Scraping Scripting Hacking
9 likes1,349 views

The document outlines various methods for scraping data from websites lacking APIs, emphasizing a non-technical approach suitable for those with minimal programming skills. It details extraction techniques using tools like Yahoo! Pipes, Google Docs, Dapper, YQL, and HTTrack, while also discussing data munging practices to refine and process scraped data. The overarching theme promotes the idea of accessing open data freely and creatively despite limitations.
![scraping,
http://www.flickr.com/photos/juan23/82888194/
scripting and
hacking your way to
API-less data
[AKA: if you don’t have data
feeds, we’ll get it anyway]](https://image.slidesharecdn.com/scrapingscriptinghacking-090707060418-phpapp02/85/Scraping-Scripting-Hacking-1-320.jpg)











![munging #1: regex!
• I’m terrible at regex
• ([A-PR-UWYZ0-9][A-HK-Y0-9]
[AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]? {1,2}
[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)
• but it’s incredibly powerful...
output](https://image.slidesharecdn.com/scrapingscriptinghacking-090707060418-phpapp02/85/Scraping-Scripting-Hacking-16-320.jpg)








Scraping Scripting Hacking
- 1. scraping, http://www.flickr.com/photos/juan23/82888194/ scripting and hacking your way to API-less data [AKA: if you don’t have data feeds, we’ll get it anyway]
- 2. overview • “getting data out” • non-exhaustive (and rapid!) • slightly random • live examples (hopefully) • mainly non-technical(ish) • mainly non-illegal. I think.
- 3. anything goes • have no fear! • feel no remorse! • be shameless! • long live the open data revolution!
- 4. you • half newbie, half “done some”
- 5. me • not really a developer • ..but code enough ASP (stop giggling) to do what I want to do • slides will be at slideshare.net/dmje • www.electronicmuseum.org.uk • mike.ellis@eduserv.org.uk
- 6. we <3 data • we want programmatic access... • ...but sites are often lacking • ...and APIs are usually a pipe dream http://www.ucas.com/instit/i/h60.html http://unicorn.lib.ic.ac.uk/uhtbin/opac/webcentral
- 7. scraping • copy & paste, without having to copy & paste... • an inexact but really rather beautiful science Set xmlhttp = Server.CreateObject("MSXML2.ServerXMLHTTP.4.0") Call xmlhttp.Open("GET",url,False) Call xmlhttp.send ReturnedXML = xmlhttp.responsetext
- 8. scraping (cont) • frowned on by purists... • but really rather powerful • http://hoard.it
- 9. extraction #1: Y!Pipes • find your data on page • view source • determine the delimeters • put it into Pipes • extract the output originating page | output
- 10. extraction #2: Google Docs • create a new google spreadsheet • find the URL of the data you want • identify how it is encapsulated (list/ table) • use the importHTML() function (others for feeds, xml, data, etc) • dump out data as...CSV/XML/RSS/etc originating page | output
- 11. extraction #3: dapper.net • go to dapper.net/open • identify several of the urls with the same “shapes” that you want to scrape • use the dapper dashboard to identify content areas • build the “dapp” • pass in url’s of pages you want to extract data from • extract results from the output (xml, flash, csv, etc) originating page | output
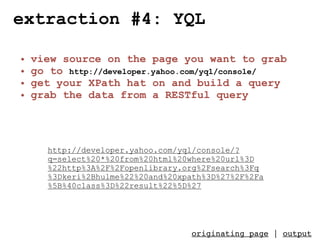
- 12. extraction #4: YQL • view source on the page you want to grab • go to http://developer.yahoo.com/yql/console/ • get your XPath hat on and build a query • grab the data from a RESTful query http://developer.yahoo.com/yql/console/? q=select%20*%20from%20html%20where%20url%3D %22http%3A%2F%2Fopenlibrary.org%2Fsearch%3Fq %3Dkeri%2Bhulme%22%20and%20xpath%3D%27%2F%2Fa %5B%40class%3D%22result%22%5D%27 originating page | output
- 13. extraction #5: httrack • grab a copy of httrack (or similar)from http://www.httrack.com/ • point it at the bit of the site you want, make sure the filters are correct, and push go... • you now have a local copy of the site, to munge as you see fit
- 14. extraction #6: hacked search • get an API key from Yahoo! • use it to search within a domain • script a standard download script to pick out each page and download it • hack that mumma • (variation on a theme: build a simple spider...)
- 15. now you’ve got your data.. • once you’ve got your data, you usually need to munge it...
- 16. munging #1: regex! • I’m terrible at regex • ([A-PR-UWYZ0-9][A-HK-Y0-9] [AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]? {1,2} [0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA) • but it’s incredibly powerful... output
- 17. munging #2: find/replace • use whatever scripting language you work best with • (even Word...) • you’ll find that replace double space, replace weird characters, replace paragraph marks are about the most common needs
- 18. munging #3: mail merge! • for rapid builds of html, javascript or xml • have a source document (often extracted or munged from other sites) in Excel • you can use filters to effectively grab the data you need • build the merge in Word, using the “directory” option • copy and paste the result out
- 19. munging #4: html removal • have a function handy that you can pass a block of html • it is handy to have a script where you can define which particular tags to remove or leave in place
- 20. munging #5: html tidy • grab a copy of html tidy from http://tidy.sourceforge.net/ • tidy is available as a downloadable .exe or a component that you can pass data to in your code
- 21. processing #1: Open Calais • a service from Reuters for analysing blocks of text for semantic “meaning” • get an API key from Open Calais • send data via a POST to the REST service • retrieve results from the RDF • OR...just paste your text into http://sws.clearforest.com/calaisviewer/ output
- 22. processing #2: Yahoo! TE • a webservice for grabbing tags/terms from blocks of text • sign up for a Yahoo! API key • pass your block of text using POST • grab the results.. output
- 23. processing #3: geo! • go to http://developer.yahoo.com/geo !
- 24. the ugly sisters • Access • Excel (!)
- 25. the last resorts • FOI (frankie!) • OCR (me)
- 26. the very last resort.. • re-type it... • (or use Amazon Mechanical Turk)
- 27. ...any more?