











![Compiler directives – The Multi Core
Magic Spells !
• Types of workshare directives
for Countable iteration[static]
sections One or more sequential
sections of code, executed
by a single thread
single Serializes a section of code](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-14-320.jpg)



![Matrix Multiplication using loop
directive
#pragma omp parallel private(i,j,k)
{
#pragma omp for
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-18-320.jpg)




![Matrix Multiplication using loop
directive – with a schedule
#pragma omp parallel private(i,j,k)
{
#pragma omp for schedule(static)
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-23-320.jpg)

![Parallelizing when the no.of Iterations
is unknown[dynamic] !
• openMP has a directive called task](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-25-320.jpg)




![Without using reduction
#pragma omp parallel shared(array,sum)
firstprivate(local_sum)
{
#pragma omp for private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
local_sum+=array[i][j];
}
}
#pragma omp critical
sum+=local_sum;
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-30-320.jpg)
![Using Reductions in openMP
sum=0;
#pragma omp parallel shared(array)
{
#pragma omp for reduction(+:sum) private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
sum+=array[i][j];
}
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-31-320.jpg)



Presentation on Shared Memory Parallel Programming
- 1. Introduction to OpenMP Presenter: Vengada Karthik Rangaraju Fall 2012 Term September 13th, 2012
- 2. What is openMP? • Open Standard for Shared Memory Multiprocessing • Goal: Exploit multicore hardware with shared memory • Programmer’s view: The openMP API • Structure: Three primary API components: – Compiler directives, – Runtime Library routines and – Environment Variables
- 3. Shared Memory Architecture in a Multi-Core Environment
- 4. The key components of the API and its functions • Compiler Directives - Spawning parallel regions (threads) - Synchronizing - Dividing blocks of code among threads - Distributing loop iterations
- 5. The key components of the API and its functions • Runtime Library Routines - Setting & querying no. of threads - Nested parallelism - Control over locks - Thread information
- 6. The key components of the API and its functions • Environment Variables - Setting no. of threads - Specifying how loop iterations are divided - Thread processor binding - Enabling/Disabling dynamic threads - Nested parallelism
- 7. Goals • Standardization • Ease of Use • Portability
- 8. Paradigm for using openMP Write sequential program Find parallelizable portions of program Insert calls to Insert runtime library directives/pragmas + routines and modify into existing code environment variables, if desired Use openMP’s extended Compiler What happens here? Compile and run !
- 9. Compiler translation #pragma omp <directive-type> <directive-clauses></n> { …… …..// Block of code executed as per instruction ! }
- 10. Basic Example in C { … //Sequential } #pragma omp parallel //fork { printf(“Hello from thread %d.n”,omp_get_thread_num()); } //join { … //Sequential }
- 11. What exactly happens when lines of code are executed in parallel? • A team of threads are created • Each thread can have its own set of private variables • All threads can have shared variables • Original thread : Master Thread • Fork-Join Model • Nested Parallelism
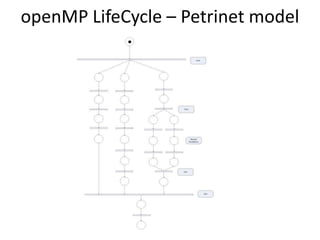
- 12. openMP LifeCycle – Petrinet model
- 13. Compiler directives – The Multi Core Magic Spells ! <directive type> Description parallel Each thread will perform same computation as others(replicated computations) for / sections These are called workshare directives. Portions of overall work divided among threads(different computations). They don’t create threads. It has to be enclosed inside a parallel directive for threads to takeover the divided work.
- 14. Compiler directives – The Multi Core Magic Spells ! • Types of workshare directives for Countable iteration[static] sections One or more sequential sections of code, executed by a single thread single Serializes a section of code
