. 123 ADDM - Run NOW! A Big Problem Occurs Run ADDM NOW!
- 124. 124 ADDM - Run NOW! Are you Sure? Running
- 125. 125 ADDM – Run NOW! Done. CPU Issue
- 126. 126 ADDM – Run NOW! Detail on CPU Issue? Suggested Fixes
- 127. 127 ADDM – Run NOW! View The Report
- 128. 128 ADDM for RAC AWR 1 AWR 2 AWR 3 Inst 1 Inst 2 Inst 3 Self-Diagnostic Engine Database-Level ADDM 11g Instance-Level ADDM • Performance expert in a box – Now RAC specialist too! • Identifies the most “Globally Significant” performance issues for the entire RAC database • Database-wide and instance-level analysis • Database-wide analysis of: – Global cache interconnect issues – Lock manager congestion issues – Global resource contention, e.g. IO bandwidth, hot blocks – Globally high-load SQL – Skew in instance response times • Allows drill down to instances • Runs proactively every hour when taking AWR Snapshots (default)
- 129. 129 ADDM Considerations: • CPU Bottlenecks • Undersized Memory Structures – SGA / PGA • I/O Capacity Issues • High Load SQL statements • High Load PL/SQL • RAC specific issues – Global hot block/interconnect • Application issues such as parsing, locks...etc. • Concurrency (buffer busy) or hot object issues • Configuration issues – Redo, Archive, Checkpoint.
- 130. 130 SQL Tuning Advisors & SQL Plan Management (SPM) Reminder: COLLABORATE 12 April 22-26, 2012 Mandalay Bay Convention Center Las Vegas, Nevada
- 131. 131 SQL Plan Management • SQL Plan Management is a mechanism that records/evaluates execution plan of SQL statements (good & bad) over time and builds SQL Plan baselines (replaces stored outlines) of existing plans known to be efficient. • Events that cause the need for SQL Plan baselines: – New version of Oracle (New optimizer version – Use capture replay to test effect) – Changes to optimizer statistics or data changes – Schema, application or metadata changes (use SQL Advisor to get suggestions) – System settings changes (Use SQL Replay to find what works) – SQL Profile (statistics – data skews & correlated columns) creation • Stored outlines are deprecated (discouraged) in Oracle Database 11g. Oracle highly recommends migrating existing stored outlines to SQL plan baselines. A SQL Profile contains additional STATISTICS for this SQL statement for the query optimizer to generate a better execution plan. An outline/baseline contains HINTS for this SQL statement for query optimizer to generate a better execution plan.
- 132. 132 SQL Plan Management Recommends for SQL or Group of SQL statements: • SQL Profile stores STATISTICS for a SQL statement for the query optimizer to generate a better execution plan. • A Stored Outline/SQL Plan Baseline contains HINTS for this SQL statement for query optimizer to generate a better execution plan. • A SQL Plan Baseline should evolve with changes in the system to analyze good/bad plans over time. • View these in DBA_PLAN_BASELINES • You can also export a SQL Tuning Set and import it to new system. Capture baselines for Tuning Set with DBMS_SPM (see later slide on entire syntax). Can also use a pack/unpack function to pack/unpack all plans in a system for transporting.
- 133. 133 SQL Plan Management Create a SQL Tuning Set Tuning Issue Create a Tuning Set from Top 10 SQL
- 134. 134 Top Activity – 11gR2 (same look)
- 135. 135 SQL Plan Management Create a SQL Tuning Set Tuning Set Name Queries
- 136. 136 SQL Plan Management Viewing a SQL Tuning Set Tuning Set Name Queries & Stats
- 137. 137 SQL Plan Management Create a SQL Tuning Set Run the Tuning Advisor on this SQL Tuning Set (STS) Run it NOW
- 138. 138 SQL Plan Management Create a SQL Tuning Set Results Select One query And click View
- 139. 139 SQL Plan Management Click on any SQL ID SQL Text Waits & Statistics
- 140. 140 SQL Plan Management Create a SQL Tuning Set SQL Profile Will Help 99%
- 141. 141 SQL Plan Management Create a SQL Tuning Set Compare Before & After
- 142. 142 SQL Plan Control SQL Profiles stored in the system SQL Profiles SQL Plan Baselines
- 143. 143 SQL Performance Analyzer (SPA) COLLABORATE 12 April 22-26, 2012 Mandalay Bay Convention Center Las Vegas, Nevada
- 144. 144 SQL Performance Analyzer • Measure and report on performance before and after a change! DBMS_SQLTUNE package. Great for: • Database Upgrades • Application Upgrades • Hardware Changes • Database or Schema Changes • Best for SQL Tuning – Especially Batches
- 145. 145 SQL Performance Analyzer Easy to run – SQL Focus (Test SGA settings): • Capture SQL • Transport SQL • Create a Replay Task • Set up the environment to Test • Make any changes to Test (such as SGA/Optimizer) • Compare before and after performance • Tune the problems!
- 147. 147 SQL Performance Analyzer Guided Workflow
- 148. 148 SQL Performance Analyzer Optimizer Upgrade (10g vs. 11g)
- 149. 149 SQL Performance Analyzer 11gR2 - Options Upgrade Options
- 150. 150 SQL Performance Analyzer 11gR2 – Exadata Simulation Test a Tuning Set that I’ve used in the past
- 151. 151 SQL Performance Analyzer 11gR2 – Exadata Simulation Job is running
- 152. 152 SQL Performance Analyzer 11gR2 – Exadata Simulation New! View PL/SQL
- 153. 153 SQL Performance Analyzer 11gR2 – Exadata Simulation Click on Job after complete View Report
- 154. 154 SQL Performance Analyzer 11gR2 – Exadata Simulation Simple Job so no benefit
- 156. 156 SQL Advisors 11gR2 – (same) Tuning Advisors (Access Advisor - next) Repair Advisor (later)
- 157. SQL Access Advisor NEW Partition Advisor
- 158. 158 SQL Access Advisor & NEW Partition Advisor • The SQL Advisor now combines the functionality of the SQL Tuning Advisor, SQL Access Advisor and the new Partition Advisor. – Recommends Partitioning Needs – Utilize a previous SQL Tuning Set – Take SQL straight from what‟s currently in the CACHE. – Create a hypothetical workload – SQL Access Advisor checks Indexes, Partitions or Materialized Views (schema related issues)
- 159. 159 SQL Access Advisor & NEW Partition Advisor Step One Use a SQL Tuning Set
- 160. 160 SQL Access Advisor & NEW Partition Advisor Look at Partitions Quick Solution
- 161. 161 SQL Access Advisor & NEW Partition Advisor Step 3 Schedule it. Run it Now!
- 162. 162 SQL Access Advisor & NEW Partition Advisor Final Review
- 163. 163 SQL Access Advisor & NEW Partition Advisor Job Submitted Job Running Now.
- 164. 164 SQL Access Advisor & NEW Partition Advisor Improve I/O Improve Execution Time
- 165. 165 Repair the Problem “on the fly” The Business of IT is serving information... Not giving users ORA-600 errors… The SQL Repair Advisor
- 166. 166 SQL Repair Advisor • Used to Repair Problem SQL – Oracle Errors • Reloads and recompiles SQL statements to gather diagnostics information to fix. • Uses the diagnostic information to repair the problem SQL statement (DBMS_SQLDIAG) • Will fix error going through compilation, execution and trying different routes (could be a slower route for now) to come up with a temporary SQL Patch without error until fixed.
- 167. 167 SQL Repair Advisor – Go straight from Alerts Go to the Database Instance Click Alert (ORA-600) message text to see details
- 168. 168 SQL Repair Advisor – View Problem Details Click on View Problem Details to go to the Support Bench
- 169. 169 Support Workbench - Details Click on SQL Repair Advisor
- 170. 170 Results from SQL Repair Advisor Click on View to Get the Detail finding of the Advisor Note a SQL Patch (FIX for the SQL) has been generated
- 171. 171 SQL Repair Advisor Recommendation / Confirmation Click on Implement To accept the SQL Patch
- 172. 172 Other 11g Tuning New Features
- 173. 173 Real Application Testing! Database workload capture and replay
- 174. 174 Database workload capture and replay • Used to capture database workload on one system and replay later on a different system. Useful to compare two different systems. • Could rival LoadRunner in the future (may be more precise!) Brief Steps: • Capture workload on a database even from 10gR2 • Restore the database on a test system to the SCN when capture begins • Perform upgrade and make changes to the test system as needed • Preprocess the captured workload if it is not preprocessed • Configure the test system for replay (I don‟t do this here) • Replay workload on the restored database (I don‟t have this in this presentation, but will show some of the screens to do it) • Great to test upgrade to 11g (Capture 10gR2 then test against 11g)
- 175. 175 Post-Change Test System … Replay Driver … … … App Server App Server App Server … Process Process Process … Process Process Process … Can use Snapshot Standby as test system Replay Driver Client Client … Client Pre-Change (could be 9.2.0.8 or 10g Capture) Production System Processed Captured Workload Backup Capture Workload
- 176. 176 Database Replay FYI Only – Download to view in detail Real App Testing: Database Replay
- 177. 177 Replay Options... • Synchronized Replay – Exact Concurrency, commits & data divergence minimal • Unsynchronized Replay – Not the same concurrency or commits – Data divergence can be large depending on load test performed • Creates Report – Data Divergence – Error Divergence – Performance Divergence
- 178. 178 Database Replay – 11gR2 (quick look) FYI Only – Download to view in detail Real App Testing: Database Replay
- 179. 179 Adding Nodes the Easy Way in 11gR2 (FYI look only)
- 180. 180 DB Instance – Software/Support 11gR2 - Deployment Procedures Easy RAC Add Nodes (provisioning)
- 181. 181 DB Instance – Software/Support 11gR2 - Deployment Procedures One Click Extend Cluster
- 182. 182 DB Instance – Software/Support 11gR2 - Deployment Procedures Step by Step on What Happened
- 183. Partitioning: (FYI Only) - Tables can be split into many pieces (10g). - Only a subset of the data is queried - All of the data COULD be queried - Leads to enhanced performance of large tables - Re-orgs & backups can be done on a partition level - 4 quick examples follow (many many rules for each) - WHAT‟S NEW IN ORACLE 11G
- 184. 184 The Rules – See Partitioning Guide
- 185. 185 Range Partitioning (V8) CREATE TABLE DEPT (DEPTNO NUMBER(2), DEPT_NAME VARCHAR2(30)) PARTITION BY RANGE(DEPTNO) (PARTITION D1 VALUES LESS THAN (10) TABLESPACE DEPT1, PARTITION D2 VALUES LESS THAN (20) TABLESPACE DEPT2, PARTITION D3 VALUES LESS THAN (MAXVALUE) TABLESPACE DEPT3); INSERT INTO DEPT VALUES (1, ‘DEPT 1’); INSERT INTO DEPT VALUES (7, ‘DEPT 7’); INSERT INTO DEPT VALUES (10, ‘DEPT 10’); INSERT INTO DEPT VALUES (15, ‘DEPT 15’); INSERT INTO DEPT VALUES (22, ‘DEPT 22’);
- 186. 186 Range Partitioning (8i) (Multi-Column) create table cust_sales ( acct_no number(5), cust_name char(30), sale_day integer not null, sale_mth integer not null, sale_yr integer not null) partition by range (sale_yr, sale_mth, sale_day) (partition cust_sales_q1 values less than (1998, 04, 01) tablespace users1, partition cust_sales_q2 values less than (1998, 07, 01) tablespace users2, partition cust_sales_q3 values less than (1998, 10, 01) tablespace users3, partition cust_sales_q4 values less than (1999, 01, 01) tablespace users4, partition cust_sales_qx values less than (maxvalue, maxvalue, maxvalue) tablespace users4);
- 187. 187 Hash Partitioning (8i) (Multi-Column) create table cust_sales_hash ( acct_no number(5), cust_name char(30), sale_day integer not null, sale_mth integer not null, sale_yr integer not null) partition by hash (acct_no) partitions 4 store in (users1, users2, users3, users4);
- 188. 188 Composite Partitioning v (8i) CREATE TABLE test5 (data_item INTEGER, length_of_item INTEGER, storage_type VARCHAR(30), owning_dept NUMBER, storage_date DATE) PARTITION BY RANGE (storage_date) SUBPARTITION BY HASH(data_item) SUBPARTITIONS 4 STORE IN (data_tbs1, data_tbs2, data_tbs3, data_tbs4) (PARTITION q1_1999 VALUES LESS THAN (TO_DATE('01-apr-1999', 'dd-mon-yyyy')), PARTITION q2_1999 VALUES LESS THAN (TO_DATE('01-jul-1999', 'dd-mon-yyyy')), PARTITION q3_1999 VALUES LESS THAN (TO_DATE('01-oct-1999', 'dd-mon-yyyy')) (SUBPARTITION q3_1999_s1 TABLESPACE data_tbs1, SUBPARTITION q3_1999_s2 TABLESPACE data_tbs2), PARTITION q4_1999 VALUES LESS THAN (TO_DATE('01-jan-2000', 'dd-mon-yyyy')) SUBPARTITIONS 8 STORE IN (q4_tbs1, q4_tbs2, q4_tbs3, q4_tbs4, q4_tbs5, q4_tbs6, q4_tbs7, q4_tbs8), PARTITION q1_2000 VALUES LESS THAN (TO_DATE('01-apr-2000', 'dd-mon-yyyy')));
- 189. 189 List Partitioning (Allowed since 9i) create table dept_part (deptno number(2), dname varchar2(14), loc varchar2(13)) partition by list (dname) (partition d1_east values ('BOSTON', 'NEW YORK'), partition d2_west values ('SAN FRANCISCO', 'LOS ANGELES'), partition d3_south values ('ATLANTA', 'DALLAS'), partition d4_north values ('CHICAGO', 'DETROIT')); Table created.
