Ontology-Based Data Access Mapping Generation using Data, Schema, Query, and Mapping Knowledge
1 like459 views

The document discusses advancing access to linked data through ontology-based data access mapping generation, focusing on the limitations of current methods. It outlines a PhD research goal of improving access by discovering and utilizing existing knowledge to enhance mapping quality and reduce task complexity. Preliminary results suggest new tools and approaches for efficient mapping generation and evaluation, addressing both manual and semi-automatic methods.

































































Ontology-Based Data Access Mapping Generation using Data, Schema, Query, and Mapping Knowledge
- 1. Ontology-Based Data Access Mapping Generation via Data, Schema, Query, and Mapping Knowledge Pieter Heyvaert pheyvaer.heyvaert@ugent.be
- 2. Semantic Web technologies rely on Linked Data querying visualizations publishing
- 3. But not all data is accessible as Linked Data databases XML files JSON files
- 4. Solutions to provide access exist manual: completely done by the user semi-automatic: users provide feedback automatic: no user interaction required
- 5. But they have limitations limited to specific use cases limited support for complex use cases
- 6. PhD’s goal: improve access to Linked Data
- 7. Overview problem current solutions research questions hypotheses research methodology & approach preliminary results evaluation plan
- 8. Overview problem current solutions research questions hypotheses research methodology & approach preliminary results evaluation plan
- 9. How do we provide access? non-Linked Data Linked Data ?
- 10. How do we provide access? non-Linked Data Linked Data ? id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors
- 11. Apply mappings on non-Linked Data non-Linked Data Linked Data mapping mapping: rules to generate RDF terms and triples using data and ontologies
- 12. Apply mappings on non-Linked Data non-Linked Data Linked Datamapping id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors rule: create url from id rule: name is value for ex:fullname rule: if genre is ‘fiction’ class is ex:FictionAuthor else class is ex:NonFictionAuthor
- 13. Apply mappings on non-Linked Data non-Linked Data Linked Datamapping id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors ex:0 a ex:FictionAuthor . ex:0 ex:fullname ‘J.K. Rowling’ . ex:1 a ex:NonFictionAuthor . ex:1 ex:fullname ‘George Orwell’ .
- 14. Mappings need to be created from scratch (single-scenario use case) mapping A by reusing previous mappings (multi-scenario use case) mapping B mapping C mapping
- 15. (Semi-)automatic methods are preferred mapping manual (semi-)automatic
- 16. Still a number of challenges left dealing complex data (schemas) not all techniques work on single-scenario use cases
- 17. Dealing with complex data (schemas) e.g., when the class of an entity does not depend on the table, but on a value rule: if genre is ‘fiction’, class is ex:FictionAuthor else class is ex:NonFictionAuthor id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors
- 18. Not all techniques work on single-scenario use cases scenario A scenario Bmulti single because they rely on readily-available previous mappings mapping results in reuse ? scenario B? results in reuse
- 19. Overview problem current solutions research questions hypotheses research methodology & approach preliminary results evaluation plan
- 20. Current solutions What knowledge is used? How is this knowledge used? What knowledge is not used?
- 21. What do current solutions use? knowledge from the mapping process existing knowledge outside the mapping process
- 22. Knowledge from mapping process is used data data schema ontologies not all elements are required
- 23. Existing knowledge is used data data schemas mappings ontologies Linked Data not all elements are required
- 24. How is all this knowledge used? data schema + existing ontology data + existing mapping
- 25. Data schema + existing ontology data schema new ontology 1
- 26. Data schema + existing ontology data schema existing ontologynew ontology match 1 2 2
- 27. Data schema + existing ontology data schema existing ontologynew ontology match mapping 1 2 2 3
- 28. Data + existing mapping data classesproperties 1
- 29. Data + existing mapping data existing mapping classesproperties classespropertiesmodel 1 2 2 2
- 30. Data + existing mapping data existing mapping classes mapping properties classespropertiesmodel 1 2 2 2 3 3 3
- 31. These methods are not combined only a single method is used combining multiple methods has not been explored
- 32. What knowledge do current solutions not use? not all knowledge from previous mappings neglect query workload
- 33. Not all knowledge from previous mappings is used data transformations to lowercase substring conditions: if-else rules
- 34. Query workload is neglected queries to be executed on the non-existing Linked Dataset queries contains knowledge model used ontologies annotations
- 35. select * where { ?s a ex:FictionAuthor . ?s ex:fullname ?n . } id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors ontology to use: http://example.com model + annotations: ex:FictionAuthor ex:fullname How can we use queries?
