Spark Streaming | Twitter Sentiment Analysis Example | Apache Spark Training | Edureka
12 likes2,955 views

The document provides an overview of Apache Spark Streaming, including its ecosystem, features, and workflows for processing real-time data. It discusses core concepts like DStreams, transformations, caching, and output operations, as well as practical applications, such as Twitter sentiment analysis. Spark Streaming is highlighted for its high throughput, fault tolerance, and integration capabilities with existing data sources like Kafka and HDFS.




































![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Output Operations on DStreams
Currently, the following output operations are defined:
Output Operations
print()
saveAsTextFiles
(prefix, [suffix])
saveAsObjectFiles
(prefix, [suffix])
saveAsHadoopFiles
(prefix, [suffix])
foreachRDD(func)](https://image.slidesharecdn.com/sparkstreaming-sparktutorial-edureka-170424093710/85/Spark-Streaming-Twitter-Sentiment-Analysis-Example-Apache-Spark-Training-Edureka-40-320.jpg)





registerBroadcastForCleanup
broadcast(value)
Figure: SparkContext and Broadcasting](https://image.slidesharecdn.com/sparkstreaming-sparktutorial-edureka-170424093710/85/Spark-Streaming-Twitter-Sentiment-Analysis-Example-Apache-Spark-Training-Edureka-46-320.jpg)





![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Use Case – Twitter Token Authorization
object mapr {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: TwitterPopularTags <consumer key>
<consumer secret> " +
"<access token> <access token secret> [<filters>]")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
//Passing our Twitter keys and tokens as arguments for authorization
val Array(consumerKey, consumerSecret, accessToken,
accessTokenSecret) = args.take(4)
val filters = args.takeRight(args.length - 4)](https://image.slidesharecdn.com/sparkstreaming-sparktutorial-edureka-170424093710/85/Spark-Streaming-Twitter-Sentiment-Analysis-Example-Apache-Spark-Training-Edureka-53-320.jpg)
![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Use Case – DStream Transformation
// Set the system properties so that Twitter4j library used by twitter stream
// Use them to generate OAuth credentials
System.setProperty("twitter4j.oauth.consumerKey", consumerKey)
System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret)
System.setProperty("twitter4j.oauth.accessToken", accessToken)
System.setProperty("twitter4j.oauth.accessTokenSecret",
accessTokenSecret)
val sparkConf = new
SparkConf().setAppName("Sentiments").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val stream = TwitterUtils.createStream(ssc, None, filters)
//Input DStream transformation using flatMap
val tags = stream.flatMap { status =>
status.getHashtagEntities.map(_.getText)}](https://image.slidesharecdn.com/sparkstreaming-sparktutorial-edureka-170424093710/85/Spark-Streaming-Twitter-Sentiment-Analysis-Example-Apache-Spark-Training-Edureka-54-320.jpg)














Spark Streaming | Twitter Sentiment Analysis Example | Apache Spark Training | Edureka
- 2. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING What to expect? What is Streaming? Spark Ecosystem Why Spark Streaming? Spark Streaming Overview DStreams DStream Transformations Caching/ Persistence Accumulators, Broadcast Variables and Checkpoints Use Case – Twitter Sentiment Analysis
- 3. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING What is Streaming?
- 4. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING What is Streaming? Data Streaming is a technique for transferring data so that it can be processed as a steady and continuous stream. Streaming technologies are becoming increasingly important with the growth of the Internet. “Without stream processing there’s no big data and no Internet of Things” – Dana Sandu, SQLstream User Streaming Sources Live Stream Data
- 5. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Ecosystem
- 6. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Used for structured data. Can run unmodified hive queries on existing Hadoop deployment Spark Core Engine Spark SQL (SQL) Spark Streaming (Streaming) MLlib (Machine Learning) GraphX (Graph Computation) SparkR (R on Spark) Enables analytical and interactive apps for live streaming data Package for R language to enable R-users to leverage Spark power from R shell Machine learning libraries being built on top of Spark The core engine for entire Spark framework. Provides utilities and architecture for other components Graph Computation engine (Similar to Giraph). Combines data- parallel and graph- parallel concepts Spark Ecosystem
- 7. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Used for structured data. Can run unmodified hive queries on existing Hadoop deployment Spark Core Engine Spark SQL (SQL) Spark Streaming (Streaming) MLlib (Machine Learning) GraphX (Graph Computation) SparkR (R on Spark) Package for R language to enable R-users to leverage Spark power from R shell Machine learning libraries being built on top of Spark The core engine for entire Spark framework. Provides utilities and architecture for other components Graph Computation engine (Similar to Giraph). Combines data- parallel and graph- parallel concepts Enables analytical and interactive apps for live streaming data Spark Ecosystem
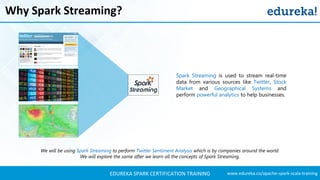
- 8. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Why Spark Streaming?