- 190. 190 Interval Partitioning – 11g • This is a helpful addition to range partitioning where Oracle automatically creates a partition when the inserted value exceeds all other partition ranges. 11g also has Ref & Virtual Column Partitioning (covered here as fyi only). There are the following restrictions: • You can only specify one partitioning key column, and it must be of NUMBER or DATE type. • Interval partitioning is NOT supported for index-organized tables. • Interval Partitioning supports composite partitioning: – Interval-range *** Interval-hash *** Interval-list • You can NOT create a domain index on an interval-partitioned table.
- 191. 191 Interval Partitioning – 11g CREATE TABLE DEPT_new (DEPTNO NUMBER(2), DEPT_NAME VARCHAR2(30)) PARTITION BY RANGE(DEPTNO) (PARTITION D1 VALUES LESS THAN (10), PARTITION D2 VALUES LESS THAN (20), PARTITION D3 VALUES LESS THAN (30)); Table created. SQL> insert into dept_new values(40, 'test2'); insert into dept_new values(40, 'test2') * ERROR at line 1: ORA-14400: inserted partition key does not map to any partition
- 192. 192 Interval Partitioning – 11g select segment_name, partition_name from dba_segments where segment_name = 'DEPT_NEW„; SEGMENT_NAME PARTITION_NAME ------------------------------ ---------------------------- DEPT_NEW D1 DEPT_NEW D2 DEPT_NEW D3
- 193. 193 Interval Partitioning – 11g CREATE TABLE DEPT_NEW2 (DEPTNO NUMBER(2), DEPT_NAME VARCHAR2(30)) PARTITION BY RANGE(DEPTNO) INTERVAL(10) (PARTITION D1 VALUES LESS THAN (10), PARTITION D2 VALUES LESS THAN (20), PARTITION D3 VALUES LESS THAN (30)) Table created. SQL> insert into dept_new2 values(40, 'test2'); 1 row created.
- 194. 194 Interval Partitioning – 11g insert into dept_new2 values(40,null); insert into dept_new2 values(50,null); insert into dept_new2 values(99,null); select segment_name, partition_name from dba_segments where segment_name = 'DEPT_NEW2' SEGMENT_NAME PARTITION_NAME ------------------------------ ------------------------------ DEPT_NEW2 D1 DEPT_NEW2 D2 DEPT_NEW2 D3 DEPT_NEW2 SYS_P41 DEPT_NEW2 SYS_P42 DEPT_NEW2 SYS_P43
- 195. 195 System Partitioning – 11g • Great when you will insert a lot of data and want to break it into smaller pieces, but in the same table.You decide what data goes there. • RAC: One partition per node. Reduce interconnect traffic, locking…(using it as Workload Management Enabled). • You can NOT forget to specify the partition or you will get an: ORA-14701: Partition-extended name or bind variable must be used for DMLs on tables partitioned by System method. There are the following restrictions: • Can NOT be used with index-organized tables • Can NOT play a part in Composite Partitioning • Can NOT Split • Can NOT be used with CREATE AS SELECT… • Can use: CREATE TABLE …PARTITION BY SYSTEM PARTITIONS n (where n is 1 to 1024K-1)
- 196. 196 System Partitioning (11g) CREATE TABLE DEPT (DEPTNO NUMBER(2), DEPT_NAME VARCHAR2(30)) PARTITION BY SYSTEM (PARTITION D1, PARTITION D2, PARTITION D3); INSERT INTO DEPT PARTITION D1 VALUES (1, ‘DEPT 1’); INSERT INTO DEPT PARTITION D1 VALUES (22, ‘DEPT 22’); INSERT INTO DEPT PARTITION D1 VALUES (10, ‘DEPT 10’); INSERT INTO DEPT PARTITION D2 VALUES (15, ‘DEPT 15’); INSERT INTO DEPT PARTITION D3 VALUES (7, ‘DEPT 7’); Partition clause is optional for UPDATE & DELETES, but more efficient if you can use it (Careful to ensure you‟re doing what you need).
- 197. 197 Reference Partitioning – 11g (FYI Only) • Allows the partitioning of two tables related to one another by referential constraints. The partitioning key is resolved through an existing parent-child relationship, enforced by enabled and active primary key and foreign key constraints. • Tables with a parent-child relationship can be logically equi-partitioned by inheriting the partitioning key from the parent table without duplicating the key columns. The logical dependency will also automatically cascade partition maintenance operations, thus making application development easier and less error-prone.
- 198. 198 Reference Partitioning – 11g (FYI Only)
- 199. 199 Reference Partitioning – 11g
- 200. 200 Partition Compression • You can now COMPRESS individual partitions • Compression as high as 3.5 to 1 is possible • Compressed Tables now support – DML Statements – Add and Drop Column – Partition level COMPRESS or NOCOMPRESS • ALTER TABLE... COMPRESS (old compress) • ALTER TABLE... NOCOMPRESS • Table compression now supported for OLTP • New Advanced Compression Option (chargeable): – CREATE TABLE t1 COMPRESS FOR ALL OPERATIONS Presentation by Mike Messina on Compressing & Costs Also - Shyam Varan Nath – Honey I shrunk the Data Warehouse
- 201. 201 Partition Compression CREATE TABLE DEPT_new3 (DEPTNO NUMBER(2), DEPT_NAME VARCHAR2(30)) COMPRESS FOR OLTP PARTITION BY RANGE(DEPTNO) interval(10) (PARTITION D1 VALUES LESS THAN (10), PARTITION D2 VALUES LESS THAN (20) NOCOMPRESS, PARTITION D3 VALUES LESS THAN (30)); Table created. • NOCOMPRESS - The table or partition is not compressed. This is the default action • COMPRESS - Suitable for data warehouse. Compression enabled during direct-path inserts only. • COMPRESS FOR DIRECT_LOAD OPERATIONS - Same affect as the simple COMPRESS. • COMPRESS FOR ALL OPERATIONS - Suitable for OLTP systems. Compression for all operations, including regular DML statements. Requires COMPATIBLE to be set to 11.1.0 or higher. • COMPRESS FOR OLTP - Suitable for OLTP systems. Enables compression for OLTP operations, including regular DML statements. Requires COMPATIBLE to be set to 11.1.0 or higher and in 11.2 replaces the COMPRESS FOR ALL OPERATIONS Syntax, but COMPRESS FOR ALL OPERATIONS syntax still exists and is still valid.
- 202. 202 Partition Compression insert into dept_new3 values(10,null); 1 row created. insert into dept_new3 values(20,null); 1 row created. insert into dept_new3 values(30,null); 1 row created. insert into dept_new3 values(60,null); 1 row created. insert into dept_new3 values(90,null); 1 row created.
- 203. 203 Partition Compression select table_name, partition_name, compression from dba_tab_partitions where table_name = 'DEPT_NEW3„; TABLE_NAME PARTITION_NAME COMPRESS ------------------------------ ------------------------------ ---------------- DEPT_NEW3 D1 ENABLED DEPT_NEW3 D2 DISABLED DEPT_NEW3 D3 ENABLED DEPT_NEW3 SYS_P64 ENABLED DEPT_NEW3 SYS_P65 ENABLED DEPT_NEW3 SYS_P66 ENABLED 6 rows selected.
- 204. 204 Compression History – Timeline (FYI Only) • Index Compression since 8i • Table Compression since 9i – No Additional License Requirement – Only for direct inserts – Compression Not Maintained with updates and normal inserts – Had to re-org table to re-compress over time. • 11g Advanced Compression – Additional License Requirement – Compression Maintained with all DML activity – No re-orgs required after initial compression • 11gR2 – Hybrid Columnar Compression ( with Exadata)
- 205. 205 Advanced Compression (FYI Only) • The Oracle Advanced Compression option contains the following features: – Data Guard Network Compression – Data Pump Compression (COMPRESSION=METADATA_ONLY does not require the Advanced Compression option) – Multiple RMAN Compression Levels (RMAN DEFAULT COMPRESS does not require the Advanced Compression option) – OLTP Table Compression – SecureFiles Compression and Deduplication. LZO compression algorithm added. Faster than ZLIB.
- 206. 206 Advanced Compression & OLTP (FYI Only) • Compression is maintained at a block level. • Maintained through DML operations. • Compression ratio depends on “RANDOMness” of the data. • DML Impact depends on “RANDOMness” of the data. Range of 10 to 30%. – More visible for bulk operations compared to single row operations. • Significant Performance gains in selects, primarily due to reduced block scans. – Exacts / specifics depend on your compression ratio. – Table scans expect upto 50% reduction in block reads. – PK based access, impact not noticeable. • Must evaluate on a case by case basis.
- 207. 207 Hybrid Columnar Compression (FYI Only) • Exadata Hybrid Columnar Compression (EHCC) • Compression of data @ a column level and block level • Maintained in Compression Units (CU), of 32k chunks. • Good Random Row Access but NOT good for updates • Excellent Table Scan performance. • 5x to 30x Compression Ratios to be expected. • Potential Challenges – DML performance – Data load speeds visibly impacted. – Single row access speeds visibly impacted.
- 209. 209 Additional Enhancements • Ability to online redefine tables that have materialized view logs: – Tables with materialized view logs can now be redefined online. – Materialized view logs are now one of the dependent objects that can be copied to the interim table with the DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS package procedure. • DBMS_STATS performance has been improved.
- 210. 210 Large-Scale Data Warehouses* Feature Usage Source: Oracle ST Survey * Oracle Survey
- 212. 212 Automatic Diagnostic Repository (ADR) • Oracle 11g includes a Fault Diagnosability Infrastructure to prevent, detect, diagnose, resolve issues related to bugs, corruption, etc. • When a critical error occurs it is assigned an incident number and all diagnostic data tagged with this in ADR. • ADR is a file based repository outside of the database • ADR helps detect problems proactively • ADR helps limit the damage of interruptions • ADR helps reduce problem diagnostic time • ADR simplifies Oracle Support / Customer interaction • The ADR also contains Health Reports, Trace Files, Dump Files, SQL Test Cases and Data Repair Records
- 213. 213 ADR Directory Structure for a Database Instance ADR Base diag rdbms <database name> <SID> alert cdump incident trace (others) Alert Log: /u01/app/oracle/diag/rdbms/o11gb/O11gb/trace ORACLE_HOME: /u01/app/oracle/product/11.1.0/db_1
- 214. 214 ADR – V$ Diagnostic Info select name, value from v$diag_info; NAME VALUE ----------------------------- ------------------------------------------------ Diag Enabled TRUE ADR Base /u01/app/oracle ADR Home /u01/app/oracle/diag/rdbms/o11gb/O11gb Diag Trace /u01/app/oracle/diag/rdbms/o11gb/O11gb/trace Diag Alert /u01/app/oracle/diag/rdbms/o11gb/O11gb/alert Diag Incident /u01/app/oracle/diag/rdbms/o11gb/O11gb/incident Diag Cdump /u01/app/oracle/diag/rdbms/o11gb/O11gb/cdump Health Monitor /u01/app/oracle/diag/rdbms/o11gb/O11gb/hm Default Trace File /u01/app/oracle/diag/rdbms/o11gb/O11gb/trace/O11gb_ora_16676.trc Active Problem Count 0 Active Incident Count 0 11 rows selected.
- 215. 215 ADR – V$ Diagnostic Info 11R2 – No changes (that I saw)
- 216. Optimizer Statistics & Other Optimizer Advances Special Thanks: Maria Colgan, Penny Avril & Debbie Migliore
- 217. 217 Improved SPEED and Quality Gathering Stats – AUTO-SAMPLING • Manually gather stats: Impossible to find sample size that works for ALL tables - need COMPUTE • Especially hard to find a good sample size when the data distribution is very skewed. • NEW Auto-sampling: “Discovers” the best sample size for every table in your system for you. – Get the Quality of a COMPUTE with SPEED of a SAMPLE – Oracle‟ goal is to OBSOLETE the need and use of sampling. – Accuracy is comparable to COMPUTE
- 218. 218 Incremental Statistics Maintenance - Stats by Partition vs. table • In 10g, if you gather stats on one partition after a bulk load it causes a full scan of all partitions to gather global table statistics with is extremely time consuming • In 10g, you have to manual copy statistics to new partition • In 11g Gather stats for TOUCHED PARTITIONS only! • Table stats are refreshed WITHOUT scanning the un-touched partitions.
- 219. 219 Manage New Statistics Gather Stats but make PENDING • Currently DBAs are scared to gather stats on a table that is changing for fear of unpredictable execution plans. • You have to „FREEZE‟ critical plans or stats. • In 11g, gather stats and save as PENDING. • Verify the new stats won‟t adversely affect things by checking them with a single user using an alter session or try them out on a different system. • When everything looks good – then, PUBLISH them for all to use!
- 220. 220 Manage New Statistics Gather Stats but make them PENDING select dbms_stats.get_prefs('PUBLISH', 'SH', 'CUST') publish from dual; PUBLISH -------------------- TRUE exec dbms_stats.set_table_prefs('SH', 'CUST', 'PUBLISH', 'false'); PL/SQL procedure successfully completed. select dbms_stats.get_prefs('PUBLISH', 'SH', 'CUST') publish from dual; PUBLISH -------------------- FALSE
- 221. 221 Manage New Statistics Gather Stats but make them PENDING select table_name, last_analyzed analyze_time, num_rows, blocks, avg_row_len from user_tables where table_name = 'CUST'; TABLE_NAME ANALYZE_T NUM_ROWS BLOCKS AVG_ROW_LEN ---------- --------- ---------- ---------- ----------- CUST execute dbms_stats.gather_table_stats('SH', 'CUST'); PL/SQL procedure successfully completed. select table_name, last_analyzed analyze_time, num_rows, blocks, avg_row_len from user_tables where table_name = 'CUST'; TABLE_NAME ANALYZE_T NUM_ROWS BLOCKS AVG_ROW_LEN ---------- --------- ---------- ---------- ----------- CUST
- 222. 222 Manage New Statistics PUBLISH Stats after Testing Complete alter session set optimizer_use_pending_statistics = true; (Then run your query – If ready/better – publish the new stats) exec dbms_stats.publish_pending_stats('SH', 'CUST'); PL/SQL procedure successfully completed. select table_name, last_analyzed analyze_time, num_rows, blocks, avg_row_len from user_tables where table_name = 'CUST'; TABLE_NAME ANALYZE_T NUM_ROWS BLOCKS AVG_ROW_LEN ---------- --------- ---------- ---------- ----------- CUST 13-OCT-07 55500 1485 180 exec dbms_stats.delete_table_stats('SH', 'CUST'); <to delete>
- 223. Extended Optimizer Statistics: New Multi-Column Statistics • Corporate data often has correlations between different columns of a table. For example: – A job title is correlated to the salary. – The season affects the sold amounts of items such as swim suits sell more in the summer and snow shoes sell more in the winter. – The make of a car and color are often used together but are not really correlated well so the filter doesn‟t reduce the result set. • Optimizer has to estimate the correct cardinality – Will the additional column condition reduce the result set or not? Should it be used. • Oracle calculates correlated statistics so the optimizer will make great decisions. Single column statistics and histograms are not enough!
