Python Streaming Pipelines with Beam on Flink
Download as PPTX, PDF0 likes1,620 views

The document discusses the use of Apache Beam for implementing Python streaming pipelines on Apache Flink, highlighting that Apache Beam offers a unified programming model and multi-language support for data processing. It addresses challenges related to language barriers in big data ecosystems, particularly for teams that may lack Java experience, and emphasizes the portability framework that facilitates executing Python jobs across various runners. Future work includes enhancing user state and timers support, as well as enabling integration of connectors across different programming languages.











































Python Streaming Pipelines with Beam on Flink
- 1. Python Streaming Pipelines with Beam on Flink Flink Forward Berlin, 2018 Apache Beam Aljoscha Krettek, Thomas Weise Apache Flink https://s.apache.org/streaming-python-beam-flink
- 2. 2 Agenda 1. What is Beam? 2. The Beam Portability APIs 3. Executing Pythonic Beam Jobs on Flink 4. The Future
- 3. 3 Problem ● Many of the big data ecosystem projects are Java / JVM based ● Use cases with different language environments ○ Python is the primary option for Machine Learning ● Barrier to entry for teams that want to adopt streaming but have no Java experience ● Cost of too many API styles and runtime environments ● (Currently no good option for native Python + Streaming)
- 4. 4 Multi-Language Support in Beam ● Effort to support multiple languages in Beam started late 2016 ● Python SDK on Dataflow available for ~ 1 year ● Go SDK added recently ● At Flink Forward 2017… 2018: Portable Flink Runner MVP near completion (~ Beam release 2.8.0)
- 6. What is Apache Beam? 1. Unified model (Batch + strEAM) What / Where / When / How 2. SDKs (Java, Python, Go, ...) & DSLs (Scala, …) 3. Runners for Existing Distributed Processing Backends (Google Dataflow, Spark, Flink, …) 4. IOs: Data store Sources / Sinks Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines
- 7. 7 The Apache Beam Vision 1. End users: who want to write pipelines in a language that’s familiar. 2. SDK writers: who want to make Beam concepts available in new languages. 3. Runner writers: who have a distributed processing environment and want to support Beam pipelines Beam Model: Fn Runners Apache Flink Apache Spark Beam Model: Pipeline Construction Other LanguagesBeam Java Beam Python Execution Execution Cloud Dataflow Execution https://s.apache.org/apache-beam-project-overview
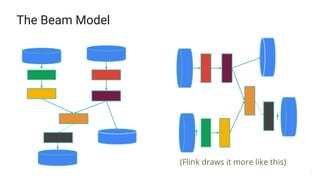
- 8. 8 The Beam Model (Flink draws it more like this)
- 9. 9 The Beam Model Pipeline PTransform PCollection (bounded or unbounded)
- 10. 10 Beam Model: Asking the Right Questions What results are calculated? Where in event time are results calculated? When in processing time are results materialized? How do refinements of results relate?
- 11. The Beam Model: What is Being Computed? PCollection<KV<String, Integer>> scores = input .apply(Sum.integersPerKey()); scores= (input | Sum.integersPerKey())
- 12. The Beam Model: What is Being Computed?
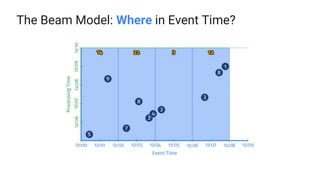
- 13. The Beam Model: Where in Event Time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) .apply(Sum.integersPerKey()); scores= (input | beam.WindowInto(FixedWindows(2 * 60)) | Sum.integersPerKey())
- 14. The Beam Model: Where in Event Time?
- 15. The Beam Model: When in Processing Time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark())) .apply(Sum.integersPerKey()); scores = (input | beam.WindowInto(FixedWindows(2 * 60) .triggering(AtWatermark())) | Sum.integersPerKey())
- 16. The Beam Model: When in Processing Time?
