












![New matrix math instruction set architecture
14
ACC[0]
VSR[0]
…
VSR[3]
ACC[1]
VSR[4]
…
VSR[7]
ACC[2]
VSR[8]
…
VSR[11]
ACC[3]
VSR[12]
…
VSR[15]
ACC[4]
VSR[16]
…
VSR[19]
ACC[5]
VSR[20]
…
VSR[23]
ACC[6]
VSR[24]
…
VSR[27]
ACC[7]
VSR[28]
…
VSR[31]
• Accumulators (ACC) are 4 × 4 arrays of 32-bit elements
(see below for 64-bit extension)
𝐴 =
𝑎00 𝑎01
𝑎10 𝑎11
𝑎02 𝑎03
𝑎12 𝑎13
𝑎20 𝑎21
𝑎30 𝑎31
𝑎22 𝑎23
𝑎32 𝑎33
• Vector-scalar registers (VSR) are 128-bit wide and can hold
• 4 single-precision (32-bit) floating-point values
• 8 half-precision (16-bit) floating-point values
• 16 signed/unsigned (8-bit) integer values
• …
• Instructions take 1 accumulator (input/output) and 2
vector-scalar registers (input)
𝐨𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧 𝐴, 𝑋, 𝑌](https://image.slidesharecdn.com/power10innovations-210713234045/85/POWER10-innovations-for-HPC-14-320.jpg)

![Outer-product (xv<type>ger<rank-𝑘>) instructions
• Integer data: 𝐴 ← 𝑋𝑌𝑇 +𝐴
• For 16-bit data, 𝑋 and 𝑌 are 4 × 2 arrays of elements
• For 8-bit data, 𝑋 and 𝑌 are 4 × 4 arrays of elements
• For 4-bit data, 𝑋 and 𝑌 are 4 × 8 arrays of elements
• Floating-point data: 𝐴 ← − 𝑋𝑌𝑇 [±𝐴]
• For 32-bit data, 𝑋 and 𝑌 are 4-element vectors
• For 16-bit data, 𝑋 and 𝑌 are 4 × 2 arrays of elements
• For 32-bit data, 𝑋 is a 4-element vector and 𝑌 is a 2-element vector
17
Instruction 𝑨 𝑿 𝒀𝑻 # of madds/instruction
xvf32ger 4 × 4 (fp32) 4 × 1 (fp32) 1 × 4 (fp32) 16
xv[b]f16ger2 4 × 4 (fp32) 4 × 2 (fp16) 2 × 4 (fp16) 32
xvi16ger[s]2 4 × 4 (int32) 4 × 2 (int16) 2 × 4 (int16) 32
xvi8ger[s]4 4 × 4 (int32) 4 × 4 (int8) 4 × 4 (uint8) 64
xvi4ger8 4 × 4 (int32) 4 × 8 (int4) 8 × 4 (int4) 128
xvf64ger 4 × 2 (fp64) 4 × 1 (fp64) 1 × 2 (fp64) 8](https://image.slidesharecdn.com/power10innovations-210713234045/85/POWER10-innovations-for-HPC-17-320.jpg)
![Current compiler support through built-ins
Instruction Built-in
__builtin_mma_assemble_acc(&𝑨, 𝒙, 𝒚, 𝒛, 𝒕)
__builtin_mma_disassemble_acc(&𝒙, &𝑨)
xxsetaccz __builtin_mma_xxsetaccz(&𝑨)
xvi16ger2[s][pp] __builtin_mma_xvi16ger2[s][pp](&𝑨, 𝒙, 𝒚)
xvi8ger4[s][pp] __builtin_mma_xvi8ger4[s][pp](&𝑨, 𝒙, 𝒚)
xvi4ger8[pp] __builtin_mma_xvi4ger8[pp](&𝑨, 𝒙, 𝒚)
xvbf16ger2[pp,np,pn,nn] __builtin_mma_xvbf16ger2[pp,np,pn,nn](&𝑨, 𝒙, 𝒚)
xvf16ger2[pp,np,pn,nn] __builtin_mma_xvf16ger2[pp,np,pn,nn](&𝑨, 𝒙, 𝒚)
xvf32ger[pp,np,pn,nn] __builtin_mma_xvf32ger[pp,np,pn,nn](&𝑨, 𝒙, 𝒚)
xvf64ger[pp,np,pn,nn] __builtin_mma_xvf64ger[pp,np,pn,nn](&𝑨, 𝒒, 𝒚)
18](https://image.slidesharecdn.com/power10innovations-210713234045/85/POWER10-innovations-for-HPC-18-320.jpg)
![Sample DGEMM micro-kernel
fp64_4x2 acc[8];
fp64_4 x0, x1;
fp64_2 y0, y1, y2, y3;
for (i=0; i<n; i++, X+=8, Y+=8)
{
x0 = *((fp64_4*)X+0); x1 = *((fp64_4*)X+1);
y0 = *((fp64_2*)Y+0); y1 = *((fp64_2*)Y+1);
y2 = *((fp64_2*)Y+2); y3 = *((fp64_2*)Y+3);