- 224. Example SELECT make, price, color FROM cars_dot_com WHERE make = ‘CORVETTE’; SILVER 50,000 CORVETTE BLACK 60,000 CORVETTE RED 40,000 CORVETTE • Three records selected. • Single column statistics are accurate SLIVER 45,000 JEEP BLACK 35,000 JEEP RED 90,000 CADILLAC SILVER 50,000 CORVETTE BLACK 60,000 CORVETTE RED 40,000 CORVETTE Color Price Make
- 225. Example, cont. SELECT make, price, color FROM cars_dot_com WHERE make = ‘CORVETTE’ AND COLOR = 'RED‘; • One record selected. • No correlated columns • Additional predicate reduces result set • Single column statistics are STILL sufficient RED 40,000 CORVETTE SLIVER 45,000 JEEP BLACK 35,000 JEEP RED 90,000 CADILLAC SILVER 50,000 CORVETTE BLACK 60,000 CORVETTE RED 40,000 CORVETTE Color Price Make
- 226. Example, cont. • Three records selected. • Correlated columns • Additional predicate has no effect • Single column statistics are NOT sufficient • Must use ‘=‘ and not < or > SLIVER 50,000 CORVETTE BLACK 50,000 CORVETTE RED 50,000 CORVETTE SLIVER 45,000 JEEP BLACK 35,000 JEEP RED 90,000 CADILLAC SILVER 50,000 CORVETTE BLACK 50,000 CORVETTE RED 50,000 CORVETTE Color Price Make SELECT make, price, color FROM cars_dot_com WHERE make = ‘CORVETTE’ AND PRICE = 50000;
- 227. 227 Manage New Statistics – FYI Only EXTENDED Statistic Group • Provides a way to collect stats on a group of columns • Full integration into existing statistics framework – Automatically maintained with column statistics – Instantaneous and transparent benefit for any application • Accurate cardinalities for inter-related columns – Multiple predicates on the same table are estimated correctly
- 228. 228 Manage New Statistics – FYI Only After normal Statistics Creation select column_name, num_distinct, histogram from user_tab_col_statistics where table_name = 'CUSTOMERS„; COLUMN_NAME NUM_DISTINCT HISTOGRAM ------------------------------ ------------ --------------- CUST_VALID 2 NONE COUNTRY_ID 19 FREQUENCY CUST_STATE_PROVINCE 145 NONE CUST_CITY_ID 620 HEIGHT BALANCED CUST_CITY 620 NONE CUST_LAST_NAME 908 NONE CUST_FIRST_NAME 1300 NONE CUST_ID 55500 NONE ... 23 rows selected.
- 229. 229 Manage New Statistics – FYI Only Create EXTENDED Statistic Group • Now lets create the extended statistics group & re-gather statistics on the CUSTOMER table (query user_tab_col_statistics to see new column): select dbms_stats.create_extended_stats('SH','CUSTOMERS', '(country_id, cust_state_province)') from dual; DBMS_STATS.CREATE_EXTENDED_STATS('SH','CUSTOMERS','(CO -------------------------------------------------------------------------------- SYS_STUJGVLRVH5USVDU$XNV4_IR#4 exec dbms_stats.gather_table_stats('SH','CUSTOMERS', method_opt => 'for all columns size skewonly'); PL/SQL procedure successfully completed.
- 230. 230 Manage New Statistics – FYI Only Now there are Extended Statistics select column_name, num_distinct, histogram from user_tab_col_statistics where table_name = 'CUSTOMERS'; COLUMN_NAME NUM_DISTINCT HISTOGRAM ------------------------------ ------------ --------------- SYS_STUJGVLRVH5USVDU$XNV4_IR#4 145 FREQUENCY CUST_VALID 2 FREQUENCY COUNTRY_ID 19 FREQUENCY CUST_STATE_PROVINCE 145 FREQUENCY CUST_CITY_ID 620 HEIGHT BALANCED CUST_CITY 620 HEIGHT BALANCED CUST_LAST_NAME 908 HEIGHT BALANCED CUST_FIRST_NAME 1300 HEIGHT BALANCED CUST_ID 55500 HEIGHT BALANCED ... 24 rows selected.
- 231. 231 Manage New Statistics – FYI Only DROP Extended Statistics exec dbms_stats.drop_extended_stats('SH', 'CUSTOMERS', '(country_id, cust_state_province)'); PL/SQL procedure successfully completed. select column_name, num_distinct, histogram from user_tab_col_statistics where table_name = 'CUSTOMERS„; COLUMN_NAME NUM_DISTINCT HISTOGRAM ------------------------------ ------------ --------------- CUST_VALID 2 NONE COUNTRY_ID 19 FREQUENCY CUST_STATE_PROVINCE 145 NONE CUST_CITY_ID 620 HEIGHT BALANCED CUST_CITY 620 NONE CUST_LAST_NAME 908 NONE CUST_FIRST_NAME 1300 NONE CUST_ID 55500 NONE ... 23 rows selected.
- 232. 232 Adaptive Cursor Sharing • The optimizer peeks at user-defined bind values during plan selection on the hard parse. • Initial value of the binds determines the plan for all future binds (hopefully the first peek covers most queries) • Same execution plan shared regardless of future bind values • One plan is not always appropriate for all bind values for a given SQL statement – Where job= „PRESIDENT‟ (use an index – only one row) – Where job = „OPERATOR‟ (don‟t use an index – 90% of the table) • If Oracle “peeks” and sees the President, it will use the index. Future queries also use the index without peeking after that (bad for the OPERATOR query).
- 233. 233 Bind Peeking – Pre-11g • If you need to tune a query that you suspect has issues related to bind peeking, use v$sql_plan or tkprof output using different values for bind variables and compare execution plans in both cases. • If you wish to deactivate bind peeking you can set: alter system set "_OPTIM_PEEK_USER_BINDS"=FALSE; Note: When running tkprof "explain=username/password" argument should NOT be used. That will cause tkprof to issue an explain plan whose output could differ from the execution plan info inside the raw 10046/sql_trace file.
- 234. Consider a Telephone Company… OPERATOR 7782 CLARK OPERATOR 7788 SCOTT PRESIDENT 8739 KING OPERATOR 7521 WARD OPERATOR 7499 ALLEN OPERATOR 6973 SMITH Job Empno Ename SELECT Ename, Empno, Job FROM Emp WHERE Job = :B1 Value of B1 = „OPERATOR‟; • If ‘OPERATOR’ is the bind value at hard parse, most records will be selected. Execution plan will be a full table scan • If ‘PRESIDENT’ is the bind value at hard parse, few records will be selected. Execution plan will be an index search OPERATOR 7782 CLARK OPERATOR 7788 SCOTT OPERATOR 7521 WARD OPERATOR 7499 ALLEN OPERATOR 6973 SMITH Job Empno Ename
- 235. 235 Adaptive Cursor Sharing Solution: • In 11g, Oracle uses bind-aware cursor matching. • Share the plan when binds values are “equivalent” – Plans are marked with selectivity range – If current bind values fall within range they use the same plan • Create a new plan if binds are not equivalent – Generating a new plan with a different selectivity range
- 236. 236 Bind Peeking Cursor Sharing (cs) Statistics select sql_id, peeked, executions, rows_processed, cpu_time from v$sql_cs_statistics; (using the peeked value on the 2nd+ execution) SQL_ID P EXECUTIONS ROWS_PROCESSED CPU_TIME ------------- - ---------- -------------- ---------- 5wfj3qs71nd7m Y 3 1 0 2rad83pp613m1 Y 3 3 0 dr78c03uv97bp N 1 3 0 dr78c03uv97bp N 1 3 0 dr78c03uv97bp Y 1 3 0 9qv6tq9ag5b80 Y 3 3 0 a2k4qkh681fzx Y 3 2 0 413zr99jf9h72 N 1 1 0 413zr99jf9h72 N 1 1 0 413zr99jf9h72 Y 1 1 0 fd69nfzww1mhm Y 6 0 0
- 237. 237 Bind Peeking – V$SQL select sql_id, executions, is_bind_sensitive, is_bind_aware from v$sql; SQL_ID EXECUTIONS I I ------------- ---------- - - 9ugwm6xmvw06u 11 Y N bdfrydpbzw07g 11 Y N 57pfs5p8xc07w 20 N N ... • is_bind_sensitive – If „Y‟, then Oracle is using multiple plans depending on bind variable. • is_bind_aware – Oracle knows that the different data patterns may result depending on bind value. Oracle switches to a bind-aware cursor and may hard parse the statement.
- 238. 238 Host and Hardware Enterprise Manager for the Grid Database Oracle9iAS Storage Network and Load Balancer Applications Administration Monitoring Provisioning Security Enterprise Manager
- 239. 239 Performance Manager : Back in Time!
- 240. 240 Grid Control – 10gR2; Many more Options!
- 241. 241 Some 11gR2 Screen Shots
- 242. 242 Some 11gR2 Screen Shots
- 244. 244 Security Enhancements • 11g is more restrictive – Password lock time (1), password grace time (7) and password life time (180) all more restrictive; Failed login attempts stays the same (10). – Passwords will be case sensitive now! (on by default) – Enhanced hashing algorithm for passwords / DES still available. – Strong passwords (set via password complexity verification in EM or SQL): • Minimum 8 characters • At least one letter and one digit • Not servername or servername(1-100) • Not a common password (i.e. welcome1) • Must differ from previous password by 3 characters minimum
- 245. 245 Security Enhancements AUDIT_TRAIL=DB (default) • Audit Trail is ON by default (was off in 10g), • AUDIT_TRAIL=DB is now the default. • Things that will be audited by default include: – CREATE USER, CREATE SESSION, CREATE ANY TABLLE, CREATE ANY PROCEDURE, CREATE ANY JOB, CREATE EXTERNAL JOB, CREATE ANY LIBRARY, CREATE PUBLIC DB LINK – ALTER USER, ALTER ANY TABLE, ALTER ANY PROCEDURE, ALTER PROFILE, ALTER DATABASE, ALTER SYSTEM, AUDIT SYSTEM – DROP USER, DROP ANY TABLE, DROP ANY PROCEDURE, DROP PROFILE – GRANT ANY PRIVILEGE, GRANT ANY OBJECT PRIVILEGE – EXEMPT ACCESS POLICY – AUDIT SYSTEM • Cost of Auditing improved to be 1-2% cost on TPCC benchmark.