- 9. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Why Spark Streaming? We will be using Spark Streaming to perform Twitter Sentiment Analysis which is by companies around the world. We will explore the same after we learn all the concepts of Spark Streaming. Spark Streaming is used to stream real-time data from various sources like Twitter, Stock Market and Geographical Systems and perform powerful analytics to help businesses.
- 10. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Overview
- 11. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Overview Spark Streaming is used for processing real-time streaming data It is a useful addition to the core Spark API Spark Streaming enables high-throughput and fault-tolerant stream processing of live data streams The fundamental stream unit is DStream which is basically a series of RDDs to process the real-time data Figure: Streams In Spark Streaming
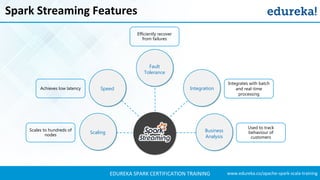
- 12. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Features Business Analysis Integration Scaling Achieves low latency Integrates with batch and real-time processing Used to track behaviour of customers Scales to hundreds of nodes Speed Fault Tolerance Efficiently recover from failures
- 13. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Workflow Figure: Overview Of Spark Streaming MLlib Machine Learning Spark SQL SQL + DataFrames Spark Streaming Streaming Data Sources Static Data Sources Data Storage Systems
- 14. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Workflow Kafka HDFS/ S3 Flume Streaming Twitter Kinesis Databases HDFS Dashboards Figure: Data from a variety of sources to various storage systems
- 15. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Workflow Kafka HDFS/ S3 Flume Streaming Twitter Kinesis Databases HDFS Dashboards Figure: Data from a variety of sources to various storage systems Streaming Engine Input Data Stream Batches Of Input Data Batches Of Processed Data Figure: Incoming streams of data divided into batches
- 16. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Workflow Kafka HDFS/ S3 Flume Streaming Twitter Kinesis Databases HDFS Dashboards Figure: Data from a variety of sources to various storage systems Streaming Engine Input Data Stream Batches Of Input Data Batches Of Processed Data Figure: Incoming streams of data divided into batches Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 RDD @ Time 1 RDD @ Time 2 RDD @ Time 3 RDD @ Time 4 DStream Figure: Input data stream divided into discrete chunks of data
- 17. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Streaming Workflow Kafka HDFS/ S3 Flume Streaming Twitter Kinesis Databases HDFS Dashboards Figure: Data from a variety of sources to various storage systems Streaming Engine Input Data Stream Batches Of Input Data Batches Of Processed Data Figure: Incoming streams of data divided into batches Figure: Extracting words from an InputStream Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 RDD @ Time 1 RDD @ Time 2 RDD @ Time 3 RDD @ Time 4 DStream Figure: Input data stream divided into discrete chunks of data Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 DStream Words From Time 0 to 1 Words From Time 1 to 2 Words From Time 2 to 3 Words From Time 3 to 4 Words DStream flatMap Operation
- 18. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Fundamentals
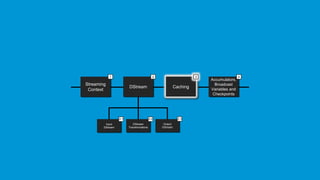
- 19. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Fundamentals The following gives a flow of the fundamentals of Spark Streaming that we will discuss in the coming slides: Streaming Context DStream Input DStream DStream Transformations Output DStream Caching Accumulators, Broadcast Variables and Checkpoints 1 2 3 4 2.1 2.32.2
- 20. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DStream Input DStream DStream Transformations Output DStream Caching Accumulators, Broadcast Variables and Checkpoints 2 3 4 2.1 2.32.2 Streaming Context 1
- 21. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context StreamingContext Consumes a stream of data in Spark. Registers an InputDStream to produce a Receiver object. Figure: Default Implementation Sources Streaming Context Input Data Stream Batches Of Input Data Figure: Spark Streaming Context It is the main entry point for Spark functionality. Spark provides a number of default implementations of sources like Twitter, Akka Actor and ZeroMQ that are accessible from the context.