__builtin_mma_xvf64gerpp(&(acc[0]), x0, y0);
__builtin_mma_xvf64gerpp(&(acc[1]), x1, y0);
__builtin_mma_xvf64gerpp(&(acc[4]), x0, y1);
__builtin_mma_xvf64gerpp(&(acc[5]), x1, y1);
__builtin_mma_xvf64gerpp(&(acc[2]), x0, y2);
__builtin_mma_xvf64gerpp(&(acc[3]), x1, y2);
__builtin_mma_xvf64gerpp(&(acc[6]), x0, y3);
__builtin_mma_xvf64gerpp(&(acc[7]), x1, y3);
}
19
X Y
y0 y1 y2 y3
x0
x1](https://image.slidesharecdn.com/power10innovations-210713234045/85/POWER10-innovations-for-HPC-19-320.jpg)






POWER10 innovations for HPC
- 1. POWER10 Innovations for HPC Presented at the OpenPOWER Workshop at CINECA Wednesday 06/30/2021 José Moreira IBM Research 1
- 2. My most direct collaborators, who made POWER10 a reality … • Bill Starke (chip architect) • Brian Thompto (core architect) • Dung Q. Nguyen • Ramon Bertran • Hans Jacobson • Richard J. Eickemeyer • Rahul M.Rao • Michael Goulet • Marcy Byers • Christopher J. Gonzalez • Karthik Swaminathan • Nagu R. Dhanwada • Silvia M. Müller • Andreas Wagner • Satish Kumar Sadasivam • Robert K. Montoye • Christian G. Zoellin • Michael S. Floyd • Jeffrey Stuecheli • Nandhini Chandramoorthy • John-David Wellman • Alper Buyuktosunoglu • Matthias Pflanz • Balaram Sinharoy • Pradip Bose 2 • Kit Barton • Steven Battle • Peter Bergner • Puneeth Bhat • Pedro Caldeira • David Edelsohn • Gordon Fossum • Brad Frey • Nemanja Ivanovic • Chip Kerchner • Vincent Lim • Shakti Kapoor • Tulio Machado Filho • Brett Olsson • Baptiste Saleil • Bill Schmidt • Rajalakshmi Srinivasaraghavan • Andreas Wagner • Nelson Wu • Serif Yesil ... Most of what I will talk today is not really my work – I will cover what I specifically worked on towards the end of the talk
- 3. POWER10 chip: key features ▪ Enterprise focused design: ▪ 602 mm2 7nm 18 layer metal stack ▪ SCM: 15 SMT-8 cores / 30 SMT-4 cores → 120 HW threads ▪ DCM: 30 SMT-8 cores / 60 SMT-4 cores → 240 HW Threads ▪ Robust data plane: Bandwidth, Scale, Composability ▪ Open Memory Interface up to 1 TB/s ▪ PowerAXON Interface up to 1 TB/s ▪ Up to 16 SCM sockets ”glueless” SMP ▪ Integrated AI acceleration ▪ Security co-optimized across the stack ▪ Re-architected for efficiency: up to 3x relative to POWER9 (DCM) 3 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 SMT8 Core 2MB L2 Local 8MB L3 region 64 MB L3 Hemisphere 64 MB L3 Hemisphere SMP, Memory, Accel, Cluster, PCI Interconnect SMP, Memory, Accel, Cluster, PCI Interconnect PCIe Gen 5 Signaling (x16) PowerAXON x 3 2 + 4 Memory Signaling (8x8 OMI) Memory Signaling (8x8 OMI) PCIe Gen 5 Signaling (x16) x 3 2 + 4 PowerAXON PowerAXON x 3 2 + 4 x 3 2 + 4 PowerAXON Die Photo courtesy of Samsung Foundry 3
- 4. SCM OpenCAPI Attach SCM Main tier DRAM OMI Memory PowerAXON 1 Terabyte / sec 1 Terabyte / sec POWER10 chip PCIe G5 ASIC or FPGA Accelerated App (PowerAXON and OMI Memory configurations show processor capability only, and do not imply system product offerings) 4 POWER10 interconnect architecture