- 246. 246 All the Rest worth noting… • SEC_CASE_SENSITIVE_LOGON=FALSE • CONNECT Role only Create Session (vs. Tbl/View…) • Consider: _NEW_INITIAL_JOIN_ORDERS=FALSE (CBO more join orders – higher parse times possible) • GATHER_STATS_JOB on for all DML: DBMS_STATS.LOCK_TABLE_STATS(„SH‟,‟T1‟); • Auto PROFILES if 3x better; Oracle Always Tuning… • Statspack STILL works in 11g • Real Time stats generated for high cpu queries – Careful! • Generate System Stats on migrate: Tune / 11g Parameters
- 247. 247 Oracle Audit Vault Oracle Database Vault DB Security Evaluation #19 Transparent Data Encryption EM Configuration Scanning Fine Grained Auditing (9i) Secure application roles Client Identifier / Identity propagation Oracle Label Security (2000) Proxy authentication Enterprise User Security Global roles Virtual Private Database (8i) Database Encryption API Strong authentication (PKI, Kerberos, RADIUS) Native Network Encryption (Oracle7) Database Auditing Government customer Oracle Database Security Built over MANY years... 2007 1977
- 248. 248 Other 11gR2 Features • Grid Plug and Play!! • Oracle Restart – DB, ASM, Listener after restart of software/hardware • Out of Place Upgrades (zero downtime for patching) • In Memory Parallel Execution & Auto Degree of Parallelism (DOP) • Enterprise Manager for Provisioning, Clusterware, GPnP, Restart • Universal installer (Remove RAC, de-install, downgrades, patches,restarts) • ASM FS (file system) snapshots – 64 images – backup/reco/data mining! • Intelligent data placement on fast tracks • Flashback Data Archive support for DDL • Instance caging – allocate CPU usage to instances (CPU_COUNT) • Compare SQL Tuning sets to each other • Tuning Advisor can use auto DOP, searches historical performance, transport back to 10gR2 or later for testing. • Virtual Columns can be in PK/FK of reference partition table • Stored outline migration to SQL Plan Management (SPM) • Automatic Block Repair
- 249. 249 Oracle Upgrade Case Studies (Thanks Mike Dietrich, Carol Tagliaferri, Roy Swonger: 11g Upgrade Paper – Oracle Germany) • University with about 20,000 users on Sun Solaris – Moved 10 databases from 9.2.0.8 to 11.1.0.6 – Used SQL Tuning Advisor and SQL Performance Analyzer (SPA) to fix 94 queries – Also moved to RAC, ASM & Data Guard – 30% more logins and yet Response Time is 50% LOWER! • International Customer with 400+ databases on IBM AIX & EMC DMX disks – Moved from 9.2.0.8 to 11.1.0.6 – 54% slower – Used SPM, SPA, DB Replay to tune things… – Changed parameters to 11g – 15% improvement – Gathered system stats – 7% improvement – Used SPA – 18% improvement – Turn on SQL Profiling (SPM) – 8% improvement – 11g is now 11% FASTER than 9.2.0.8 • Data Warehouse customer on RH Linux 64-Bit – Moving from 10.2 to 11.1.0.7 with 50 databases each at around 10T – Over 200,000 partitions in the database – Silent Upgrade of 50 other DWHS‟s unattended using DBUA silent mode
- 250. 250 Helpful V$/X$ Queries (FYI Only)
- 251. 251 V$ Views over the years Version V$ Views X$ Tables 6 23 ? (35) 7 72 126 8.0 132 200 8.1 185 271 9.0 227 352 9.2 259 394 10.1.0.2 340 (+31%) 543 (+38%) 10.2.0.1 396 613 11.1.0.6.0 484 (+23%) 798 (+30%) 11.2.0.1.0 496 (+25%) 945 (+54%)
- 252. 252 Listing of V$ Views select name from v$fixed_table where name like 'GV%' order by name; NAME --------------------------------- GV$ACCESS GV$ACTIVE_INSTANCES GV$ACTIVE_SESS_POOL_MTH GV$AQ1 GV$ARCHIVE…
- 253. 253 Need GV$ - Instance ID select (1 - (sum(decode(name, 'physical reads',value,0)) / (sum(decode(name, 'db block gets',value,0)) + sum(decode(name, 'consistent gets',value,0))))) * 100 “Hit Ratio" from v$sysstat; Hit Ratio ------------------ 90.5817699
- 254. 254 Need GV$ - Instance ID select inst_id, (1 - (sum(decode(name, 'physical reads',value,0)) / (sum(decode(name, 'db block gets',value,0)) + sum(decode(name, 'consistent gets',value,0))))) * 100 “Hit Ratio" from gv$sysstat group by inst_id; INST_ID Hit Ratio -------------- ------------------ 1 90.5817699 2 96.2034537
- 255. 255 X$ used to create V$ select * from v$fixed_view_definition where view_name = 'GV$INDEXED_FIXED_COLUMN‟; VIEW_NAME VIEW_DEFINITION gv$indexed_fixed_column select c.inst_id, kqftanam, kqfcoidx, kqfconam,kqfcoipo from X$kqfco c, X$kqfta t where t.indx = c.kqfcotab and kqfcoidx != 0
- 256. 256 Listing of X$ Tables select name from v$fixed_table where name like 'X%' order by name; NAME --------------------------------- X$ACTIVECKPT X$BH X$BUFQM X$CKPTBUF X$CLASS_STAT…
- 257. 257 Listing of X$ Indexes (498 in 11.1.0.3.0, 419 in 10g; 326 in 9i) select table_name, index_number, column_name from gv$indexed_fixed_column order by table_name, index_number, column_name, column_position; TABLE_NAME INDEX_NUMBER COLUMN_NAME ------------------------------ ------------------------------ ------------------------------ X$CLASS_STAT 1 ADDR X$CLASS_STAT 2 INDX X$DUAL 1 ADDR X$DUAL 2 INDX …
- 258. 258 V$ - System Information select * from v$version; BANNER --------------------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.1.0.3.0 - Beta PL/SQL Release 11.1.0.3.0 - Beta CORE 11.1.0.3.0 Beta TNS for Linux: Version 11.1.0.3.0 - Beta NLSRTL Version 11.1.0.3.0 - Beta
- 259. 259 V$ - System Information select * from v$option; PARAMETER VALUE ----------------------------------- ------------- Partitioning TRUE Objects TRUE Real Application Clusters FALSE Advanced Replication TRUE Bit-Mapped Indexes TRUE …
- 260. 260 V$ - V$SESSION_WAIT (waiting right now) select event, sum(decode(wait_time,0,1,0)) “Waiting Now", sum(decode(wait_time,0,0,1)) “Previous Waits", count(*) “Total” from v$session_wait group by event order by count(*); WAIT_TIME = 0 means that it‟s waiting WAIT_TIME > 0 means that it previously waited this many ms
- 261. 261 V$ - V$SESSION_WAIT EVENT Waiting Now Previous Waits Total --------------------------- ------------------- --------------------- ------------ db file sequential read 0 1 1 db file scattered read 2 0 2 latch free 0 1 1 enqueue 2 0 2 SQL*Net message from client 0 254 480 …
- 262. 262 V$SESSION_WAIT Current Specific waits Buffer Busy Waits or Write Complete Waits Events: SELECT /*+ ordered */ sid, event, owner, segment_name, segment_type,p1,p2,p3 FROM v$session_wait sw, dba_extents de WHERE de.file_id = sw.p1 AND sw.p2 between de.block_id and de.block_id+de.blocks – 1 AND (event = 'buffer busy waits' OR event = 'write complete waits') AND p1 IS NOT null ORDER BY event,sid;
- 263. 263 V$EVENT_NAME Finding P1, P2, P3 col name for a20 col p1 for a10 col p2 for a10 col p3 for a10 select event#,name,parameter1 p1,parameter2 p2,parameter3 p3 from v$event_name where name in ('buffer busy waits', 'write complete waits') EVENT# NAME P1 P2 P3 ------------- -------------------- ---------- ---------- ---------- 74 write complete waits file# block# 76 buffer busy waits file# block# class#
- 264. 264 V$ - V$SESSION_WAIT_HISTORY (Last 10 waits for session) Buffer Busy Waits or Write Complete Waits Events: SELECT /*+ ordered */ sid, event, owner, segment_name, segment_type,p1,p2,p3 FROM v$session_wait_history sw, dba_extents de WHERE de.file_id = sw.p1 AND sw.p2 between de.block_id and de.block_id+de.blocks – 1 AND (event = 'buffer busy waits' OR event = 'write complete waits') AND p1 IS NOT null ORDER BY event,sid;
- 265. 265 Great V$ - V$SESSION_EVENT (waiting since the session started) select sid, event, total_waits, time_waited, event_id from v$session_event where time_waited > 0 order by time_waited; SID EVENT TOTAL_WAITS TIME_WAITED ---------- ------------------------------ ----------- ----------- 159 process startup 2 1 167 latch: redo allocation 4 1 168 log buffer space 2 3 166 control file single write 5 4 …
- 266. 266 V$ - V$SESSION_WAIT_CLASS (session waits by WAIT CLASS) select wait_class, total_waits from v$system_wait_class; WAIT_CLASS TOTAL_WAITS -------------------- ----------- Other 4180 Application 45269 Configuration 297 Concurrency 25467 Commit 54805 Idle 6925277 Network 1859009 User I/O 809979 System I/O 1103539 Scheduler 10276
- 267. 267 Great V$ - V$SYSTEM_EVENT (waits since the instance started) EVENT TOTAL_WAITS TIME_WAITED ------------------------------ ----------- ----------- latch: session allocation 5644 1 latch: redo allocation 4 1 latch: cache buffers chains 4 3 enq: TX - index contention 1 3 direct path write temp 57 6 row cache lock 1 7 … select event, total_waits, time_waited from v$system_event where time_waited > 0 order by time_waited;
- 268. 268 “cursor: pin S wait on X” WAITEVENT • P1 = The idn which is the HASH_VALUE of SQL statement we are waiting on. You can query V$SQL or V$SQLAREA to get the actual SQL_TEXT. select sql_text from v$sqlarea where hash_value=&&P1; • P2 is the mutex value, which is the session id (higher bits) and reference count (which is 0 if you are sleeping/waiting for an X mode holder). select decode(trunc(&&P2/4294967296), 0, trunc(&&P2/65536), trunc(&&P2/4294967296)) SID_HOLDING_THE_MUTEX from dual;
- 269. 269 Find the mutex blocker… • In 11g, you can also go to V$SESSION to see the blocker: select action, blocking_session, blocking_session_status, sql_id from v$session where sid = &SID_HOLDING_THE_MUTEX; (Get SID_HOLDING_THE_MUTEX from query above)
- 270. 270 Also use V$MUTEX_SLEEP and V$MUTEX_SLEEP_HISTORY select mutex_type, count(*), sum(sleeps) from v$mutex_sleep group by mutex_type; MUTEX_TYPE COUNT(*) SUM(SLEEPS) -------------------------------- ---------- ----------- Library Cache 8 3891 Cursor Pin 1 122 select mutex_type, count(*), sum(sleeps) from v$mutex_sleep_history group by mutex_type; MUTEX_TYPE COUNT(*) SUM(SLEEPS) -------------------------------- ---------- ----------- Library Cache 18 3891 Cursor Pin 25 117
- 271. 271 V$ - Top 10 as % of All select sum(pct_bufgets) percent from (select rank() over ( order by buffer_gets desc ) as rank_bufgets, to_char(100 * ratio_to_report(buffer_gets) over (), '999.99') pct_bufgets from v$sqlarea ) where rank_bufgets < 11; PERCENT ------------ 97.07
- 272. 272 V$ - What Users are doing… select a.sid, a.username, s.sql_text from v$session a, v$sqltext s where a.sql_address = s.address and a.sql_hash_value = s.hash_value order by a.username, a.sid, s.piece; SID USERNAME SQL_TEXT ------ ------------------- ------------------------------------ 11 PLSQL_USER update s_employee set salary = 10000 9 SYS select a.sid, a.username, s.sql_text 9 SYS from v$session a, v$sqltext 9 SYS where a.sql_address = s.address (…partial output listing)
- 273. 273 Great V$ - V$SEGMENT_STATISTICS select object_name, statistic_name, value from v$segment_statistics where value > 100000 order by value; OBJECT_NAME STATISTIC_NAME VALUE ---------------------------- ------------------------------------- --------------- ORDERS space allocated 96551 ORDERS space allocated 134181 ORDERS logical reads 140976 ORDER_LINES db block changes 183600
- 274. 274 AWR – Segments by Buffer Busy Waits
- 275. 275 AWR – Segments by Logical Reads
- 276. 276 (Thanks: Veljko Lavrnic (VL), Scott Martin, Tirth (tink), Andy, Nitin, Kevin) Oracle Internals at the Block Level ; Beginners close your eyes! If time permits - Ohio 2011
- 277. 277 Current & CR Versions • Buffer hash table x$bh holds headers (hash chain protected by a CBC latch) point to db_block buffers in memory. • For a given block - Only one block is CURRENT and no more than 5 other CR versions of the block (as of V9). • For DML, you need the CURRENT version. • For query, you can use the CURRENT version if not being used and/or build a CONSISTENT READ (CR) version by applying and undo needed. This may include reading the ITL, mapping to the UNDO HEADER, but the ITL also maps directly to the UNDO BLOCK and applying the UNDO to get the correct CR version that you need. • Links for the LRU & LRU-W (working set used for buffer replacement) are maintained in the buffer headers.
- 278. 278 Biggest Problems • The SQL, of course… especially reads of full indexes, full table scans, bad table joins and others. • Hot blocks… hot blocks can cause latching issues. Bad SQL or bad indexes causes hot blocks (scanning through the same large index). Improved in 10g (shared latches). • Not enough freelists or not using ASSM. • Not enough initrans for multiple DML to the same block (pctfree not high enough to auto-generate). Or too many (each ITL costs 24 bytes). • Slow I/O subsystem or poor disk caching or not enough paths and readers/writers colliding. • Not on latest version so can‟t use great new features!
- 279. 279 Block Dumps
- 280. 280 Last Resort - Block Dumps SQL> desc emp1 Name Null? Type ---------------------------------------- -------- ---------------------------- EMPNO NUMBER(4) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2)
- 281. 281 Last Resort - Block Dumps select * from emp where ename = 'MILLER'; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- -------------- ------------ --------- ------------------- -------- ----------- -------------- 7934 MILLER CLERK 7782 23-JAN-82 1300 10
- 282. 282 Last Resort - Block Dumps select file_id, block_id, blocks from dba_extents where segment_name = 'EMP' and owner = 'SCOTT'; FILE_ID BLOCK_ID BLOCKS ----------- --------------- ------------ 1 50465 3
- 283. 283 Last Resort - Block Dumps ALTER SYSTEM DUMP DATAFILE 5 BLOCK 50465 / ALTER SYSTEM DUMP DATAFILE 5 BLOCK 50466 / ALTER SYSTEM DUMP DATAFILE 5 BLOCK 50467 / Or… ALTER SYSTEM DUMP DATAFILE 5 BLOCK MIN 50465 BLOCK MAX 50467; (Puts output in user_dump_dest)
- 284. 284 Block Dump… Getting the block number select rowid,empno, dbms_rowid.rowid_relative_fno(rowid) fileno, dbms_rowid.rowid_block_number(rowid) blockno, dbms_rowid.rowid_row_number(rowid) rowno, rownum, rpad(to_char(dbms_rowid.rowid_block_number(rowid), 'FM0xxxxxxx') || '.' || to_char(dbms_rowid.rowid_row_number (rowid), 'FM0xxx' ) || '.' || to_char(dbms_rowid.rowid_relative_fno(rowid), 'FM0xxx' ), 18) myrid from emp1; ROWID EMPNO FILENO BLOCKNO ROWNO ROWNUM ------------------ ---------- ---------- ---------- ---------- ---------- MYRID ------------------ AAAMfcAABAAAN0KAAA 7369 1 56586 0 1 0000dd0a.0000.0001 AAAMfcAABAAAN0KAAB 7499 1 56586 1 2 0000dd0a.0001.0001 AAAMfcAABAAAN0KAAC 7521 1 56586 2 3 0000dd0a.0002.0001
- 286. 286 Block Dumps – Top Section *** 2005-04-08 23:18:49.226 Start dump data blocks tsn: 0 file#: 1 minblk 56650 maxblk 56650 buffer tsn: 0 rdba: 0x0040dd4a (1/56650) scn: 0x0000.003dfa58 seq: 0x01 flg: 0x00 tail: 0xfa580601 frmt: 0x02 chkval: 0x0000 type: 0x06=trans data Block header dump: 0x0040dd4a Object id on Block? Y seg/obj: 0xce1c csc: 0x00.3dfa58 itc: 2 flg: O typ: 1 - DATA fsl: 0 fnx: 0x0 ver: 0x01 Scn block was last changed at ACTUAL Database Block Address Changes to block w/i scn Blocks that were dumped #ITL’s (see next slide)
- 287. 287 Block Dumps – Top Section Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0004.010.00000fba 0x0080003d.08b5.10 ---- 4 fsc 0x009d.00000000 0x02 0x0004.016.00000fae 0x008000cc.08af.34 C--- 0 scn 0x0000.003deb5b ITL – 2 Interested Transaction Lists Transaction ID Undo#.slot#.wrap# (Undo#,slot#,seq#) UBA: File.block(Undo dba).sequence.record Undo block address where last change is recorded. Rows Locked: 4 rows deleted for this xid in this block.