- 15. Compiler directives – The Multi Core Magic Spells ! • Clauses associated with each directive <directive type> <directive clause> parallel If(expression) private(var1,var2,…) firstprivate(var1,var2,..) lastprivate(var1,var2,..) shared(var1,var2,..) NUM_THREADS(integer value)
- 16. Compiler directives – The Multi Core Magic Spells ! • Clauses associated with each directive <directive type> <directive clause> for schedule(type, chunk) private(var1,var2,…) firstprivate(var1,var2,..) lastprivate(var1,var2,..) shared(var1,var2,..) collapse(n) nowait Reduction(operator:list)
- 17. Compiler directives – The Multi Core Magic Spells ! • Clauses associated with each directive <directive type> <directive clause> sections private(var1,var2,…) firstprivate(var1,var2,..) lastprivate(var1,var2,..) reduction(operator:list) nowait
- 18. Matrix Multiplication using loop directive #pragma omp parallel private(i,j,k) { #pragma omp for for(i=0;i<N;i++) for(k=0;k<K;k++) for(j=0;j<M;j++) C[i][j]=C[i][j]+A[i][k]*B[k][j]; }
- 19. Scheduling Parallel Loops • Static • Dynamic • Guided • Automatic • Runtime
- 20. Scheduling Parallel Loops • Static - Amount of work/iteration - same - Set of contiguous chunks in RR fashion - 1 Chunk = x iterations
- 21. Scheduling Parallel Loops • Dynamic - Amount of work/iteration - Varies - Each thread will grab chunk of iterations and return to grab another chunk when it has executed them. • Guided - Same as dynamic, only difference, - a good proportion of iterations remaining are shared among each thread.
- 22. Scheduling Parallel Loops • Runtime - Schedule determined using an environment variable. Library routine provided ! • Automatic - Implementation chooses any schedule
- 23. Matrix Multiplication using loop directive – with a schedule #pragma omp parallel private(i,j,k) { #pragma omp for schedule(static) for(i=0;i<N;i++) for(k=0;k<K;k++) for(j=0;j<M;j++) C[i][j]=C[i][j]+A[i][k]*B[k][j]; }
- 24. openMP worshare directive – sections int g; void foo(int m, int n) { int p,i; #pragma omp sections firstprivate(g) nowait { #pragma omp section { p=f1(g); for(i=0;i<m;i++) do_stuff; } #pragma omp section { p=f2(g); for(i=0;i<n;i++) do_other_stuff; } } return; }
- 25. Parallelizing when the no.of Iterations is unknown[dynamic] ! • openMP has a directive called task
- 26. Explicit Tasks void processList(Node* list) { #pragma omp parallel pragma omp single { Node *currentNode = list; while(currentNode) { #pragma omp task firstprivate(currentNode) doWork(currentNode); currentNode=currentNode->next; } } }
- 27. Explicit Tasks – Petrinet Model
- 28. Synchronization • Barrier • Critical • Atomic • Flush
- 29. Performing Reductions • A loop containing reduction will always be sequential, since each iteration would form a result depending on previous iteration. • openMP allows these loops to be parallelized as long as the developer says, loop contains reduction and indicates the variable and kind of reduction via “Clauses”
- 30. Without using reduction #pragma omp parallel shared(array,sum) firstprivate(local_sum) { #pragma omp for private(i,j) for(i=0;i<max_i;i++) { for(j=0;j<max_j;++j) local_sum+=array[i][j]; } } #pragma omp critical sum+=local_sum; }
- 31. Using Reductions in openMP sum=0; #pragma omp parallel shared(array) { #pragma omp for reduction(+:sum) private(i,j) for(i=0;i<max_i;i++) { for(j=0;j<max_j;++j) sum+=array[i][j]; } }
- 32. Programming for performance • Use of IF clause before creating parallel regions • Understanding Cache Coherence • Judicious use of parallel and flush • Critical and atomic - know the difference ! • Avoid unnecessary computations in critical region • Use of barrier - a starvation alert !
- 33. References • NUMA UMA http://vvirtual.wordpress.com/2011/06/13/what-is-numa/ http://www.e-zest.net/blog/non-uniform-memory-architecture-numa/ • openMP basics https://computing.llnl.gov/tutorials/openMP/ • Workshop on openMP SMP, by Tim Mattson from Intel (video) http://www.youtube.com/watch?v=TzERa9GA6vY
- 34. Interesting links • openMP official page http://openmp.org/wp/ • 32 openMP Traps for C++ Developers http://www.viva64.com/en/a/0054/#ID0EMULM