- 5. OMI Memory PowerAXON Built on best-of-breed low Power, low Latency, high bandwidth signaling technology Multi-protocol “Swiss-army-knife” flexible / modular interfaces POWER10 chip 1 Terabyte / sec 1 Terabyte / sec PowerAXON corner 4x8 @ 32 GT/s OMI edge 8x8 @ 32 GT/s 6x bandwidth / mm2 compared to DDR4 signaling 5 System Composability: PowerAXON & Open Memory Interfaces
- 6. Main tier DRAM OMI Memory PowerAXON Built on best-of-breed low power, low latency, high bandwidth signaling technology 1 Terabyte / sec 1 Terabyte / sec Build up to 16 SCM socket Robustly Scalable High Bisection Bandwidth “Glueless” SMP Initial Offering: Up to 4 TB / socket OMI DRAM memory 410 GB/s peak bandwidth (MicroChip DDR4 buffer) < 10ns latency adder Multi-protocol “Swiss-army-knife” flexible / modular interfaces POWER10 chip DIMM swap upgradeable: DDR5 OMI DRAM memory with higher bandwidth and higher capacity (PowerAXON and OMI Memory configurations show processor capability only, and do not imply system product offerings) 6 System Enterprise Scale and Bandwidth: SMP & Main Memory
- 7. DRAM DIMM comparison • Technology agnostic • Low cost • Ultra-scale system density • Enterprise reliability • Low-latency • High bandwidth Approximate Scale JEDEC DDR DIMM IBM Centaur DIMM OMI DDIMM 7
- 8. Single-chip module focus: - 602mm2 7nm (18B devices) - Core/thread strength - Up to 15 SMT8 Cores (4+ GHz) - Capacity & bandwidth / compute - Memory: x128 @ 32 GT/s - SMP/Cluster/Accel: x128 @ 32 GT/s - I/O: x32 PCIe G5 - System scale (broad range) - 1 to 16 sockets Dual-chip module focus: - 1204mm2 7nm (36B devices) - Throughput / socket - Up to 30 SMT8 Cores (3.5+ GHz) - Compute & I/O density - Memory: x128 @ 32 GT/s - SMP/Cluster/Accel: x192 @ 32 GT/s - I/O: x64 PCIe G5 - 1 to 4 sockets Horizontal Full Connect Vertical Full Connect Up to 16 SCM Sockets Up to 4 DCM Sockets (Multi-socket configurations show processor capability only, and do not imply system product offerings) 8 Socket composability: SCM & DCM
- 9. Workload A Workload B Workload C A B C A A A C C C C C C C C C C C C C C C C C C C C C C C B B B B B B B B B B B B B B B B B B B B B B B Use case: Share load/store memory amongst directly connected neighbors within Pod Unlike other schemes, memory can be used: - As low latency local memory - As NUMA latency remote memory Example: Pod = 8 systems each with 8TB Workload A Rqmt: 4 TB low latency Workload B Rqmt: 24 TB relaxed latency Workload C Rqmt: 8 TB low latency plus 16TB relaxed latency All Rqmts met by configuration shown POWER10 2 Petabyte memory size enables much larger configurations (Memory cluster configurations show processor capability only, and do not imply system product offerings) 9 Memory Inception: Distributed memory disaggregation and sharing