- 288. 288 Block Dumps – Top Section Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0004.010.00000fba 0x0080003d.08b5.10 ---- 4 fsc 0x009d.00000000 0x02 0x0004.016.00000fae 0x008000cc.08af.34 C--- 0 scn 0x0000.003deb5b Flag: No flag set then it’s uncommitted (----)/(CBUT) C---=Committed -B-- = The UBA contains undo for this itl --U-= Committed (scn is upper bound)…used by fast commits & delayed block cleanout has not occurred ---T = Transaction active at block cleanout SCN C-U- = Block cleaned by delayed block cleanout, and the rollback segment info overwritten. The scn will show the lowest scn that could be regenerated by the rollback segment.
- 289. 289 Block Dumps – Top Section Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0004.010.00000fba 0x0080003d.08b5.10 ---- 4 fsc 0x009d.00000000 0x02 0x0004.016.00000fae 0x008000cc.08af.34 C--- 0 scn 0x0000.003deb5b Scn/fsc: Fsc= Free Space Credit = 9d (hex) = 157 (decimal) bytes Scn = System change (commit) number
- 290. 290 Block Dumps – Top Section data_block_dump,data header at 0x5a1125c =============== tsiz: 0x1fa0 Total Size = 1fa0 = 8096 1 (hex) = 1 (decimal) x 16x16x16 = 4096 F (hex) = 15 (decimal) x 16x16 = 3840 A (hex) = 10 (decimal) x 16 = 160 0 (hex) = 0 (decimal) x 1 = 0 4096 + 3840 + 160 + 0 = 8096 (about 8K) hsiz: 0x2e Header Size = 2e = 46 bytes pbl: 0x05a1125c Pointer to block buffer holding the block bdba: 0x0040dd4a (Relative) database block address
- 291. 291 Block Dumps – Data Section ntab=1 Number of tables= 1 (2+ for clusters) nrow=14 Number of rows = 14 frre=-1 First free row index entry – 1 (add 1) fsbo=0x2e Free space begin offset fseo=0x18fb Free space end offset avsp=0x1d3b Available block space = 1d3b = 7483 tosp=0x1de0 Space avail. post commit=1de0=7648 0xe:pti[0] nrow=14 offs=0 Table Info 0x12:pri[0] offs=0x18fb (6395)Row Info Record 0 0x14:pri[1] offs=0x1921 (6433)Row Info Record 1 … Row Info Records 2–13 block_row_dump: Row Data is Next!
- 293. 293 Block Dumps – output from udump tab 0, row 13, @0x1b0b tl: 39 fb: --H-FL-- lb: 0x0 cc: 8 col 0: [ 3] c2 50 23 col 1: [ 6] 4d 49 4c 4c 45 52 col 2: [ 5] 43 4c 45 52 4b col 3: [ 3] c2 4e 53 col 4: [ 7] 77 b6 01 17 01 01 01 col 5: [ 2] c2 0e col 6: *NULL* col 7: [ 2] c1 0b…
- 294. 294 Block Dumps – Data Section DUMP OUTPUT: tab 0, row 13, @0x1b0b tl: 39 fb: --H-FL-- lb: 0x0 cc: 8 (row header) Table = this data is for table 0 Row 13 = 14th Row (0-13 total rows) Offset: 1b0b (in Hex) – Offset from header tl: Total bytes of row plus the header = 39
- 295. 295 Block Dumps – Data Section DUMP OUTPUT: tab 0, row 13, @0x1b0b tl: 39 fb: --H-FL-- lb: 0x0 cc: 8 fb: --H-FL-- = flag byte; ( -KCHDFLPN) H = Head of row piece, F = First data piece, L=Last piece D = Deleted; P= First column continues from previous piece (chaining) ; N= Last column continues in next piece; K = Cluster Key; C = Cluster table member
- 296. 296 Block Dumps – Data Section DUMP OUTPUT: tab 0, row 13, @0x1b0b tl: 39 fb: --H-FL-- lb: 0x0 cc: 8 Lb: lock byte is 1+ if this row is locked = 0 (unlocked) cc: Column count = 8
- 297. 297 Block Dumps – Deleted rows DUMP OUTPUT (Deleted Row): block_row_dump: tab 0, row 0, @0x18fb tl: 2 fb: --HDFL-- lb: 0x1 tab 0, row 1, @0x1921 tl: 2 fb: --HDFL-- lb: 0x1 Rows 1 &2 have been deleted! No row data is visible for the columns.
- 298. 298 Block Dumps – Data Section DUMP OUTPUT - EMPNO: col 0: [ 3] c2 50 23 Hex to Decimal: Col0 = EMPNO = 7934 50 (Hex) = 80 (Decimal) – 1 = 79 23 (Hex) = 35 (Decimal) – 1 = 34 c2: Number in the thousands (c2 is exponent)
- 299. 299 Block Dumps – Data Section DUMP OUTPUT - ENAME: col 1: [ 6] 4d 49 4c 4c 45 52 Hex to Character: Col1 = ENAME = MILLER 4d (Hex) = M (Character) 49 (Hex) = I (Character) 4c (Hex) = L (Character) 4c (Hex) = L (Character) 45 (Hex) = E (Character) 52 (Hex) = R (Character)
- 300. 300 Block Dumps – Data Section DUMP OUTPUT - JOB: col 2: [ 5] 43 4c 45 52 4b Hex to Character: Col2 = JOB = CLERK 43 (Hex) = C (Character) 4c (Hex) = L (Character) 45 (Hex) = E (Character) 52 (Hex) = R (Character) 4b (Hex) = K (Character)
- 301. 301 Block Dumps – Data Section DUMP OUTPUT - MGR: col 3: [ 3] c2 4e 53 Hex to Decimal: Col3 = MGR = 7782 4e (Hex) = 78 (Decimal) – 1 = 77 53 (Hex) = 83 (Decimal) – 1 = 82
- 302. 302 Block Dumps – Data Section DUMP OUTPUT - HIREDATE: col 4: [ 7] 77 b6 01 17 01 01 01 Hex to Decimal: Col4 = HIREDATE = 23-JAN-82 77 (Hex) = 119 (Decimal) – 100 = 19 B6 (Hex) = 182 (Decimal) – 100 = 82 01(Hex) = 1 (Decimal) <month> 17 (Hex) = 23 (Decimal) <day> 01 01 01 (Hex) = This is the Hour, Minute, Second (none were entered when the date was entered…default)
- 303. 303 Block Dumps – Data Section DUMP OUTPUT - SAL: col 5: [ 2] c2 0e Hex to Decimal: Col5 = SAL = 1300 0e (Hex) = 14 (Decimal) – 1 = 13 c2 = add two zero‟s
- 304. 304 Block Dumps – Data Section DUMP OUTPUT - COMM: col 6: *NULL* Hex to Decimal: Col6 = COMM = NULL NULL = NULL
- 305. 305 Block Dumps – Data Section DUMP OUTPUT - DEPTNO: col 7: [ 2] c1 0b Hex to Decimal: Col7 = DEPTNO= 10 0B (Hex) = 11 (Decimal) – 1 = 10 c1 = number in the tens
- 306. 306 Block Dump: Data Section – Other Ways
- 307. 307 Block Dump using SELECT dump() select dump(ename) from emp1 where ename='MILLER„; DUMP(ENAME) ------------------------------------------------------ Typ=1 Len=6: 77,73,76,76,69,82 Types: 1=varchar; 2=number; 12=date; 23=raw
- 308. 308 Block Dump using SELECT dump() Typ=1 Len=6: 77,73,76,76,69,82 Decimal to Character: ENAME = MILLER 77 (Decimal) = M (Character) 73 (Decimal) = I (Character) 76 (Decimal) = L (Character) 76 (Decimal) = L (Character) 69 (Decimal) = E (Character) 82 (Decimal) = R (Character)
- 309. 309 Block Dump using SELECT dump() (convert it to HEX if you want) select dump(ename.16) from emp1 where ename='MILLER„; DUMP(ENAME,16) ------------------------------------------------------ Typ=1 Len=6: 4d,49,4c,4c,45,52 Types: 1=varchar; 2=number; 12=date; 23=raw
- 310. 310 Block Dump using SELECT dump() (Can even get the ename from the HEX!) select dump(ename,16), ename from emp1 where dump(ename,16) like '%4d,49,4c,4c,45,52„; DUMP(ENAME,16) ENAME ---------------------------------------------- -------------- Typ=1 Len=6: 4d,49,4c,4c,45,52 MILLER
- 312. 312 Row Level Locks (Chain Latch) n 1 3 Cache Buffers Buffer Header Hash Buckets LRU Lists LRU Write List DB Write 1 2 3 Log Buffers User Request Shared Pool SGA Buffer Cache 2 Cache Layer 2 Transaction Layer XID 01 XID 02 2 Row 3 1 Row 1 1 Row 2 Lock Byte ITL 1 ITL 2 XID 01 ITL 1 Itl Xid Uba Flag Lck … 0x01 0x0005.02a.0000028c 0x008000af.026b.01 ---- 1 … usn# 0x02a 0x028c RBU Header 5 wrap# Data Block slot# XID 0X005.02a.0000028c Transaction Identifiers
- 313. (Chain Latch) n 1 2 3 Buffer Headers Buffer Header Hash Buckets Working with Hash Buckets And Buffer Headers (not buffers) • Users asks for a specific data block address. • This is hashed with a hashing algorithm and looks in the hash bucket that it hashes to. • It walks the hash chain using the cache buffers chain latch to find the block that it needs (curr or cr). There can be many versions of each block • Block maps to memory address
- 314. 314 _DB_BLOCK_HASH_BUCKETS and hashing data block addresses Example: _DB_BLOCK_HASH_BUCKETS (shouldn‟t have to change this in Oracle9i or 10g) • Buffer hash table (x$bh) has all buffer headers for all db_block buffers. • Buffer header ties to memory base address of the buffer. • Buckets usually set to Prime(2*db_block_buffers) • A prime number is often used to avoid hashing anomalies • Objects dba (class) is hashed to a hash bucket on the hash chain • Get enough hash buckets (_db_block_hash_buckets) • Blocks assigned to a hash bucket and onto the hash chain • Could have multiple blocks hashed to same chain (if both hot-issues) • Can have multiple versions of a block on same chain • When block is replaced (based on LRU chain) new block comes in and could be (probably will be) hashed to a different hash chain.
- 315. 315 Example: Emp Table Consider a user querying emp: • First block of emp may go to chain #1 • Second block of emp may go to chain #55 • If second block of emp is updated and also has several readers than we‟ll get more copies. LRBA – Lowest Redo Block Address (last redo applied) for dirty block. • Chain #55 may now have a current block and 2 CR blocks all with the same dba (data block address) • For a given block - Only one block is CURRENT and no more than 5 other CR versions of the block (as of V9). • All buffer headers tie to LRU, LRU-W and other LRU‟s (many in 10g) used for buffer replacement.
- 316. 316 Additional LRU‟s / Faster!! • LRU Main block replacement list • LRU-W Old dirty buffers and reco/temp • LRU-P Ping Buffer list / RAC • LRU-XO Buffers to be written for drop/truncate • LRU-XR Buffers to be written for reuse range • Thread CKPT Thread Checkpoint Queue • File CKPT File Checkpoint Queue • Reco CKPT Reco Checkpoint • LRU-MAIN & LRU-AUX help LRU
- 317. 317 Query all buffer headers (state): col status for a6 select state, decode(state, 0, 'FREE', /* not currently is use */ 1, 'XCUR', /* held exclusive by this instance */ 2, 'SCUR', /* held shared by this instance */ 3, 'CR', /* only valid for consistent read */ 4, 'READ', /* is being read from disk */ 5, 'MREC', /* in media recovery mode */ 6, 'IREC„, /* in instance(crash) recovery mode */ 7, „WRITE‟, /* being written */ 8, „PIN‟) status, count(*) /* pinned */ from x$bh group by state; STATE STATUS COUNT(*) ------------ ------------- ----------------- 1 XCUR 2001 -- CURRENT (CURR) 3 CR 3 -- CONSISTENT READ (CR)
- 318. 318 EMP1 is Block#: 56650 (all rows are in this block) select rowid,empno, dbms_rowid.rowid_relative_fno(rowid) fileno, dbms_rowid.rowid_block_number(rowid) blockno, dbms_rowid.rowid_row_number(rowid) rowno, rownum, rpad(to_char(dbms_rowid.rowid_block_number(rowid), 'FM0xxxxxxx') || '.' || to_char(dbms_rowid.rowid_row_number (rowid), 'FM0xxx' ) || '.' || to_char(dbms_rowid.rowid_relative_fno(rowid), 'FM0xxx' ), 18) myrid from emp1; ROWID EMPNO FILENO BLOCKNO ROWNO ROWNUM ------------------ ---------- ---------- ---------- ---------- ---------- MYRID ------------------ AAAM4cAABAAAN1KAAA 7369 1 56650 0 1 0000dd4a.0000.0001 AAAM4cAABAAAN1KAAB 7499 1 56650 1 2 0000dd4a.0001.0001 … … AAAM4cAABAAAN1KAAN 7934 1 56650 13 14 0000dd4a.000d.0001 14 rows selected.