- 22. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context – Initialization A StreamingContext object can be created from a SparkContext object. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on that cluster. import org.apache.spark._ import org.apache.spark.streaming._ var ssc = new StreamingContext(sc,Seconds(1))
- 23. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context Input DStream DStream Transformations Output DStream Caching Accumulators, Broadcast Variables and Checkpoints 1 3 4 2.1 2.32.2 DStream 2
- 24. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DStream Discretized Stream (DStream) is the basic abstraction provided by Spark Streaming. It is a continuous stream of data. Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 RDD @ Time 1 RDD @ Time 2 RDD @ Time 3 RDD @ Time 4 DStream Figure: Input data stream divided into discrete chunks of data It is received from source or from a processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs and each RDD contains data from a certain interval.
- 25. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DStream Operation Any operation applied on a DStream translates to operations on the underlying RDDs. For example, in the example of converting a stream of lines to words, the flatMap operation is applied on each RDD in the lines DStream to generate the RDDs of the words DStream. Figure: Extracting words from an InputStream Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 DStream Words From Time 0 to 1 Words From Time 1 to 2 Words From Time 2 to 3 Words From Time 3 to 4 Words DStream flatMap Operation
- 26. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context DStream Transformations Output DStream Caching Accumulators, Broadcast Variables and Checkpoints 1 3 4 2.32.2 Input DStream DStream 2.1 2
- 27. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Input DStreams Input DStream Basic Source File Systems Socket Connections Advanced Source Kafka Flume Kinesis Input DStreams are DStreams representing the stream of input data received from streaming sources. Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 RDD @ Time 1 RDD @ Time 2 RDD @ Time 3 RDD @ Time 4 DStream Figure: Input data stream divided into discrete chunks of data
- 28. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Receiver Figure: The Receiver sends data onto the DStream where each Batch contains RDDs Every input DStream is associated with a Receiver object which receives the data from a source and stores it in Spark’s memory for processing.
- 29. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context Input DStream Output DStream Caching Accumulators, Broadcast Variables and Checkpoints 1 3 4 2.1 2.3 DStream Transformations DStream 2.2 2
- 30. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams Transformations allow the data from the input DStream to be modified similar to RDDs. DStreams support many of the transformations available on normal Spark RDDs. flatMap filter reduce groupBy map Most Popular Spark Streaming Transformations DStream 1 Transform Drop split point DStream 2 Figure: DStream Transformations
- 31. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams map map(func) map(func) returns a new DStream by passing each element of the source DStream through a function func. map Input Data Stream Batches Of Input Data Node Figure: Input DStream being converted through map(func) Figure: Map Function filter flatMap groupBy reduce
- 32. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams flatMap map filter reduce groupBy Figure: flatMap Function flatMap(func) flatMap(func) is similar to map(func) but each input item can be mapped to 0 or more output items and returns a new DStream by passing each source element through a function func. Figure: Input DStream being converted through flatMap(func) flatMap Input Data Stream Batches Of Input Data Node
- 33. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams filter map flatMap reduce groupBy filter(func) filter(func) returns a new DStream by selecting only the records of the source DStream on which func returns true. Figure: Input DStream being converted through filter(func) filter Input Data Stream Batches Of Input Data Node Figure: Filter Function For Even Numbers
- 34. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams reduce map filter flatMap groupBy Figure: Reduce Function To Get Cumulative Sum reduce(func) reduce(func) returns a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func. Figure: Input DStream being converted through reduce(func) reduce Input Data Stream Batches Of Input Data Node
- 35. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Transformations on DStreams groupBy map filter reduce flatMap groupBy(func) groupBy(func) returns the new RDD which basically is made up with a key and corresponding list of items of that group. Figure: Input DStream being converted through groupBy(func) groupBy Input Data Stream Batches Of Input Data Node Figure: Grouping By First Letters
- 36. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DStream Window