- 10. POWER10 socket performance gains ▪ General workload speedup up to 3x ▪ SIMD/AI accelerated speedup up to 10x+ 10 (Performance assessments based upon pre-silicon engineering analysis of POWER10 dual-socket server offering vs POWER9 dual-socket server offering) POWER9 Baseline POWER10 Integer POWER10 Enterprise POWER10 Floating Point POWER10 Memory Streaming DDR4 OMI Memory DDR5 OMI Memory 2 1 3 4 POWER9 Baseline POWER10 Linpack POWER10 Inference Resnet-50 FP32 POWER10 Inference Resnet-50 BFloat16 POWER10 Inference Resnet-50 INT8 5 10 15 20 10
- 11. POWER10 core: key enhancements over POWER9 ▪ Efficiency: 2.6x performance/watt ▪ 30% avg core perf improvement ▪ 50% avg core power reduction ▪ AI infusion with in-core capability ▪ Matrix accelerator (MMA) ▪ 2x general SIMD ▪ 2x Load/Store bandwidth ▪ 4x L2 Cache 11 4x L2 Cache MMA 2x General SIMD 2x Load, 2x Store 4x MMU New ISA Prefix Fusion Enhanced Control & Branch SMT8 Core 11
- 12. 12 32B LD 32B LD 32B ST (+gathered) 64B dedicated 32B 8 instr Decode/Fuse 8 iop TLB miss miss I miss L3 prefetch I-EA Instruction Buffer 128 entries 2 Load EA MMA Accelerator 2x512b L2 Cache 1 MB (hashed index) L1 Instr. Cache 48k 6-way <EA Tagged> L1 Data Cache 32k 8-way <EA Tagged> Store Queue 80 entries (SMT) 40 entries (ST) Load Queue 128 entries (SMT) 64 entries (ST) Load Miss Queue 12 entries Predecode +Fusion/Prefix Instruction Table 512 entries Execution Slice 128b Execution Slice 128b Execution Slice 128b Execution Slice 128b 2 Store EA Fetch / +Branch Predictors Prefetch 16 streams ERAT 64 entry TLB 4k entry L3 Prefetch 48 entries D miss ▪ SMT8 and SMT4 (shown) cores ▪ 8-way superscalar ▪ SMT8-core has 2x resources of SMT4-core ▪ Double SIMD + AI/ML acceleration ▪ 2x SIMD, 4x MMA, 4x AES/SHA ▪ Larger working-sets ▪ 1.5x L1 I-cache, 4x L2, 4x TLB ▪ Deeper instruction windows/queues ▪ 512 instructions in flight ▪ Data bandwidth & latency (cycles) ▪ L2 13.5 (minus 2), L3 27.5 (minus 8) ▪ L1-D cache 4 +0 for Store forward (minus 2) ▪ 2x bandwidth ▪ Improved branch prediction ▪ Target registers with GPR in main regfile ▪ New predictors: target and direction, 2x BHT ▪ Instruction fusion ▪ Fixed, SIMD, other: merge and back-to-back ▪ Load, store: consecutive storage >= 2x Improved = 4x Capacity vs. POWER9: POWER10 core microarchitecture 12
- 13. • BLAS-2 rank-1 update (GER): 𝑨 ← 𝒙𝒚𝐓 + 𝑨 • One-dimensional input vectors from main register file • Two-dimensional accumulator resides local to unit • Reduced-precision data types, perform multiple updates: 𝑨 ← σ 𝒙𝒊𝒚𝒊 𝐓 + 𝑨 Energy efficient computing in the MMA MMA rank-k update can be exploited by a variety of computation kernels • BLAS-3 and BLAS-2 • Sparse matrix-operations (SpMM, Cholesky factorization) • Direct convolution • Discrete-Fourier Transform • Stencil computation ISCA 2021, Industry Track 13 13 × + 𝑎00 × + 𝑎01 × + 𝑎02 × + 𝑎03 × + 𝑎10 × + 𝑎11 × + 𝑎12 × + 𝑎13 × + 𝑎20 × + 𝑎21 × + 𝑎22 × + 𝑎23 × + 𝑎30 × + 𝑎31 × + 𝑎32 × + 𝑎33 𝑦0 𝑦1 𝑦2 𝑦3 𝑥0 𝑥1 𝑥2 𝑥3 Vector-Scalar Register File FETCH FETCH