- 319. 319 Let‟s watch the EMP1 buffer header (So far it‟s clean and only 1 copy) select lrba_seq, state, dbarfil, dbablk, tch, flag, hscn_bas,cr_scn_bas, decode(bitand(flag,1), 0, 'N', 'Y') dirty, /* Dirty bit */ decode(bitand(flag,16), 0, 'N', 'Y') temp, /* temporary bit */ decode(bitand(flag,1536), 0, 'N', 'Y') ping, /* ping (to shared or null) bit */ decode(bitand(flag,16384), 0, 'N', 'Y') stale, /* stale bit */ decode(bitand(flag,65536), 0, 'N', 'Y') direct, /* direct access bit */ decode(bitand(flag,1048576), 0, 'N', 'Y') new /* new bit */ from x$bh where dbablk = 56650 order by dbablk; LRBA_SEQ STATE DBARFIL DBABLK TCH FLAG HSCN_BAS ---------- ---------- ---------- ---------- ---------- ---------- ---------- CR_SCN_BAS D T P S D N ---------- - - - - - - 0 1 1 56650 0 35659776 4294967295 0 N N N N N N
- 320. Log Buffers (Chain Latch) n 1 2 3 Shared Pool SGA Cache Buffers Buffer Cache Buffer Header Hash Buckets Only ONE block on the Hash Chain!
- 321. 321 Let‟s watch the EMP1 buffer header (Delete a row) delete from emp1 where comm = 0; one row deleted.
- 322. 322 Let‟s watch the EMP1 buffer header (Make some changes 2 copies) select lrba_seq, state, dbarfil, dbablk, tch, flag, hscn_bas,cr_scn_bas, decode(bitand(flag,1), 0, 'N', 'Y') dirty, /* Dirty bit */ decode(bitand(flag,16), 0, 'N', 'Y') temp, /* temporary bit */ decode(bitand(flag,1536), 0, 'N', 'Y') ping, /* ping (to shared or null) bit */ decode(bitand(flag,16384), 0, 'N', 'Y') stale, /* stale bit */ decode(bitand(flag,65536), 0, 'N', 'Y') direct, /* direct access bit */ decode(bitand(flag,1048576), 0, 'N', 'Y') new /* new bit */ from x$bh where dbablk = 56650 order by dbablk; LRBA_SEQ STATE DBARFIL DBABLK TCH FLAG HSCN_BAS ---------- ---------- ---------- ---------- ---------- ---------- ---------- CR_SCN_BAS D T P S D N ---------- - - - - - - 0 1 1 56650 1 8200 4294967295 0 N N N N N N 0 3 1 56650 2 524288 0 4347881 N N N N N N
- 323. Log Buffers (Chain Latch) n 1 2 3 Shared Pool SGA Cache Buffers Buffer Cache Buffer Header Hash Buckets Hash Chain is now TWO! One is a CR and the other is Current.
- 324. 324 V$Transaction now has our record (created when transactions have undo) SELECT t.addr, t.xidusn USN, t.xidslot SLOT, t.xidsqn SQL, t.status, t.used_ublk UBLK, t.used_urec UREC, t.log_io LOG, t.phy_io PHY, t.cr_get, t.cr_change CR_CHA FROM v$transaction t, v$session s WHERE t.addr = s.taddr; ADDR USN SLOT SQL STATUS UBLK -------- ---------- ---------- ---------- ---------------- ---------- UREC LOG PHY CR_GET CR_CHA ---------- ---------- ---------- ---------- ---------- 69E50E5C 5 42 652 ACTIVE 1 1 3 0 3 0 USN is the Undo Segment Number (rollback segment ID) SLOT is the slot number in the rollback segment‟s transaction table. SQN (Wrap) is the sequence number for the transaction. USN+SLOT+SQN are the three values that uniquely identifies a transaction XID
- 325. 325 UBAFIL is the file for last undo entry UBLK is block for last undo entry (find out how many undo blocks). UBASQN is the sequence no of the last entry. UREC is the record number of the block( shows how many table and index entries the transaction has inserted, updated or deleted. If you are doing an INSERT or DELETE, then you will see that UREC is set to <number of indexes for this table> + how many rows you inserts/deletes. If you UPDATE a column then UREC will be set to <number of indexes that his column belongs to> * 2 + number of updated rows (so if the column belongs to no index, then UREC is set to the number of rows that was updated). If USED_UBLK and USED_UREC are decreasing each time you query, then the transaction is rolling back. When USED_UREC zero, the rollback is finished. V$Transaction (FYI Only)
- 326. 326 Dump the block Dump the block Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0005.02a.0000028c 0x008000af.02b6.01 ---- 1 fsc 0x0029.00000000 0x02 0x0004.016.00000fae 0x008000cc.08af.34 C--- 0 scn 0x0000.003deb5b ITL – 2 Interested Transaction Lists Transaction ID Undo 5 = 5 (decimal) Slot 2a = 42 (decimal) SEQ 28C = 652 UBA: File.block.sequence.record Undo block address where last change is recorded. The row I deleted is still locked; fsc is 0x29 = 41 bytes Committed Transaction
- 327. 327 Insert in 4 other sessions & drive x$bh up to the max of 6 versions of block LRBA_SEQ STATE DBARFIL DBABLK TCH FLAG HSCN_BAS ---------- ---------- ---------- ---------- ---------- ---------- ---------- CR_SCN_BAS D T P S D N ---------- - - - - - - 0 3 1 56650 1 524416 0 4350120 N N N N N N 0 3 1 56650 1 524416 0 4350105 N N N N N N 365 1 1 56650 7 33562633 4350121 0 Y N N N N N 0 3 1 56650 1 524416 0 4350103 N N N N N N 0 3 1 56650 1 524416 0 4350089 N N N N N N 0 3 1 56650 1 524288 0 4350087 N N N N N N
- 328. Log Buffers (Chain Latch) n 1 2 3 Shared Pool SGA Cache Buffers Buffer Cache Buffer Header Hash Buckets Hash Chain is now SIX long! Five CR and the one Current.
- 329. 329 Why only 6 versions of a Block? select a.ksppinm, b.ksppstvl, b.ksppstdf, a.ksppdesc from x$ksppi a, x$ksppcv b where a.indx = b.indx and substr(ksppinm,1,1) = '_' and ksppinm like '%&1%' order by ksppinm; KSPPINM ------------------------------------------------------------------------------- KSPPSTVL ------------------------------------------------------------------------------- KSPPSTDF --------- KSPPDESC ------------------------------------------------------------------------------- _db_block_max_cr_dba 6 TRUE Maximum Allowed Number of CR buffers per dba
- 330. 330 User 1 – Updates Row# 1&2 Log Buffers Shared Pool SGA Buffer Cache User 3 Updates Row# 3 Cache Layer 2 Transaction Layer XID 01 XID 02 2 Row 3 1 Row 1 1 Row 2 Lock Byte ITL 1 ITL 2 User1 Request User3 Request XID 02 ITL 2 Row 3 2 Row 3 • User1 updates 2 rows with an insert/update/delete – an ITL is opened and xid tracks it in the data block (lock byte is set on row). • The xid ties to the UNDO header block which ties to the UNDO data block for undo. • If user2 wants to query the row, they create a clone and rollback the transaction going to the undo header and undo block. • If user3 wants to update same row (they wait). If user 3 wants to update different row, then they open a second ITL with an xid that maps to an undo header & maps to an undo block.
- 331. 331 Create EMP2 („MILLER‟/‟ALLEN‟) create table emp2 asselect * from emp1 where ename in ('MILLER','ALLEN'); select empno, ename, job from emp2; EMPNO ENAME JOB -------------- -------------- --------------------- 7499 ALLEN SALESMAN 7934 MILLER CLERK
- 332. 332 Get the Blockno for EMP2 select rowid,empno, dbms_rowid.rowid_relative_fno(rowid) fileno, dbms_rowid.rowid_block_number(rowid) blockno, dbms_rowid.rowid_row_number(rowid) rowno, rownum, rpad(to_char(dbms_rowid.rowid_block_number(rowid), 'FM0xxxxxxx') || '.' || to_char(dbms_rowid.rowid_row_number (rowid), 'FM0xxx' ) || '.' || to_char(dbms_rowid.rowid_relative_fno(rowid), 'FM0xxx' ), 18) myrid from emp2; ROWID EMPNO FILENO BLOCKNO ROWNO ROWNUM ------------------ ---------- ---------- ---------- ---------- ---------- MYRID ------------------ AAANB2AABAAAOHSAAA 7499 1 57810 0 1 0000e1d2.0000.0001 AAANB2AABAAAOHSAAB 7934 1 57810 1 2 0000e1d2.0001.0001
- 333. 333 Dump the EMP2 block (Partial) Alter system dump datafile 2 block 57810; System Altered. *** SESSION ID:(154.36) 2005-04-25 23:24:22.865 Start dump data blocks tsn: 0 file#: 1 minblk 57810 maxblk 57810 buffer tsn: 0 rdba: 0x0040e1d2 (1/57810) scn: 0x0000.00432370 seq: 0x02 flg: 0x04 tail: 0x23700602 frmt: 0x02 chkval: 0xb205 type: 0x06=trans data Block header dump: 0x0040e1d2 Object id on Block? Y seg/obj: 0xd076 csc: 0x00.43236f itc: 3 flg: - typ: 1 - DATA fsl: 0 fnx: 0x0 ver: 0x01 Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000 0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
- 334. 334 Dump the EMP2 block (Partial) block_row_dump: tab 0, row 0, @0x1f5d tl: 43 fb: --H-FL-- lb: 0x0 cc: 8 col 0: [ 3] c2 4b 64 col 1: [ 5] 41 4c 4c 45 4e A L L E N col 2: [ 8] 53 41 4c 45 53 4d 41 4e col 3: [ 3] c2 4d 63 col 4: [ 7] 77 b5 02 14 01 01 01 col 5: [ 2] c2 11 col 6: [ 2] c2 04 col 7: [ 2] c1 1f
- 335. 335 Dump the EMP2 block (Partial) tab 0, row 1, @0x1f36 tl: 39 fb: --H-FL-- lb: 0x0 cc: 8 col 0: [ 3] c2 50 23 col 1: [ 6] 4d 49 4c 4c 45 52 M I L L E R col 2: [ 5] 43 4c 45 52 4b col 3: [ 3] c2 4e 53 col 4: [ 7] 77 b6 01 17 01 01 01 col 5: [ 2] c2 0e col 6: *NULL* col 7: [ 2] c1 0b end_of_block_dump
- 336. 336 Update „MILLER‟ to „SMALL‟ update emp2 set ename = „SMALL‟ where ename = 'MILLER'; select empno, ename, job from emp2; EMPNO ENAME JOB -------------- -------------- --------------------- 7499 ALLEN SALESMAN 7934 SMALL CLERK
- 337. 337 Dump the EMP2 block (Partial) Alter system dump datafile 2 block 57810; System Altered. Start dump data blocks tsn: 0 file#: 1 minblk 57810 maxblk 57810 buffer tsn: 0 rdba: 0x0040e1d2 (1/57810) scn: 0x0000.00432794 seq: 0x05 flg: 0x00 tail: 0x27940605 frmt: 0x02 chkval: 0x0000 type: 0x06=trans data Block header dump: 0x0040e1d2 Object id on Block? Y seg/obj: 0xd076 csc: 0x00.43236f itc: 3 flg: O typ: 1 - DATA fsl: 0 fnx: 0x0 ver: 0x01 Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0004.02a.000012ff 0x00800353.0a9e.07 ---- 1 fsc 0x0001.00000000 0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
- 338. 338 Here is the ITL with our Transaction Itl Xid Uba Flag Lck Scn/Fsc 0x02 0x0004.02a.000012ff 0x00800353.0a9e.07 ---- 1 fsc 0x0001.00000000 Transaction ID Undo 4 = 4 (decimal) Slot 2a = 42 (decimal) Seq 12ff = 4863 (decimal) UBA: File.block.sequence.record Undo block address where last change is recorded. The row that was updated is still locked; fsc is 0x1 = 1 bytes
- 339. 339 Find the Segment & Location of RBS select segment_name from dba_rollback_segs where segment_id = 4; SEGMENT_NAME ------------------------------ _SYSSMU4$ select header_file, header_block from dba_segments where segment_name = „_SYSSMU4$‟; HEADER_FILE HEADER_BLOCK -------------------------- ------------------------------ 2 57
- 340. 340 Dump the UNDO Header (Partial) Transaction Table (last modified blk)! Alter system dump datafile 2 block 57; System Altered. TRN TBL:: index state cflags wrap# uel scn dba (uba) parent-xid nub stmt_num cmt ----------------------------------------------------------------------- ------------------------- 0x00 9 0x00 0x12ff 0x0001 0x0000.00432687 0x0080034e 0x0000.000.00000000 0x00000001 0x00000000 1114490213 0x01 9 0x00 0x12ff 0x0002 0x0000.0043269d 0x0080034e 0x0000.000.00000000 0x00000001 0x00000000 1114490272 ... 0x29 9 0x00 0x12ff 0x0028 0x0000.004327a4 0x00800353 0x0000.000.00000000 0x00000001 0x00000000 1114490829 0x2a 10 0x80 0x12ff 0x0002 0x0000.00432795 0x00800353 0x0000.000.00000000 0x00000001 0x00000000 0 … End dump data blocks tsn: 1 file#: 2 minblk 57 maxblk 57
- 341. 341 Dump the UNDO Header (Partial) Transaction Table! index state cflags wrap# uel scn dba --------------------------------------------------------------- 0x2a 10 0x80 0x12ff 0x0002 0x0000.00432795 0x00800353 State: State 10 is Uncommitted Wrap/Seq: The Wrap is 12ff The scn for uncommitted (ours is) or committed transactions Slot: The Slot was 2a which was the 42nd in the list. The dba of the undo which we need to look in.