- 36. Overview problem current solutions research questions hypotheses research methodology & approach preliminary results evaluation plan
- 37. Research questions discover existing knowledge use discovered knowledge
- 38. Question 1: how can we discover existing knowledge that is relevant? ?mappings ontologies (Linked) Data query workload data schema existing mapping
- 39. Question 2: how can we use the discovered knowledge to generate a new mapping? mapping mappings ontologies (Linked) Data query workload data data schema ontologies query workload data schema existing mapping process
- 40. Overview problem statement research questions hypotheses research methodology & approach preliminary results evaluation plan
- 41. Hypotheses improve quality decrease task complexity
- 42. Hypothesis 1: using existing knowledge improves the quality of a new single-scenario mapping. quality → fitness for use
- 43. Hypothesis 2: using existing knowledge decreases the task complexity of the mapping process. Lui and Li developed model to measure task complexity. 5 characteristics that influence the task’s performance
- 44. Task complexity has 5 characteristics input: e.g., data, ontologies, user feedback output: Linked Data, mapping process: steps, user actions duration: time to complete task presentation: user interface
- 45. Overview problem statement research questions hypotheses research methodology & approach preliminary results evaluation plan
- 46. Two aspects need to be tackled discover existing knowledge use knowledge both can be tackled separately
- 47. Discover existing knowledge infer knowledge from mapping process where possible find relevant other existing knowledge via similarity metrics
- 48. Infer knowledge from mapping process e.g., infer data schema from data e.g., infer ontology from queries
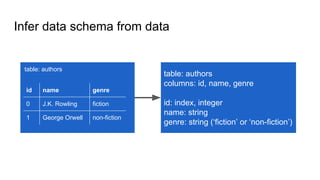
- 49. Infer data schema from data id name genre 0 J.K. Rowling fiction 1 George Orwell non-fiction table: authors table: authors columns: id, name, genre id: index, integer name: string genre: string (‘fiction’ or ‘non-fiction’)
- 50. Infer ontology from queries select * where { ?s a ex:FictionAuthor . ?s ex:fullname ?n . } http://example.com
- 51. Find relevant existing knowledge via similarity metrics mapping process mapping 1. determine similarity 2. consider in mapping process existing table: authors columns: id, name, genre id: index, integer, unique name: string genre: string (‘fiction’ or ‘non-fiction’) table: author columns: id, fullname, genres id: index, integer fullname: string genres: string
- 52. Similarity metrics on different/combination of elements metrics on data schema, ontologies, data, and query workload PhD: Which metrics do we use? How do we combine the different metrics?
- 53. Two aspects need to be tackled discover existing knowledge use knowledge
- 54. Use knowledge work with existing methods, e.g.: data schema + existing ontology data + existing mappings PhD: how do we include new knowledge? how do we combine these methods?
- 55. Overview problem statement research questions hypotheses research methodology & approach preliminary results evaluation plan
- 56. Preliminary Results RMLEditor RMLWorkbench mapping generation approaches hierarchical data analysis
- 57. RMLEditor eases the creation of mappings GUI so domain experts can create mappings users can view the data, mappings, and RDF triples usable by both non-SW and SW experts PhD: present mappings to get feedback during mapping process
- 58. RMLWorkbench eases generation and publication graphical user interface so domain experts can administer Linked Data generation publication workflow PhD: manage elements of the mapping generation process
- 59. Identified mapping generation approaches data-driven schema-driven model-driven result-driven PhD: provides insights on how users work this can be applied when developing an (semi-)automatic approach
- 60. Developed tool for data analysis on hierarchical data efficient discovery of unique identifiers in hierarchical data PhD: to infer knowledge within the mapping process
- 61. Overview problem current solutions research questions hypotheses research methodology & approach preliminary results evaluation plan
- 62. Evaluation Plan mapping quality task complexity
- 63. Evaluate mapping quality existing benchmark RODI great for tabular data no support for other formats, such as hierarchical data formats
- 64. Evaluate task complexity via 5 characteristics input: e.g., data, ontologies, user feedback output: Linked Data, mapping process: steps, user actions duration: time to complete task presentation: user interface
- 65. Limited in current evaluations to single aspect only duration only number of user actions only precision and recall
- 66. Roundup improve single-scenario mappings by discovering and using existing knowledge What similarity metrics we use for discovery? How do we use and combine the different methods and knowledge?