- 14. New matrix math instruction set architecture 14 ACC[0] VSR[0] … VSR[3] ACC[1] VSR[4] … VSR[7] ACC[2] VSR[8] … VSR[11] ACC[3] VSR[12] … VSR[15] ACC[4] VSR[16] … VSR[19] ACC[5] VSR[20] … VSR[23] ACC[6] VSR[24] … VSR[27] ACC[7] VSR[28] … VSR[31] • Accumulators (ACC) are 4 × 4 arrays of 32-bit elements (see below for 64-bit extension) 𝐴 = 𝑎00 𝑎01 𝑎10 𝑎11 𝑎02 𝑎03 𝑎12 𝑎13 𝑎20 𝑎21 𝑎30 𝑎31 𝑎22 𝑎23 𝑎32 𝑎33 • Vector-scalar registers (VSR) are 128-bit wide and can hold • 4 single-precision (32-bit) floating-point values • 8 half-precision (16-bit) floating-point values • 16 signed/unsigned (8-bit) integer values • … • Instructions take 1 accumulator (input/output) and 2 vector-scalar registers (input) 𝐨𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧 𝐴, 𝑋, 𝑌
- 15. Rank-𝑘 update with 32-bit and 16-bit elements • 32-bit: Each VSR holds 1 column (row) of 4×32-bit elements • 16-bit: Each VSR holds 2 columns (rows) of 4×16-bit elements 15 4 4 4 += 4 × 4 × 4 × + + … + 4 4 2 2 2 2 2 2 rank-2 update rank-2 update rank-2 update 4 4 4 += 4 × 4 × 4 × + + … + 4 4 1 1 1 1 1 1 rank-1 update rank-1 update rank-1 update
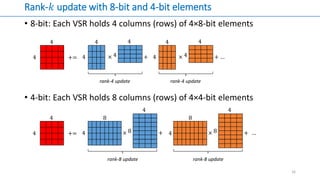
- 16. Rank-𝑘 update with 8-bit and 4-bit elements • 8-bit: Each VSR holds 4 columns (rows) of 4×8-bit elements • 4-bit: Each VSR holds 8 columns (rows) of 4×4-bit elements 16 4 4 += … 4 4 × + 8 8 rank-8 update 4 4 += … 4 4 × + 4 4 rank-4 update 4 4 × + 4 4 rank-4 update 4 × + 8 8 rank-8 update 4
- 17. Outer-product (xv<type>ger<rank-𝑘>) instructions • Integer data: 𝐴 ← 𝑋𝑌𝑇 +𝐴 • For 16-bit data, 𝑋 and 𝑌 are 4 × 2 arrays of elements • For 8-bit data, 𝑋 and 𝑌 are 4 × 4 arrays of elements • For 4-bit data, 𝑋 and 𝑌 are 4 × 8 arrays of elements • Floating-point data: 𝐴 ← − 𝑋𝑌𝑇 [±𝐴] • For 32-bit data, 𝑋 and 𝑌 are 4-element vectors • For 16-bit data, 𝑋 and 𝑌 are 4 × 2 arrays of elements • For 32-bit data, 𝑋 is a 4-element vector and 𝑌 is a 2-element vector 17 Instruction 𝑨 𝑿 𝒀𝑻 # of madds/instruction xvf32ger 4 × 4 (fp32) 4 × 1 (fp32) 1 × 4 (fp32) 16 xv[b]f16ger2 4 × 4 (fp32) 4 × 2 (fp16) 2 × 4 (fp16) 32 xvi16ger[s]2 4 × 4 (int32) 4 × 2 (int16) 2 × 4 (int16) 32 xvi8ger[s]4 4 × 4 (int32) 4 × 4 (int8) 4 × 4 (uint8) 64 xvi4ger8 4 × 4 (int32) 4 × 8 (int4) 8 × 4 (int4) 128 xvf64ger 4 × 2 (fp64) 4 × 1 (fp64) 1 × 2 (fp64) 8
- 18. Current compiler support through built-ins Instruction Built-in __builtin_mma_assemble_acc(&𝑨, 𝒙, 𝒚, 𝒛, 𝒕) __builtin_mma_disassemble_acc(&𝒙, &𝑨) xxsetaccz __builtin_mma_xxsetaccz(&𝑨) xvi16ger2[s][pp] __builtin_mma_xvi16ger2[s][pp](&𝑨, 𝒙, 𝒚) xvi8ger4[s][pp] __builtin_mma_xvi8ger4[s][pp](&𝑨, 𝒙, 𝒚) xvi4ger8[pp] __builtin_mma_xvi4ger8[pp](&𝑨, 𝒙, 𝒚) xvbf16ger2[pp,np,pn,nn] __builtin_mma_xvbf16ger2[pp,np,pn,nn](&𝑨, 𝒙, 𝒚) xvf16ger2[pp,np,pn,nn] __builtin_mma_xvf16ger2[pp,np,pn,nn](&𝑨, 𝒙, 𝒚) xvf32ger[pp,np,pn,nn] __builtin_mma_xvf32ger[pp,np,pn,nn](&𝑨, 𝒙, 𝒚) xvf64ger[pp,np,pn,nn] __builtin_mma_xvf64ger[pp,np,pn,nn](&𝑨, 𝒒, 𝒚) 18