- 17. The Beam Model: How Do Refinements Relate? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark() .withEarlyFirings(AtPeriod(Duration.standardMinutes(1))) .withLateFirings(AtCount(1))) .accumulatingFiredPanes()) .apply(Sum.integersPerKey()); scores = (input | beam.WindowInto(FixedWindows(2 * 60) .triggering(AtWatermark() .withEarlyFirings(AtPeriod(1 * 60)) .withLateFirings(AtCount(1))) .accumulatingFiredPanes()) | Sum.integersPerKey())
- 18. The Beam Model: How Do Refinements Relate?
- 19. Example of Pythonic Beam Code import apache_beam as beam with beam.Pipeline() as p: (p | beam.io.ReadStringsFromPubSub("twitter_topic") | beam.WindowInto(SlidingWindows(5*60, 1*60)) | beam.Map(ParseHashTagDoFn()) | beam.CombinePerKey(sum) | beam.Map(BigQueryOutputFormatDoFn()) | beam.io.WriteToBigQuery("trends_table"))
- 20. Runners Google Cloud Dataflow Apache FlinkApache SparkApache Apex Ali Baba JStorm Apache Beam Direct Runner Apache Storm WIP Apache Gearpump Runners “translate” the code into the target runtime * Same code, different runners & runtimes Hadoop MapReduce IBM StreamsApache Samza
- 21. 21 Awesome but... ● Can a Python pipeline run on any of the Java/JVM based runners? ● Can I use the Python Tensorflow transform from a Java pipeline? ● I want to read from Kafka in my Python pipeline, but there is no connector - can I use the Java implementation? Beam Model: Fn Runners Apache Flink Apache Spark Beam Model: Pipeline Construction Other LanguagesBeam Java Beam Python Execution Execution Cloud Dataflow Execution
- 23. What are we trying to solve?
- 24. Portability Framework SDK (Python, Go, Java) Job Service Artifact Staging Staging Location (DFS, S3, …) Flink Job Job Manager Fn Services SDK Harness / UDFs Task Manager Task Manager Executor / Fn API Provision Control Data Artifact Retrieval State Logging Task Manager gRPC Pipeline (protobuf) Cluster Runner Dependencies (optional) python -m apache_beam.examples.wordcount --input=/etc/profile --output=/tmp/py-wordcount-direct --experiments=beam_fn_api --runner=PortableRunner --sdk_location=container --job_endpoint=localhost:8099 --streaming
- 25. 25 APIs for Different Pipeline Lifecycle Stages Pipeline API ● Used by the SDK to construct SDK-agnostic Pipeline representation ● Used by the Runner to translate a Pipeline to runner- specific operations Fn API ● Used by an SDK harness for communication with a Runner ● User by the Runner to push work into an SDK harness Job API ● Launching and interacting with a running Pipeline
- 26. 26 Pipeline API (simplified) ● Definition of common primitive transformations (Impulse, ExecutableStage, Flatten, AssignWindow, GroupByKey, Reshuffle) ● Definition of serialized Pipeline (protobuf) https://s.apache.org/beam-runner-api Pipeline = {PCollection*, PTransform*, WindowingStrategy*, Coder*} PTransform = {Inputs*, Outputs*, FunctionSpec} FunctionSpec = {URN, payload}
- 27. 27 Fn API gRPC interfaces for communication between SDK harness and Runner https://s.apache.org/beam-fn-api ● Control: Used to tell the SDK which UDFs to execute and when to execute them. ● Data: Used to move data between the language specific SDK harness and the runner. ● State: Used to support user state, side inputs, and group by key reiteration. ● Logging: Used to aggregate logging information from the language specific SDK harness.
