


![BERT를 Pre-training (mask filling, next sentence prediction)
입력 문장: 위키백과는 위키를 이용하여 전 세계 사람들이 함께 만들어가는 [MASK] 기반의 다언
입니다
→ 위키백과는 위키를 이용하여 전 세계 사람들이 함께 만들어가는 웹 기반의 다언어 백과사전 입니다.
BERT를 이용하여 Relation extraction을 한다면?
입력 문장: 하비에르 파스토레는 아르헨티나 클럽 타예레스의 유소년팀에서 축구를 시작하였다.
X)
→ per:origin [index3]
Prompt Learning
언어 모델을 fine-tuning할 때의 task와 pre-training하는 task의 연관성이 떨어지는 기존의 fine-
tuning 의 약점을 극복](https://image.slidesharecdn.com/sentipromptsentimentknowledgeenhancedprompt-tuningforaspect-basedsentimentanalysis-220128071725/85/Senti-prompt-sentiment-knowledge-enhanced-prompt-tuning-for-aspect-based-sentiment-analysis-4-320.jpg)
![Template
e1 은/는 [Label_1]이고 e2는
ex) 하비에르 파스토레 은/는 사람이고
아르헨티나는 출신이다.
→ 입력 문장 : 하비에르 파스토레 은/는
[MASK]이고 아르헨티나는 [MASK]이다.
언어 모델을 fine-tuning할 때의 task와 pre-training하는 task의 연관성이 떨어지는 기존의 fine-
tuning 의 약점을 극복
Prompt Learning](https://image.slidesharecdn.com/sentipromptsentimentknowledgeenhancedprompt-tuningforaspect-basedsentimentanalysis-220128071725/85/Senti-prompt-sentiment-knowledge-enhanced-prompt-tuning-for-aspect-based-sentiment-analysis-5-320.jpg)



![TASK FORMULATION-input
• The ___ is ___? [MASK] 문장이 consistent 하면 [MASK]은 YES
문장이 inconsistent 하면 [MASK]은 NO
• 위의 답이 YES 인 경우, This is [MASK] 긍정문이면 POS
부정문이면 NEG](https://image.slidesharecdn.com/sentipromptsentimentknowledgeenhancedprompt-tuningforaspect-basedsentimentanalysis-220128071725/85/Senti-prompt-sentiment-knowledge-enhanced-prompt-tuning-for-aspect-based-sentiment-analysis-9-320.jpg)
![TASK FORMULATION-input
• [P1] ___ [P2] ___? [MASK] P1 과 P2 를 LM 모델로 자동 생성
• [P3] [MASK] P3 를 LM 모델로 자동 생성](https://image.slidesharecdn.com/sentipromptsentimentknowledgeenhancedprompt-tuningforaspect-basedsentimentanalysis-220128071725/85/Senti-prompt-sentiment-knowledge-enhanced-prompt-tuning-for-aspect-based-sentiment-analysis-10-320.jpg)