- 37. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DStream Window Spark Streaming also provides windowed computations which allow us to apply transformations over a sliding window of data. The following figure illustrates this sliding window: Figure: DStream Window Transformation
- 38. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context Input DStream DStream Transformations Caching Accumulators, Broadcast Variables and Checkpoints 1 3 4 2.1 2.2 DStream 2 Output DStream 2.3
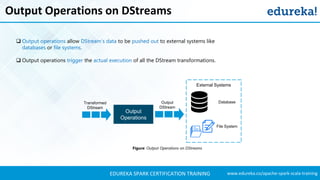
- 39. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Output Operations on DStreams Output operations allow DStream’s data to be pushed out to external systems like databases or file systems. Output operations trigger the actual execution of all the DStream transformations. Output Operations Transformed DStream File System DatabaseOutput DStream Figure: Output Operations on DStreams External Systems
- 40. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Output Operations on DStreams Currently, the following output operations are defined: Output Operations print() saveAsTextFiles (prefix, [suffix]) saveAsObjectFiles (prefix, [suffix]) saveAsHadoopFiles (prefix, [suffix]) foreachRDD(func)
- 41. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Output Operations Example - foreachRDD foreachRDD dstream.foreachRDD is a powerful primitive that allows data to be sent out to external systems. The lazy evaluation achieves the most efficient transfer of data. dstream.foreachRDD { rdd => rdd.foreachPartition { partitionOfRecords => // ConnectionPool is a static, lazily initialized pool of connections val connection = ConnectionPool.getConnection() partitionOfRecords.foreach(record => connection.send(record)) // Return to the pool for future reuse ConnectionPool.returnConnection(connection) } }
- 42. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context DStream Input DStream DStream Transformations Output DStream Accumulators, Broadcast Variables and Checkpoints 1 2 4 2.1 2.32.2 Caching 3
- 43. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Caching/Persistence DStreams allow developers to cache/ persist the stream’s data in memory. This is useful if the data in the DStream will be computed multiple times. This can be done using the persist() method on a DStream. For input streams that receive data over the network (such as Kafka, Flume, Sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance. Figure: Caching Into 2 Nodes
- 44. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Streaming Context DStream Input DStream DStream Transformations Output DStream Caching 1 2 3 2.1 2.32.2 Accumulators, Broadcast Variables and Checkpoints 4
- 45. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Accumulators Accumulators are variables that are only added through an associative and commutative operation. They are used to implement counters or sums. Tracking accumulators in the UI can be useful for understanding the progress of running stages Spark natively supports numeric accumulators. We can create named or unnamed accumulators. Figure: Accumulators In Spark Streaming
- 46. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Broadcast Variables Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost. Figure: Broadcasting A Value To Executors SparkContext ContextCleaner BroadcastManager newBroadcast[T](value, isLocal) registerBroadcastForCleanup broadcast(value) Figure: SparkContext and Broadcasting
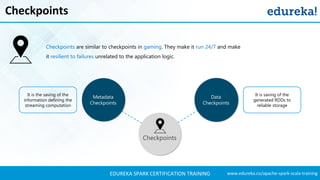
- 47. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Checkpoints Checkpoints are similar to checkpoints in gaming. They make it run 24/7 and make it resilient to failures unrelated to the application logic. It is the saving of the information defining the streaming computation Data Checkpoints Checkpoints Metadata Checkpoints It is saving of the generated RDDs to reliable storage
- 48. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case - Twitter Sentiment Analysis
- 49. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Twitter Sentiment Analysis Trending Topics can be used to create campaigns and attract larger audience. Sentiment Analytics helps in crisis management, service adjusting and target marketing. Sentiment refers to the emotion behind a social media mention online. Sentiment Analysis is categorising the tweets related to particular topic and performing data mining using Sentiment Automation Analytics Tools. We will be performing Twitter Sentiment Analysis as our Use Case for Spark Streaming. Figure: Facebook And Twitter Trending Topics
- 50. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Problem Statement Problem Statement To design a Twitter Sentiment Analysis System where we populate real time sentiments for crisis management, service adjusting and target marketing Figure: Twitter Sentiment Analysis For Adidas Figure: Twitter Sentiment Analysis For Nike Sentiment Analysis is used to: Predict the success of a movie Predict political campaign success Decide whether to invest in a certain company Targeted advertising Review products and services
- 51. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case - Performing Sentiment Analysis