- 19. Sample DGEMM micro-kernel fp64_4x2 acc[8]; fp64_4 x0, x1; fp64_2 y0, y1, y2, y3; for (i=0; i<n; i++, X+=8, Y+=8) { x0 = *((fp64_4*)X+0); x1 = *((fp64_4*)X+1); y0 = *((fp64_2*)Y+0); y1 = *((fp64_2*)Y+1); y2 = *((fp64_2*)Y+2); y3 = *((fp64_2*)Y+3); __builtin_mma_xvf64gerpp(&(acc[0]), x0, y0); __builtin_mma_xvf64gerpp(&(acc[1]), x1, y0); __builtin_mma_xvf64gerpp(&(acc[4]), x0, y1); __builtin_mma_xvf64gerpp(&(acc[5]), x1, y1); __builtin_mma_xvf64gerpp(&(acc[2]), x0, y2); __builtin_mma_xvf64gerpp(&(acc[3]), x1, y2); __builtin_mma_xvf64gerpp(&(acc[6]), x0, y3); __builtin_mma_xvf64gerpp(&(acc[7]), x1, y3); } 19 X Y y0 y1 y2 y3 x0 x1
- 21. DGEMM and LINPACK performance in POWER10 21 𝑁 × 128 × (128 × 𝑁) (𝑁 × 𝑁)
- 22. POWER10 DGEMM flops/cycle and core power ▪ POWER10 VSU vs POWER9 VSU ▪ 1.95x flops/cycle ▪ 0.67x core power consumption ▪ 2.88x efficiency (perf/watt) ▪ POWER10 MMA vs POWER9 VSU ▪ 5.47x flops/cycle ▪ 0.76x core power consumption ▪ 7.21x efficiency (perf/watt) 22 Normalized to POWER9 VSU 0 1 2 3 4 5 6 Flops/cycle Core Power Relative Value POWER9 (baseline) POWER10 (w/o MMA) POWER10 (w/ MMA) 22
- 23. Sparse-matrix computations with the MMA Work by Serif Yesil (UIUC), in collaboration with Jose Moreira (IBM) and Prof. Josep Torrellas (UIUC) 23
- 24. Sparse-matrix computations with the MMA Work by Serif Yesil (UIUC), in collaboration with Jose Moreira (IBM) and Prof. Josep Torrellas (UIUC) 24 SpMM (𝑁 = 16) Processor 𝑵 = 𝟏𝟔 𝑵 = 𝟑𝟐 𝑵 = 𝟔𝟒 POWER9+VSU (24 cores @ 3.6 GHz) 220 Gflops 250 Gflops 250 Gflops POWER10+VSU (30 cores @ 3.6 GHz) 440 Gflops 490 Gflops 480 Gflops POWER10+MMA (30 cores @ 3.6 GHz) 950 Gflops 960 Gflops 830 Gflops Compute 𝑪 = 𝑨 × 𝑩 in double-precision arithmetic 𝑪: 𝑴 × 𝑵 dense matrix, 𝑨: 𝑴 × 𝑲 sparse matrix, 𝑩: 𝑲 × 𝑵 dense matrix 𝑨: 𝟑𝟔𝟒𝟏𝟕 × 𝟑𝟔𝟒𝟏𝟕, 𝟒𝟑𝟒𝟒𝟕𝟔𝟓 nonzeros (99.7% sparse) - pdb1HYS
- 25. Conclusions • POWER10 is the latest generation of Power Systems processors for enterprise computing • Big improvements in compute, memory and interconnect deliver 3-times more socket performance at 2.6-times the power efficiency • More memory bandwidth and more vector processing are key for high-performance computing • The MMA facility defines a new set of matrix math instructions, directly implementing rank-𝑘 updates • With the MMA, POWER10 has ben able to achieve new levels of performance in a broadening space of applications – starting with dense linear algebra, moving to sparse, others on the horizon • IBM Advance Toolchain (native and cross compiler): git clone https://github.com/advancetoolchain/advance-toolchain.git cd advance-toolchain make AT_CONFIGSET=next BUILD_ARCH=ppc64le • IBM POWER10 Functional Simulator (ISA-level simulation) https://www14.software.ibm.com/webapp/set2/sas/f/pwrfs/pwr10/home.html 25