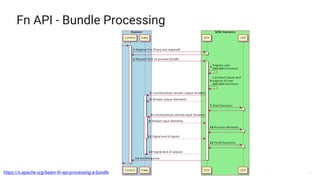
- 28. 28 Fn API - Bundle Processing https://s.apache.org/beam-fn-api-processing-a-bundle
- 29. Fn API - Data https://s.apache.org/beam-fn-api-send-and-receive-data
- 30. Fn API - State User state, side inputs https://s.apache.org/beam-fn-state-api-and-bundle-processing
- 31. Fn API - Timers https://s.apache.org/beam-portability-timers
- 32. 32 Fn API - Processing DoFns (Executable Stages) https://s.apache.org/beam-fn-api-send-and-receive-data Say we need to execute this part
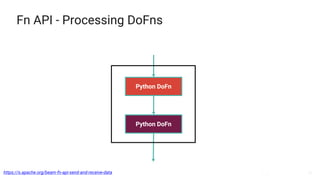
- 33. 33 Fn API - Processing DoFns https://s.apache.org/beam-fn-api-send-and-receive-data Python DoFn Python DoFn
- 34. 34 Fn API - Processing DoFns (Pipeline manipulation) https://s.apache.org/beam-fn-api-send-and-receive-data Python DoFn Python DoFn gRPC Source gRPC Sink The Runner inserts these
- 35. 35 Fn API - Executing the user Fn in the SDK Harness ● Environments ○ Docker container ○ Separate process (BEAM-5187) ○ Embedded (SDK and runner same language) - TBD ● Repository of containers for different SDKs ● Container is user-configurable ● User code can be added to container at runtime (artifact retrieval service) Runner Fn API https://s.apache.org/beam-fn-api-container-contract
- 36. 3636 Executing Pythonic* Beam Jobs on Fink *or other languages
- 37. 37 What is the (Flink) Runner doing in all this? ● Provide Job Service endpoint (Job Management API) ● Translate portable pipeline representation to native API ● Provide gRPC endpoints for control/data/logging/state plane ● Manage SDK Harness processes that execute user code ● Execute bundles (with arbitrary user code) using the Fn API ● Manage state for side inputs, user state/timers Reference runner provides common implementation baseline for JVM based runners (/runners/java-fn-execution) and we have a portable Validate Runner integration test suite in Python!
- 38. 38 What’s specific to the Flink Runner? ● Job Server packaging (fat jar and docker container) ● Pipeline translators for batch (DataSet) and streaming (DataStream) ○ Translation/operators for primitive URNs: Impulse, Flatten, GBK, Assign Windows, Executable Stage, Reshuffle ● Side input handlers based on Flink State ● User State and Timer integration (TBD) ● Flink Job Launch (same as old, non-portable runner)
- 39. 39 Advantages/Disadvantages ● Support for code written in non-JVM languages ● Complete isolation of user code ● Configurability of execution environment (Docker, ...) ● Ability to mix code written in different languages in a single pipeline (future) ● Slower (RPC overhead) ● Using Docker requires docker 😉 ○ Direct Process Executor WIP ● Early Adoption (complete runner overhaul)
- 41. Feature Support Matrix as of Beam 2.7.0 https://s.apache.org/apache-beam-portability-support-table
- 42. 4242 Demo
- 43. 4343 The Future
- 44. 44 Future work ● Support for user state and timers ● Mixing and matching connectors written in different languages ● Wait for new SDKs in other languages, they will just work 😉 ● Unified batch and streaming API in Flink? ○ currently 4 Flink translators (batch + streaming for each, portable and old, Java-only runner) ● Beam Flink Runner compatibility story ○ Flink upgrades ○ Pipeline upgrades / state migration
- 45. We are hiring! lyft.com/careers https://goo.gl/RsyLkS Streaming@Lyft
- 47. 47 Learn More! Beam Portability Framework https://beam.apache.org/contribute/portability/ https://beam.apache.org/contribute/design-documents/#portability Apache Beam https://beam.apache.org https://s.apache.org/slack-invite #beam #beam-portability https://beam.apache.org/community/contact-us/ Follow @ApacheBeam on Twitter Thank you!
Editor's Notes
- #6: These slides provide a brief introduction to the Apache Beam model. You are welcome to reuse all or some of these slides when discussing Apache Beam, but please give credit to the original authors when appropriate. ;-) Frances Perry (fjp@google.com) Tyler Akidau (takidau@google.com) Please comment if you have suggestions or see things that are out of date -- we’d like to keep these fresh and usable for everyone. These slides were adapted in part from a talk at GCP Next in March 2016: https://www.youtube.com/watch?v=mJ5lNaLX5Bg Depending on your audience, you may want to adjust or augment this material with other Beam talks.
- #7: Today, Apache Beam includes the core unified programming model revolving around the what/where/when/how questions the initial Java SDK that we developed as part of Cloud Dataflow, with others, including Python, to follow and, most important for portability, multiple runners that can execute Beam pipelines on existing distributed process backends.