Senti prompt sentiment knowledge enhanced prompt tuning for aspect-based sentiment analysis
- 1. SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis 자연어처리팀: 김수빈, 신문종, 박희수(발표자), 조진욱, 진명훈, 황경진
- 2. Aspect-based sentiment analysis (ABSA)
- 3. Aspect-based sentiment analysis (ABSA)
- 4. BERT를 Pre-training (mask filling, next sentence prediction) 입력 문장: 위키백과는 위키를 이용하여 전 세계 사람들이 함께 만들어가는 [MASK] 기반의 다언 입니다 → 위키백과는 위키를 이용하여 전 세계 사람들이 함께 만들어가는 웹 기반의 다언어 백과사전 입니다. BERT를 이용하여 Relation extraction을 한다면? 입력 문장: 하비에르 파스토레는 아르헨티나 클럽 타예레스의 유소년팀에서 축구를 시작하였다. X) → per:origin [index3] Prompt Learning 언어 모델을 fine-tuning할 때의 task와 pre-training하는 task의 연관성이 떨어지는 기존의 fine- tuning 의 약점을 극복
- 5. Template e1 은/는 [Label_1]이고 e2는 ex) 하비에르 파스토레 은/는 사람이고 아르헨티나는 출신이다. → 입력 문장 : 하비에르 파스토레 은/는 [MASK]이고 아르헨티나는 [MASK]이다. 언어 모델을 fine-tuning할 때의 task와 pre-training하는 task의 연관성이 떨어지는 기존의 fine- tuning 의 약점을 극복 Prompt Learning
- 7. ABSA task는 aspect terms, sentiment polarity, opinion terms을 제공하는 것이 목표 TASK FORMULATION
- 8. • Polarity s는 POS, NEG, NEU의 3가지 tag • Aspect와 opinion은 token span 의 시작과 끝 index TASK FORMULATION-output
- 9. TASK FORMULATION-input • The ___ is ___? [MASK] 문장이 consistent 하면 [MASK]은 YES 문장이 inconsistent 하면 [MASK]은 NO • 위의 답이 YES 인 경우, This is [MASK] 긍정문이면 POS 부정문이면 NEG
- 10. TASK FORMULATION-input • [P1] ___ [P2] ___? [MASK] P1 과 P2 를 LM 모델로 자동 생성 • [P3] [MASK] P3 를 LM 모델로 자동 생성
- 11. 학습 데이터 생성 • The sushi is good? Yes • This is positive. • The price is high? Yes • This is negative. • Ground Truth triplet (Aspect, Opinion, Polarity) • (Sushi, Good, POS) • (Price, High, NEG) • The sushi is high? No
- 12. 학습 데이터 생성 • The good sushi is high? No • Ground Truth triplet (Aspect, Opinion, Polarity) • (Sushi, Good, POS) • (Price, High, NEG) Span manipulation
- 13. • POS, NEG, NEU에 더해 consistent한지 아닌지 yes, no term을 붙어서 label은 5개가 됨 Sentiment Knowledge Enhanced Prompt Construction
- 14. • 더 좋은 prompt representation을 위해 prompt encode를 따로 둔다 (vocab은 공유) • P1, P2, … , P4 (pseudo prompt)에 대해서 만 encoding 하고 aspect, opinion token 은 그대로 사용 Prompt Encoder
- 15. 전체 모델
- 16. Prompt Encoder
- 17. Generation Framework for ABSA • Inference 시에는 문장에서 모든 후보 aspect 와 opinion 을 추출한 후 • BART encoder 로 인코딩한 임베딩을 index generator 에 넣는다. • Index generator 는 target 의 index 를 생성하고, • 이 target 인덱스와 임베딩을 디코더에 넣어, 타겟 aspect 와 opinion 의 polarity 를 생성한 다.
- 19. • 네 개의 ABSA 데이터셋의 3개 버전 • 1번째 버전: (Peng) 에서 가져와서 triplet 형태로 변환 • 2번째 버전: 1번째 버전에서 missing, triplet 을 채워 넣음 • 3번째 버전: 2번째 버전에서 잘못 annotation 된 것 등을 수정 • 문장이 긴 경우에 모자란 triplet 을 추가함 • 부사가 포함되었다가 안되었다가 한 경우가 있어서 일괄적으로 포함시킴 • 대명사의 경우에는 잘못되어 있어서 이를 고침 데이터셋
- 20. • 모든 데이터셋에서 더 나은 성능 을 보임 • D20b 에 비해서 D21에서 더 낮은 성능을 보임 • 14res 만 제외하고 모든 데이터 에서 제안한 방법이 최고의 성능 을 보였음 Main Results
- 21. • 긴 문장이 주어지고 여러 개의 답안 이 있을 때, • OTE-MTL은 딱 하나만 맞춤 • GTS 는 그 하나에 margaritas 바로 뒤에 오 는 형용사를 잡아냄 • SPAN-BART 는 마지막 waitress 에 대해 잡 는 것 실패 • 제안한 논문은 가장 근접하게 세 개를 잡아냄 Main Results
- 22. • Few-shot ABSA • Training dataset 의 10% 만을 사 용하여 few-shot 에 도전 • 5번 랜덤하게 10% 를 뽑아서 성능 측정 • 14에서는 best 이지만 high variance 에서는 성능이 잘 안나 옴 Analysis
- 23. • Prompt Length Analysis • N = l1 = l2−l1 = lP −l2 • N 을 1,2,3 으로 조정하며 성능 테스트 • 대부분 auto-constructed 가 manual 보다 더 좋은 성능을 보 임 • 토큰의 개수가 성능에 큰 영향 을 미침 Analysis
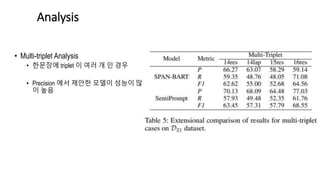
- 24. • Multi-triplet Analysis • 한문장에 triplet 이 여러 개 인 경우 • Precision 에서 제안한 모델이 성능이 많 이 높음 Analysis
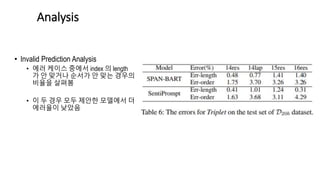
- 25. • Invalid Prediction Analysis • 에러 케이스 중에서 index 의 length 가 안 맞거나 순서가 안 맞는 경우의 비율을 살펴봄 • 이 두 경우 모두 제안한 모델에서 더 에러율이 낮았음 Analysis