- 52. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Importing Packages //Import the necessary packages into the Spark Program import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.SparkContext._ import org.apache.spark.streaming.twitter._ import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark._ import org.apache.spark.rdd._ import org.apache.spark.rdd.RDD import org.apache.spark.SparkContext._ import org.apache.spark.sql import org.apache.spark.storage.StorageLevel import scala.io.Source import scala.collection.mutable.HashMap import java.io.File
- 53. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Twitter Token Authorization object mapr { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: TwitterPopularTags <consumer key> <consumer secret> " + "<access token> <access token secret> [<filters>]") System.exit(1) } StreamingExamples.setStreamingLogLevels() //Passing our Twitter keys and tokens as arguments for authorization val Array(consumerKey, consumerSecret, accessToken, accessTokenSecret) = args.take(4) val filters = args.takeRight(args.length - 4)
- 54. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – DStream Transformation // Set the system properties so that Twitter4j library used by twitter stream // Use them to generate OAuth credentials System.setProperty("twitter4j.oauth.consumerKey", consumerKey) System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret) System.setProperty("twitter4j.oauth.accessToken", accessToken) System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret) val sparkConf = new SparkConf().setAppName("Sentiments").setMaster("local[2]") val ssc = new StreamingContext(sparkConf, Seconds(5)) val stream = TwitterUtils.createStream(ssc, None, filters) //Input DStream transformation using flatMap val tags = stream.flatMap { status => status.getHashtagEntities.map(_.getText)}
- 55. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Generating Tweet Data //RDD transformation using sortBy and then map function tags.countByValue() .foreachRDD { rdd => val now = org.joda.time.DateTime.now() rdd .sortBy(_._2) .map(x => (x, now)) //Saving our output at ~/twitter/ directory .saveAsTextFile(s"~/twitter/$now") } //DStream transformation using filter and map functions val tweets = stream.filter {t => val tags = t.getText.split(" ").filter(_.startsWith("#")).map(_.toLowerCase) tags.exists { x => true } }
- 56. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Extracting Sentiments val data = tweets.map { status => val sentiment = SentimentAnalysisUtils.detectSentiment(status.getText) val tagss = status.getHashtagEntities.map(_.getText.toLowerCase) (status.getText, sentiment.toString, tagss.toString()) } data.print() //Saving our output at ~/ with filenames starting like twitterss data.saveAsTextFiles("~/twitterss","20000") ssc.start() ssc.awaitTermination() } }
- 57. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case - Results
- 58. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Output In Eclipse Figure: Sentiment Analysis Output In Eclipse IDE Positive Neutral Negative
- 59. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Output Directory Figure: Output folders inside our ‘twitter’ project folder Output folder containing tags and their sentiments Output folder directory Output folder containing Twitter profiles for analysis
- 60. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Output Usernames Figure: Output file containing Twitter username and timestamp
- 61. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Output Tweets and Sentiments Figure: Output file containing tweet and its sentiment Positive Neutral Negative
- 62. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Sentiment For Trump Figure: Performing Sentiment Analysis on Tweets with ‘Trump’ Keyword Positive Neutral Negative ‘Trump’ Keyword
- 63. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Applying Sentiment Analysis As we have seen from our Sentiment Analysis demonstration, we can extract sentiments of particular topics just like we did for ‘Trump’. Hence Sentiment Analytics can be used in crisis management, service adjusting and target marketing by companies around the world. Companies using Spark Streaming for Sentiment Analysis have applied the same approach to achieve the following: 1. Enhancing the customer experience 2. Gaining competitive advantage 3. Gaining Business Intelligence 4. Revitalizing a losing brand 1 32
- 64. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Summary
- 65. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Summary Why Spark Streaming? Caching / PersistenceDStream & Transformations Spark Streaming Overview Use Case - Twitter Sentiment Streaming Context Spark Streaming is used to stream real-time data from various sources like Twitter, Stock Market and Geographical Systems and perform powerful analytics to help businesses.
- 66. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Conclusion
- 67. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Conclusion Congrats! We have hence demonstrated the power of Spark Streaming in Real Time Data Analytics. The hands-on examples will give you the required confidence to work on any future projects you encounter in Apache Spark.
- 68. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Thank You … Questions/Queries/Feedback