- #8: Our goal in Beam is to fully support three different categories of users End users who are just interested in writing data processing pipelines. They want to use the language that they want to use and choose the runtime that works for them, whether it’s on premise, on a hand tuned cloud cluster, or on a fully managed service. In addition, we want to develop stable APIs and documentation to allow others in the open source community to create Beam SDKs in other languages and to provide runners for alternate distributed processing environments.
- #11: The Beam model is based on four key questions: What results are calculated? Are you doing computing sums, joins, histograms, machine learning models? Where in event time are results calculated? How does the time each event originally occurred affect results? Are results aggregated for all time, in fixed windows, or as user activity sessions? When in processing time are results materialized? Does the time each element arrives in the system affect results? How do we know when to emit a result? What do we do about data that comes in late from those pesky users playing on transatlantic flights? And finally, how do refinements relate? If we choose to emit results multiple times, is each result independent and distinct, do they build upon one another? Let’s take a quick look at how we can use this questions to build a pipeline.
- #12: Here’s a snippet from a pipeline that processes scoring results from that mobile gaming application. In yellow, you can see the computation that we’re performing -- the what -- in this case taking team-score pairs and summing them per team. So now let’s see what happens to our sample data if we execute this in traditional batch style.
- #13: In this looping animation, the grey line represents processing time. As the pipeline executes and processes elements, they’re accumulated into the intermediate state, just under the processing time line. When processing completes, the system emits the result in yellow. This is pretty standard batch processing. But let’s see how answering the remaining three questions can make this more expressive.
- #14: Let’s start by playing with event time. By specifying a windowing function, we can calculate independent results for different slices of event time. For example every minute, every hour, or every day. In this case, we will calculate an independent sum for every two minute window.
- #15: Now if we look at how things execute, you can see that we are calculating a independent answer for every two minute period of event time. But we’re still waiting until the entire computation completes to emit any results. That might work fine for bounded data sets, when we’ll eventually finish processing. But it’s not going to work if we’re trying to process an infinite amount of data!
- #16: So what we need to do is reduce the latency of individual results. We do that by asking for results to be emitted, or triggered, based on the system’s best estimate of when it has all the input data. We call this estimate the watermark.
- #17: Now the graph contains the watermark drawn in green. And by triggering at the watermark, the result for each window is emitted as soon as we roughly think we’re done seeing data for that slice of time. But again, the watermark is often just a heuristic -- it’s the system’s best guess about data completeness. Right now, the watermark is too fast -- and so in some cases we’re moving on without all the data. So that user who scored 9 points in the elevator is just plain out of luck. Those 9 points don’t get included in their team’s score. But we don’t want to be too slow either -- it’s no good if we wait to emit anything until all the flights everywhere had landed just in case someone in seat 16B is playing our game somewhere over the Atlantic.
- #18: So let’s use a more sophisticated trigger to request both speculative, early firings as data is still trickling in -- and also update results if late elements arrive. Once we do this though, we might get multiple results for the same window of event time. So we have answer the fourth question about how refined results relate. Here we choose to just continually accumulate the score.
- #19: Now, there are multiple results for each window. Some windows, like the second, produce early, incomplete results as data arrives. There’s one on time result per window when we think we’ve pretty much got all the data. And there are late results if additional data comes in behind the watermark, like in the first window. And because we chose to accumulate, each result includes all the elements in the window, even if they have already been part of an earlier result.
- #20: Here’s a snippet from a pipeline that processes scoring results from that mobile gaming application. In yellow, you can see the computation that we’re performing -- the what -- in this case taking team-score pairs and summing them per team. So now let’s see what happens to our sample data if we execute this in traditional batch style.
- #21: Runners “translate” the code to a target runtime (the runner itself doesn’t provide the runtime)
- #24: Executing user code written in any language (Python) on a Runner written in a different language (Java) Mixing user functions written in different languages (Sources, Sinks, …)
- #25: Pipeline is now represented in a SDK agnostic way (Protobuf) Job interaction with running Pipeline Fn SDK harness to runner interaction, runner push work harness answer
- #30: GRPC LIMIT HACK
- #43: Show code Submit job Show the running Job in the Flink dashboard (Maybe show results)