pandas.(to/from)_sql is simple but not fast
0 likes301 views

The document discusses the integration of SQL databases with pandas using the `read_sql` and `to_sql` functions, emphasizing the speed limitations of these methods. It highlights potential performance improvements through ODBC with turbodbc and Apache Arrow, which can significantly enhance data retrieval speeds. The author also proposes ideas for a better API that retains the simplicity of pandas while leveraging faster connection options.














![How does it work (read_sql)?
• pandas.read_sql [1] calls SQLDatabase.read_query [2]
• This then does
• Depending on whether a chunksize was given, this fetches all or
parts of the result
[1] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L509-L516
[2] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1243](https://image.slidesharecdn.com/2020-11-18fasterpd-readsqlpydataglobal-201114075832/85/pandas-to-from-_sql-is-simple-but-not-fast-15-320.jpg)

![How does it work (to_sql)?
• This is more tricky as we modify the database.
• to_sql [1] may need to create the target
• If not existing, it will call CREATE TABLE [2]
• Afterwards, we INSERT [3] into the (new) table
• The insertion step is where we convert from DataFrame back into
records [4]
[1] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1320
[2] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1383-L1393
[3] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1398
[4] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L734-L747](https://image.slidesharecdn.com/2020-11-18fasterpd-readsqlpydataglobal-201114075832/85/pandas-to-from-_sql-is-simple-but-not-fast-17-320.jpg)

















pandas.(to/from)_sql is simple but not fast
- 1. pd.{read/to}_sql is simple but not fast Uwe Korn – QuantCo – November 2020
- 2. About me • Engineering at QuantCo • Apache {Arrow, Parquet} PMC • Turbodbc Maintainer • Other OSS stuff @xhochy @xhochy mail@uwekorn.com https://uwekorn.com
- 3. Our setting • We like tabular data • Thus we use pandas • We want large amounts of this data in pandas • The traditional storage for it is SQL databases • How do we get from one to another?
- 4. SQL • Very very brief intro: • „domain-specific language for accessing data held in a relational database management system“ • The one language in data systems that precedes all the Python, R, Julia, … we use as our „main“ language, also much wider user base • SELECT * FROM table INSERT INTO table
- 5. • Two main arguments: • sql: SQL query to be executed or a table name. • con: SQLAlchemy connectable, str, or sqlite3 connection
- 6. • Two main arguments: • name: Name of SQL table. • con: SQLAlchemy connectable, str, or sqlite3 connection
- 7. • Let’s look at the other nice bits („additional arguments“) • if_exists: „What should we do when the target already exists?“ • fail • replace • append
- 8. • index: „What should we with this one magical column?“ (bool) • index_label • chunksize: „Write less data at once“ • dtype: „What should we with this one magical column?“ (bool) • method: „Supply some magic insertion hook“ (callable)
- 9. SQLAlchemy • SQLAlchemy is a Python SQL toolkit and Object Relational Mapper (ORM) • We only use the toolkit part for: • Metadata about schema and tables (incl. creation) • Engine for connecting to various databases using a uniform interface
- 10. Under the bonnet
- 15. How does it work (read_sql)? • pandas.read_sql [1] calls SQLDatabase.read_query [2] • This then does • Depending on whether a chunksize was given, this fetches all or parts of the result [1] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L509-L516 [2] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1243
- 16. How does it work (read_sql)? • Passes in the data into the from_records constructor • Optionally parses dates and sets an index
- 17. How does it work (to_sql)? • This is more tricky as we modify the database. • to_sql [1] may need to create the target • If not existing, it will call CREATE TABLE [2] • Afterwards, we INSERT [3] into the (new) table • The insertion step is where we convert from DataFrame back into records [4] [1] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1320 [2] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1383-L1393 [3] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L1398 [4] https://github.com/pandas-dev/pandas/blob/d9fff2792bf16178d4e450fe7384244e50635733/pandas/io/sql.py#L734-L747
- 18. Why is it slow? No benchmarks yet, theory first.
- 19. Why is it slow?
- 20. Thanks Slides will come after PyData Global Follow me on Twitter: @xhochy How to get fast?
- 21. ODBC • Open Database Connectivity (ODBC) is a standard API for accessing databases • Most databases provide an ODBC interface, some of them are efficient • Two popular Python libraries for that: • https://github.com/mkleehammer/pyodbc • https://github.com/blue-yonder/turbodbc
- 22. ODBC Turbodbc has support for Apache Arrow: https://arrow.apache.org/ blog/2017/06/16/turbodbc-arrow/
- 23. ODBC • With turbodbc + Arrow we get the following performance improvements: • 3-4x for MS SQL, see https://youtu.be/B-uj8EDcjLY?t=1208 • 3-4x speedup for Exasol, see https://youtu.be/B-uj8EDcjLY?t=1390
- 24. Snowflake • Turbodbc is a solution that retrofits performance • Snowflake drivers already come with built-in speed • Default response is JSON-based, BUT: • The database server can answer directly with Arrow • Client only needs the Arrow->pandas conversion (lightning fast⚡) • Up to 10x faster, see https://www.snowflake.com/blog/fetching- query-results-from-snowflake-just-got-a-lot-faster-with-apache- arrow/
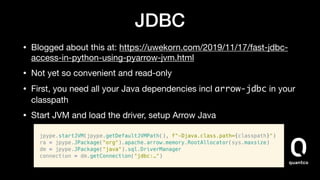
- 25. JDBC • Blogged about this at: https://uwekorn.com/2019/11/17/fast-jdbc- access-in-python-using-pyarrow-jvm.html • Not yet so convenient and read-only • First, you need all your Java dependencies incl arrow-jdbc in your classpath • Start JVM and load the driver, setup Arrow Java
- 26. JDBC • Then: • Fetch result using the Arrow Java JDBC adapter • Use pyarrow.jvm to get a Python reference to the JVM memory • Convert to pandas 136x speedup!
- 27. Postgres Not yet opensourced but this is how it works:
- 28. How do we get this into pandas.read_sql?
- 29. API troubles • pandas’ simple API: • turbodbc
- 30. API troubles • pandas’ simple API: • Snowflake
- 31. API troubles • pandas’ simple API: • pyarrow.jvm + JDBC
- 32. Building a better API • We want to use pandas’ simple API but with the nice performance benefits • One idea: Dispatching based on the connection class • User doesn’t need to learn a new API • Performance improvements come via optional packages
- 33. Building a better API Alternative idea:
- 34. Building a better API Discussion in https://github.com/pandas-dev/pandas/issues/36893
- 35. Thanks Follow me on Twitter: @xhochy