- 342. 342 The ITL again… (fyi to see UBA) Itl Xid Uba Flag Lck Scn/Fsc 0x02 0x0004.02a.000012ff 0x00800353.0a9e.07 ---- 1 fsc 0x0001.00000000 Transaction ID Undo 4 = 4 (decimal) Slot 2a = 42 (decimal) Seq 12ff = 4863 (decimal) UBA: File.block.sequence.record Undo block address where last change is recorded. The row that was updated is still locked; fsc is 0x1 = 1 bytes
- 343. 343 Find the Segment & Location of RBS SELECT DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE( TO_NUMBER('00800353','XXXXXXXX')) UFILE FROM DUAL; UFILE ----------- 2 SELECT DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK( TO_NUMBER('00800353','XXXXXXXX')) BLOCK FROM DUAL BLOCK ------------ 851 Alter system dump datafile 2 block 851; System altered.
- 344. 344 Dump the UNDO Block (Partial) ******************************************************************************** UNDO BLK: xid: 0x0004.02a.000012ff seq: 0xa9e cnt: 0x7 irb: 0x7 icl: 0x0 flg: 0x0000 ... Rec #0x7 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: … uba: 0x00800353.0a9e.04 ctl max scn: 0x0000.00432655 prv tx scn: 0x0000.00432656 txn start scn: scn: 0x0000.00432731 logon user: 0 prev brb: 8389454 prev bcl: 0 KDO undo record: KTB Redo op: 0x03 ver: 0x01 op: Z KDO Op code: URP row dependencies Disabled xtype: XA flags: 0x00000000 bdba: 0x0040e1d2 hdba: 0x0040e1d1 itli: 2 ispac: 0 maxfr: 4863 tabn: 0 slot: 1(0x1) flag: 0x2c lock: 0 ckix: 0 ncol: 8 nnew: 1 size: 1 col 1: [ 6] 4d 49 4c 4c 45 52 Here‟s the UNDO: M I L L E R
- 345. 345 Update „ALLEN‟ to „BIG‟ update emp2 set ename = „BIG‟ where ename = „ALLEN‟; select empno, ename, job from emp2; EMPNO ENAME JOB -------------- -------------- --------------------- 7499 BIG SALESMAN 7934 SMALL CLERK
- 346. 346 The ITL again… (fyi to see UBA) Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0004.02a.000012ff 0x00800353.0a9e.08 ---- 2 fsc 0x0003.00000000 0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000 UBA: We’re now at Record 8. Two updates for the same user uses the same ITL. Now save 3 bytes if we commit.
- 347. 347 Dump the UNDO Block (Partial) ******************************************************************************** UNDO BLK: xid: 0x0004.02a.000012ff seq: 0xa9e cnt: 0x7 irb: 0x7 icl: 0x0 flg: 0x0000 ... * Rec #0x7 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: 0(0x00000000) *----------------------------- uba: 0x00800353.0a9e.04 ctl max scn: 0x0000.00432655 prv tx scn: 0x0000.00432656 txn start scn: scn: 0x0000.00432731 logon user: 0 KDO undo record: KTB Redo ... col 1: [ 6] 4d 49 4c 4c 45 52 UNDO RECORD: M I L L E R * Rec #0x8 slt: 0x2a objn: 53366(0x0000d076) objd: 53366 tblspc: 0(0x00000000) *----------------------------- KDO undo record: KTB Redo op: C uba: 0x00800353.0a9e.07 ... col 1: [ 5] 41 4c 4c 45 4e UNDO RECORD: A L L E N End dump data blocks tsn: 1 file#: 2 minblk 851 maxblk 851
- 348. 348 Now insert some records as user2 insert into emp2 select * from emp1‟; 14 rows created. Alter system dump datafile 1 block 57810; System altered.
- 349. 349 Here is the ITL with our Transaction Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0004.02a.000012ff 0x00800353.0a9e.08 ---- 2 fsc 0x0003.00000000 0x03 0x0005.00e.0000029b 0x008005b2.02c9.19 ---- 14 fsc 0x0000.00000000 Transaction ID Now there are 2 ITL’s in use. Undo 4,5 = 4,5 (decimal) UBA: 2 Undo Headers are used & 2 Undo blocks are referenced. 2 rows were updated on one ITL and 14 are inserted on the other.
- 350. 350 Let‟s check V$TRANSACTION & match it up to ITL (no need to dump) select xidusn, xidslot, xidsqn, ubafil, ubablk, ubasqn, ubarec from v$transaction t, v$session s where t.ses_addr = s.saddr; XIDUSN XIDSLOT XIDSQN UBAFIL UBABLK UBASQN UBAREC ---------- ---------- ---------- ---------- ---------- ---------- ---------- 4 42 4863 2 851 2718 8 5 14 667 2 1458 713 25 4.42.4863 = 4.2a.12ff 2.851.2718.8 = 800353.a9e.8 5.14.667 = 5.e.29b 2.1458.713.25 = 8005b2.2c9.19 Itl Xid Uba Flag Lck Scn/Fsc 0x02 0x0004.02a.000012ff 0x00800353.0a9e.08 ---- 2 fsc 0x0003.00000000 0x03 0x0005.00e.0000029b 0x008005b2.02c9.19 ---- 14 fsc 0x0000.00000000
- 351. 351 Row Level Locks (Chain Latch) n 1 3 Cache Buffers Buffer Header Hash Buckets LRU Lists LRU Write List DB Write 1 2 3 Log Buffers User Request Shared Pool SGA Buffer Cache 2 Cache Layer 2 Transaction Layer XID 01 XID 02 2 Row 3 1 Row 1 1 Row 2 Lock Byte ITL 1 ITL 2 XID 01 ITL 1 Itl Xid Uba Flag Lck … 0x01 0x0005.02a.0000028c 0x008000af.026b.01 ---- 1 … usn# 0x02a 0x028c RBU Header 5 wrap# Data Block slot# XID 0X005.02a.0000028c Transaction Identifiers
- 352. 352 Commit EVERYTHING! Commit; (all sessions) Alter system dump datafile 1 block 57810; System altered. Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0004.02a.000012ff 0x00800353.0a9e.08 ---- 2 fsc 0x0003.00000000 0x03 0x0005.00e.0000029a 0x008005b2.02c9.19 ---- 14 fsc 0x0000.00000000 Why no Change (show uncommitted)?? Delayed Block Cleanout! (Usually fast commit)
- 353. 353 Delayed block cleanout… Select * from emp2; (delayed block cleanout is how redo can be generated from a select) Alter system dump datafile 1 block 57810; System altered. Itl Xid Uba Flag Lck Scn/Fsc 0x01 0xffff.000.00000000 0x00000000.0000.00 C--- 0 scn 0x0000.0043236f 0x02 0x0004.02a.000012ff 0x00800353.0a9e.08 C--- 0 scn 0x0000.0043469f 0x03 0x0005.00e.0000029a 0x008005b2.02c9.19 C--- 0 scn 0x0000.004346a3 All records now show as committed.
- 354. 354 Delayed block cleanout… If a dirty block has already been written to disk (could also be due to locking or when many blocks are changed), then the next process to visit the block will automatically check the transaction entry in the undo segment header and find the changes made to the block have been commited. The process gets the SCN of the commit from the undo header transaction entry and writes it to the data block header to record the change as commited.
- 355. 355 What‟s Next? Indexes (Draft) – FYI quick look...
- 356. 356 Bitmap Indexes row#0[8010] flag: ---D-, lock: 2 col 0; len 1; (1): 31 col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 07 col 3; len 1; (1): 00 row#1[7989] flag: ---D-, lock: 2 col 0; len 1; (1): 31 col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 07 col 3; len 2; (2): c8 03 row#2[7968] flag: -----, lock: 2 col 0; len 1; (1): 31 col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 07 col 3; len 2; (2): c8 07 Indexed value consist of 5 lines: row#0: Row identification col 0: Indexed value - length in hex. col 1: Rowid for the first occurrence of the indexed value. col 2: Rowid for the last occurrence of the indexed value col 3: Actual bitmap which will have 1 where value occurred in range between first and last rowid, otherwise 0 in swap byte notification, first byte usually cx where x in (8,…,f). When all slots for cf filled, new segment starts. Oracle engine will place a lock on blocks containing indexed value.
- 357. 357 Insert 64 records / Dump is taken: row#0[8008] flag: -----, lock: 0 col 0; len 1; (1): 31 col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 3f col 3; len 9; (9): cf ff ff ff ff ff ff ff ff Another insert: row#0[8007] flag: -----, lock: 0 col 0; len 1; (1): 31 col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 40 col 3; len 10; (10): cf ff ff ff ff ff ff ff ff 00 Bitmap Indexes
- 358. 358 00 will represent first record in a range, i.e.: col 1; len 6; (6): 02 40 2d 60 00 00 col 2; len 6; (6): 02 40 2d 60 00 40 col 3; len 10; (10): cf ff ff ff ff ff ff ff ff 00 Index value exist in a block which rowid=02 40 2d 60 00 40 (40(hex) => 64 (decimal)). Previous end rowid was 3f (3*16+15 = 63). When index is updated there must be enough space to accommodate growth, if there is no space, split will occur. Not just that, lock will be placed on entry in leaf index. But this entry can span over multiple blocks. As a side effect for a duration of a lock no other transaction will be able to update blocks in affected block range. Bitmap indexes are used for a column with just a few different values, so on a bigger tables their bitmap will likely cover quite a few blocks, lock placed on those will have disastrous effect on other transaction. Bitmap Indexes
- 359. 359 Regular index entry was: col 0; len 2; (2): c1 02 col 1; len 7; (7): 78 69 0c 19 03 27 10 col 2; len 6; (6): 02 40 2e 70 00 00 Reverse key: col 0; len 2; (2): 02 c1 col 1; len 7; (7): 10 27 03 19 0c 69 78 col 2; len 6; (6): 02 40 2e 70 00 00 Reverse key index will be marked with value NORMAL/REV in dba_indexes(index_type). Reverse Key Indexes
- 360. 360 Trace file on regular index: col 0; len 1; (1): 61 col 0; len 2; (2): 61 61 col 0; len 3; (3): 61 61 61 col 0; len 4; (4): 61 61 61 61 col 0; len 5; (5): 61 61 61 61 61 col 0; len 6; (6): 61 61 61 61 61 61 col 0; len 7; (7): 61 61 61 61 61 61 61 col 0; len 8; (8): 61 61 61 61 61 61 61 61 col 0; len 9; (9): 61 61 61 61 61 61 61 61 61 col 0; len 10; (10): 61 61 61 61 61 61 61 61 61 61 Trace file on descending index: col 0; len 10; (10): 9e 9e 9e 9e 9e 9e 9e 9e 9e ff col 0; len 9; (9): 9e 9e 9e 9e 9e 9e 9e 9e ff col 0; len 8; (8): 9e 9e 9e 9e 9e 9e 9e ff col 0; len 7; (7): 9e 9e 9e 9e 9e 9e ff col 0; len 6; (6): 9e 9e 9e 9e 9e ff col 0; len 5; (5): 9e 9e 9e 9e ff col 0; len 4; (4): 9e 9e 9e ff col 0; len 3; (3): 9e 9e ff col 0; len 2; (2): 9e ff Ascending / Descending Index
- 361. 361 Grid Control – Find Problems FAST *** TEST SCENARIO *** Top Activity Shows Lots of Waiting Issues with Locking
- 362. 362 Top Activity says BIG PROBLEMS Almost 200 users are Active We have some DML Issues
- 363. 363 Top SQL #1 Details – Locking Issue Tax Package shows row lock enqueue issue MANY users are dividing the activity
- 364. 364 Histogram for Enqueues – Long Waits LONG waits for the TX row lock
- 365. 365 Top SQL #2 – Update Statement The query in the causing the locks
- 366. 366 Top SQL #3 – Insert Statement The application is causing BIG problems Now there are over 400 active users
- 367. 367 Top SQL #3 – Insert Statement Enqueue waits related to ITL allocations The Insert into one of the TAX Tables ITL issues Some minor RAC gc issues
- 368. 368 Grid Control – Find Problems FAST *** TEST SCENARIO *** Go to other Tools to Verify & Advise: ADDM Hang Analysis ASH
- 369. 369 Go to ADDM to get Verify & Advise <5 minutes later> ADDM sees the row contention for the Update
- 370. 370 Grid Control Lessons Learned Specific Update Statement for Tuning Results Suggests to gather statistics
- 371. 371 ASH Report – Points to same issues! ASH Report For (9:12 AM) ... <17 minutes later to verify> (1 Report Target Specified) DB Name DB Id Instance Inst num Release RAC Host DBRJN 277251124 ORA10 2 10.2.0.3.0 YES linux2 CPUs SGA Size Buffer Cache Shared Pool ASH Buffer Size 8 6,000M (100%) 1,536M (25.6%) 1,025M (17.1%) 29.0M (0.5%) Top User Events Event Event Class % Activity Avg Active Sessions enq: TX - row lock contention Application 99.33 146.11 Top SQL Statements SQL ID Planhash % Activity Event % Event SQL Text F9s5jwdq1j0hz 3197038047 97.32 enq: TX - row lock contention 97.32 UPDATE ASO_QUOTE_HEADERS_ALL S...
- 372. 372 Go to Hang Analysis & Verify the Pain! <stay ahead of the problem> All these Red & Yellow Colors are NOT a good sign!
- 373. 373 Pent-up Demand will crush the system
- 374. 374 After SOME table fixes & other fixes... Pent-up Demand causes instant SPIKE! Within a single minute we have 140 users waiting After 10 minutes there are 240 users waiting
- 375. 375 Queueing Pattern – No problem Spikes up and then back down regularly
- 376. 376 Queue / De-Queue Process Spikes up and then back down regularly Can watch performance
- 377. 377 RMAN runs then finishes... Note the RMAN sessions running Eventually ended
- 378. 378 Temp Space Issue averted ... Critical Temp Space Issue Added space
- 379. 379 Table Growth Issue... HW Enqueue Insert causing issues with table growth Issue is High Water Mark on the Table
- 380. 380 Temp Space Issue – TS Enqueue 3rd worst query is a Temp Space (TS) issue
- 381. 381 TCP Socket (KGAS) Time to search for another job
- 382. 382 Tuning Multiple Nodes Are all the Nodes up in the Cluster? 5 Nodes All Up! 2 Nodes Down 1 Starting up!
- 383. 383 Tuning the RAC Cluster Interconnect – Guidelines for GES Statistics: • All times should be < 15ms • Ratio of global lock gets vs global lock releases should be near 1.0 – High values could indicate possible network or memory problems – Could also be caused by application locking issues – May need to review the enqueue section of STATSPACK report for further analysis. Complete Presentation by Oracle’s Rich Niemiec’s at: http://www.oracleracsig.org
- 384. 384 Tuning the RAC Cluster Interconnect Using AWR Reports (FYI Only)
- 385. 385 Tuning the RAC Cluster Interconnect Using AWR Reports (FYI Only)
- 386. 386 High Availability Handle Issues that Bring Nodes Down
- 387. 387 Grid Control – One Node goes Down Issues arise that must be fixed Memory issues cause a node to go down
- 388. 388 Grid Control – 2nd Node goes Down Issues continue and get worse A 2nd node goes down
- 389. 389 Grid Control – 3rd Node goes Down Issues continue to get worse A 3rd node goes down
- 390. 390 Grid Control – Rolling Availability Memory Issue is resolved First node is back up and carrying the load
- 391. 391 Node being Evicted NOT Lack of CPU... Interconnect Failure Log Files: $CRS_HOME/log/inst1/cssd/ocssd.log - node 1 $CRS_HOME/log/inst2/cssd/ocssd.log - node 2 If you look at the log file on node 1, which was the master node at that time, you will see : [ CSSD]2007... >WARNING: clssnmPollingThread: node inst2 (2) at 50% heartbeat fatal, eviction in 29.730 seconds [ CSSD]2007... >WARNING: clssnmPollingThread: node inst2 (2) at 75% heartbeat fatal, eviction in 14.710 seconds [ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 5.690 seconds [ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 4.690 seconds [ CSSD]2007...>TRACE: clssnmPollingThread: node inst2 (2) is impending reconfig [ CSSD]2007...>WARNING: clssnmPollingThread: node inst2 (2) at 90% heartbeat fatal, eviction in 3.680 seconds [ CSSD]2007...>TRACE: clssnmPollingThread: diskTimeout set to (57000)ms impending reconfig status(1) ...etc [ CSSD]2007...>TRACE: clssnmReadDskHeartbeat: node(2) is down. rcfg(17) ...Disk lastSeqNo(1038569) [ CSSD]2007...>TRACE: clssnmCheckDskInfo: node(2) disk HB found, network state 0, disk state(3) misstime(770) [ CSSD]2007...>TRACE: clssnmReadDskHeartbeat: node(2) is down. rcfg(17) ... Disk lastSeqNo(1038570) [ CSSD]2007...>TRACE: clssnmCheckDskInfo: node(2) misstime(760) state(0). Smaller(1) cluster node 2. mine is 3. (2/1) [ CSSD]2007...>TRACE: clssnmEvict: Start [ CSSD]2007...>TRACE: clssnmEvict: Evicting node 2, birth 10, death 17, killme 1 [ CSSD]2007...>TRACE: clssnmEvict: Evicting Node(2), timeout(190)
- 392. 392 Grid Control – Availability Tracking how the system is doing...
- 393. 393 Grid Control – Adding Comments When you are taking outage you can add comments / reasons. When you get an alert, go to Grid Control page for target & edit/update/acknowledge the alerts and add comments to it . Add a comment...
- 394. 394 If Time Permits… the Future!
- 395. 395 64-Bit advancement of Directly addressable memory Address Direct Indirect/Extended • 4 Bit: 16 (640) • 8 Bit: 256 (65,536) • 16 Bit: 65,536 (1,048,576) • 32 Bit: 4,294,967,296 • 64 Bit: 18,446,744,073,709,551,616 • When the hardware physically implements the theoretical possibilities of 64-Bit, things will dramatically change…. …moving from 32 bit to 64 bit will be like moving from 4 bit to 32 bit or like moving from 1971 to 2000 overnight.
- 396. You could stack documents from the Earth so high they would pass Pluto! Stack single sheets (2K worth of text on each) about 4.8B miles high to get 16E!! 64bit allows Directly Addressing 16 Exabytes of Memory
- 397. 397 2K – A typewritten page 5M – The complete works of Shakespeare 10M – One minute of high fidelity sound 2T – Information generated on YouTube in one day 10T – 530,000,000 miles of bookshelves at the Library of Congress 20P – All hard-disk drives in 1995 (or your database in 2010) 700P –Data of 700,000 companies with Revenues less than $200M 1E – Combined Fortune 1000 company databases (average 1P each) 1E –Next 9000 world company databases (average 100T each) 8E – Capacity of ONE Oracle11g Database (CURRENT) 12E to 16E – Info generated before 1999 (memory resident in 64-bit) 16E – Addressable memory with 64-bit (CURRENT) 161E – New information in 2006 (mostly images not stored in DB) 1Z – 1000E (Zettabyte - Grains of sand on beaches -125 Oracle DBs) 100TY - 100T-Yottabytes – Addressable memory 128-bit (FUTURE) The Future: 8 Exabytes Look what fits in one 11g Database!
- 398. 398 What we covered: • Kramer‟s missing Backup • George‟s Untuned System • Elaine‟s Untouched System • Jerry‟s Perfect Tuning Plan • Statspack / AWR – Top Waits – Load Profile – Latch Waits – Top SQL – Instance Activity – File I/O • The Future: EM & ADDM • Helpful V$/X$ /(Mutexes) • Exa-Products & Summary
- 399. 399 Questions??
- 400. “Perfection is achieved, not when there is nothing left to add, but when there is nothing left to take away.” --Antoine de Saint Exupery
- 401. Compelling Technology Statistics! 0 5 10 15 20 25 30 35 40 Radio TV Cable Internet Wireless Years to Reach 50M Users
- 402. 402 Friedman’s 6 Dimensions of Understanding Globalization* • Politics (Merging) • Culture (Still disparate) • Technology (Merging/Merged) • Finance (Merging/Merged) • National security (Disparate) • Ecology (Merging) * Sited from Mark Hasson, PSU, Global Pricing and International Marketing.
- 403. 403 Rich Niemiec, Rolta TUSC (www.roltatusc.com.au) Oracle 声明: 以下介绍的Oracle产品方向,仅作参考,不具备法律效力,不承诺提 供任何材料、代码或功能,不应作为采购决策依据。Oracle有权自行决定产品 开发、发布和任何功能特性的时间表。 11g最佳新特性 Open World 2007 (基于11g Beta)
- 404. 404
- 405. 405 Know the DBA Mind!
- 406. 406 Before they were DBAs, they were Engineers
- 407. 407 This is How DBA View Themselves!
- 408. 408 Be a Better DBA to the Business! Do Developers think of this when they think of their Data
- 409. 409 Statspack – 仍然有用 一些10g 新特性 开发者想到DBA时,是否就像这样? Data
- 410. 410 Future DBA!
- 411. 411 V$ Views over the years Version V$ Views X$ Tables 6 23 ? (35) 7 72 126 8.0 132 200 8.1 185 271 9.0 227 352 9.2 259 394 10.1.0.2 340 (+31%) 543 (+38%) 10.2.0.1 396 613 11.1.0.6.0 484 (+23%) 798 (+30%) 11.2.0.1.0 496 (+25%) 945 (+54%)
- 412. 412 MARK YOUR CALENDARS! COLLABORATE 12 April 22-26, 2012 Mandalay Bay Convention Center Las Vegas, Nevada http://events.ioug.org/p/cm/ld/fid=15
- 413. 413 • www.tusc.com • Oracle 10g Performance Tuning Tips & Techniques; Richard J. Niemiec; Oracle Press (June 2007) • Oracle 11g Release 2 Performance Tuning Tips & Techniques (Early 2012) “If you are going through hell, keep going” - Churchill For More Information
- 414. 414 更多信息 • www.tusc.com • Oracle9i Performance Tuning Tips & Techniques; Richard J. Niemiec; Oracle Press (May 2003) • Oracle 10g Tuning (June 11, 2007) “成功只访问那些没空追求它的人。” - Henry David Thoreau
- 415. 415 References • www.tusc.com, www.oracle.com, www.ixora.com, www.laoug.org, www.ioug.org, technet.oracle.com • Oracle 9i, 10g, 11g documentation • Oracle10g Performance Tuning Tips & Techniques, Rich Niemiec • Oracle PL/SQL Tips and Techniques, Joseph P. Trezzo; Oracle Press • Oracle9i Web Development, Bradley D. Brown; Oracle Press • Special thanks to Steve Adams, Mike Ault, Brad Brown, Kevin Gilpin, Herve Lejeune, Randy Swanson and Joe Trezzo. • Dedicated to the memory of Stan Yellott, Mark Beaton, Ray Mansfield, Lex De Haan, Elaine DeMeo and Jim Gray.
- 416. 416 References • The Self-managing Database: Automatic Performance Diagnosis; Karl Dias & Mark Ramacher, Oracle Corporation • EM Grid Control 10g; otn.oracle.com, Oracle Corporation • Oracle Database 10g Automated Features , Mike Ault, TUSC • Oracle Enterprise Manager 10g: Making the Grid a Reality; Jay Rossiter, Oracle Corporation • The Self-Managing Database: Guided Application and SQL Tuning; Benoit Dageville, Oracle Corporation • The New Enterprise Manager: End to End Performance Management of Oracle; Julie Wong & Arsalan Farooq, Oracle Corporation • Enterprise Manager : Scalable Oracle Management; John Kennedy, Oracle Corporation
- 417. 417 References • www.tusc.com. www.rolta.com • Oracle10g Performance Tuning Tips & Techniques; Richard J. Niemiec; Oracle Press • Database Secure Configuration Initiative: Enhancements with Oracle Database 11g, www.oracle.com • All Oracle11g Documentation from Oracle Beta Site • Introduction to Oracle Database 11g, Ken Jacobs • Oracle Database 11g New Features, Linda Smith • New Optimizer Features in 11g, Maria Colgan • www.ioug.org, www.oracle.com, en.wikipedia.org & technet.oracle.com • Thanks Dan M., Bob T., Brad, Joe, Heidi, Mike K., Debbie, Maria, Linda • All companies and product names are trademarks or registered trademarks of the respective owners. • Dedicated to the memory of Robert Delgado Patton, Stan Yellott, Mark Beaton, Ray Mansfield, Lex De Haan, Elaine DeMeo and Jim Gray.
- 418. 418 V$ View Poster – At the Rolta Booth!
- 419. 419 Rolta TUSC – Your Partner …. Accomplished in Oracle! 2011 Oracle Partner of the Year (8 Titans Total) Prior Years Winner 2002, 2004*, 2007*, 2008, 2011 *Won 2 Awards
- 420. 420 Rolta TUSC Services • Oracle – E-Business Suite implementation, R12 upgrades, migration & support – Fusion Middleware and Open Systems development – Business Intelligence (OBIEE) development – Hyperion Financial Performance Management – DBA and Database tactical services – Strategic Global Sourcing • IT Infrastructure – IT Roadmap - Security & Compliance - Infrastructure Management – Enterprise Integration / SOA - High Availability and Disaster Planning • Profitability & Cost Management – Financial Consolidation - Budgeting & Forecasting – Profitability & Risk Analysis - Enterprise Performance Management – Operational, Financial & Management Reporting • Rolta Software Solutions – iPerspective™ - rapid data & systems integration – Geospatial Fusion™ - spatial integration & visualization – OneView™ - business & operational intelligence
- 421. 421 Copyright Information • Neither Rolta TUSC nor the author guarantee this document to be error-free. Please provide comments/questions to rich@tusc.com. I am always looking to improve! • Rich Niemiec/ Rolta TUSC © 2011. This document cannot be reproduced without expressed written consent from Rich Niemiec or an officer of Rolta TUSC, but may be reproduced or copied for presentation/conference use. Contact Information Rich Niemiec: rich@tusc.com www.tusc.com
- 422. 422 Rich‟s Overview (rich@tusc.com) • Advisor to Rolta International Board • Former President of TUSC – Inc. 500 Company (Fastest Growing 500 Private Companies) – 10 Offices in the United States (U.S.); Based in Chicago – Oracle Advantage Partner in Tech & Applications • Former President Rolta TUSC & President Rolta EICT International • Author (3 Oracle Best Sellers – #1 Oracle Tuning Book for a Decade): – Oracle Performing Tips & Techniques (Covers Oracle7 & 8i) – Oracle9i Performance Tips & Techniques – Oracle Database 10g Performance Tips & Techniques • Former President of the International Oracle Users Group • Current President of the Midwest Oracle Users Group • Chicago Entrepreneur Hall of Fame - 1998 • E&Y Entrepreneur of the Year & National Hall of Fame - 2001 • IOUG Top Speaker in 1991, 1994, 1997, 2001, 2006, 2007 • MOUG Top Speaker Twelve Times • National Trio Achiever award - 2006 • Oracle Certified Master & Oracle Ace Director • Purdue Outstanding Electrical & Computer and Engineer - 2007