SQL? NoSQL? NewSQL?!? What’s a Java developer to do? - JDC2012 Cairo, Egypt
6 likes1,348 views

This document discusses different database options for developers including SQL, NoSQL, and NewSQL databases. It provides an overview of why developers may choose NoSQL databases like MongoDB or Cassandra over traditional SQL databases, as well as when a NewSQL database could be a better option. The document uses a fictional example of a food delivery application to illustrate how different database choices would work for persisting and querying application data.





































![MongoDB: persisting restaurants is easy
Server
Database: Food To Go
Collection: Restaurants
{
"_id" : ObjectId("4bddc2f49d1505567c6220a0")
"name": "Ajanta",
"serviceArea": ["94619", "99999"], BSON =
"openingHours": [
{
binary
"dayOfWeek": 1, JSON
"open": 1130,
"close": 1430 },
{ Sequence
"dayOfWeek": 2,
"open": 1130,
of bytes on
"close": 1430 disk fast
}, …
]
i/o
}
39](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-39-320.jpg)
![Using the MongoDB CLI
> r = {name: 'Ajanta'}
> db.restaurants.save(r)
> r
{ "_id" : ObjectId("4e555dd9646e338dca11710c"), "name" : "Ajanta" }
> r = db.restaurants.findOne({name:"Ajanta"})
{ "_id" : ObjectId("4e555dd9646e338dca11710c"), "name" : "Ajanta" }
> r.type= "Indian”
> db.restaurants.save(r)
> db.restaurants.update({name:"Ajanta"},
{$set: {name:"Ajanta Restaurant"},
$push: { menuItems: {name: "Chicken Vindaloo"}}})
> db.restaurants.find()
{ "_id" : ObjectId("4e555dd9646e338dca11710c"), "menuItems" :
[ { "name" : "Chicken Vindaloo" } ], "name" : "Ajanta Restaurant",
"type" : "Indian" }
> db.restaurants.remove(r.id)
40](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-40-320.jpg)





![Option #1: Use a column per attribute
Column Name = path/expression to access property value
Column Family: RestaurantDetails
openingHours[0].dayOfWeek Monday
name Ajanta serviceArea[0] 94619
1 openingHours[0].open 1130
type indian serviceArea[1] 94707
openingHours[0].close 1430
Egg openingHours[0].dayOfWeek Monday
name serviceArea[0] 94611
shop
2 Break openingHours[0].open 0830
type serviceArea[1] 94619
Fast
openingHours[0].close 1430](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-46-320.jpg)









![Stored procedure – AddRestaurant
@ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”)
public class AddRestaurant extends VoltProcedure {
public final SQLStmt insertRestaurant =
new SQLStmt("INSERT INTO Restaurant VALUES (?,?);");
public final SQLStmt insertServiceArea =
new SQLStmt("INSERT INTO service_area VALUES (?,?);");
public final SQLStmt insertOpeningTimes =
new SQLStmt("INSERT INTO time_range VALUES (?,?,?,?);");
public final SQLStmt insertMenuItem =
new SQLStmt("INSERT INTO menu_item VALUES (?,?,?);");
public long run(int id, String name, String[] serviceArea, long[] daysOfWeek, long[] openingTimes,
long[] closingTimes, String[] names, double[] prices) {
voltQueueSQL(insertRestaurant, id, name);
for (String zipCode : serviceArea)
voltQueueSQL(insertServiceArea, id, zipCode);
for (int i = 0; i < daysOfWeek.length ; i++)
voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]);
for (int i = 0; i < names.length ; i++)
voltQueueSQL(insertMenuItem, id, names[i], prices[i]);
voltExecuteSQL(true);
return 0;
}
}
56](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-56-320.jpg)
![VoltDb repository – add()
@Repository
public class AvailableRestaurantRepositoryVoltdbImpl
implements AvailableRestaurantRepository {
@Autowired
private VoltDbTemplate voltDbTemplate;
@Override
public void add(Restaurant restaurant) {
invokeRestaurantProcedure("AddRestaurant", restaurant);
}
private void invokeRestaurantProcedure(String procedureName, Restaurant restaurant) {
Object[] serviceArea = restaurant.getServiceArea().toArray();
long[][] openingHours = toArray(restaurant.getOpeningHours()); Flatten
Object[][] menuItems = toArray(restaurant.getMenuItems());
Restaurant
voltDbTemplate.update(procedureName, restaurant.getId(), restaurant.getName(),
serviceArea, openingHours[0], openingHours[1],
openingHours[2], menuItems[0], menuItems[1]);
}
57](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-57-320.jpg)


















![VoltDB - attempt #1
@ProcInfo( singlePartition = false)
public class FindAvailableRestaurants extends VoltProcedure { ... }
ERROR 10:12:03,251 [main] COMPILER: Failed to plan for statement
type(findAvailableRestaurants_with_join) select r.* from restaurant
r,time_range tr, service_area sa Where ? = sa.zip_code and r.id
=tr.restaurant_id and r.id = sa.restaurant_id and tr.day_of_week=?
and tr.open_time <= ? and ? <= tr.close_time Error: "Unable to plan
for statement. Likely statement is joining two partitioned tables in a
multi-partition statement. This is not supported at this time."
ERROR 10:12:03,251 [main] COMPILER: Catalog compilation failed.
Bummer!
3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 76](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-76-320.jpg)
![VoltDB - attempt #2
@ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”)
public class AddRestaurant extends VoltProcedure {
public final SQLStmt insertAvailable=
new SQLStmt("INSERT INTO available_time_range VALUES (?,?,?, ?, ?, ?);");
public long run(....) {
...
for (int i = 0; i < daysOfWeek.length ; i++) {
voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]);
for (String zipCode : serviceArea) {
voltQueueSQL(insertAvailable, id, daysOfWeek[i], openingTimes[i],
closingTimes[i], zipCode, name);
}
}
... public final SQLStmt findAvailableRestaurants_denorm = new SQLStmt(
voltExecuteSQL(true); "select restaurant_id, name from available_time_range tr " +
return 0; "where ? = tr.zip_code " +
} "and tr.day_of_week=? " +
} "and tr.open_time <= ? " +
" and ? <= tr.close_time ");
Works but queries are only slightly
faster than MySQL!
3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 77](https://image.slidesharecdn.com/polygotpersistenceforjavadevsegyptjug2012-pptx-120318141916-phpapp01/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-JDC2012-Cairo-Egypt-77-320.jpg)






SQL? NoSQL? NewSQL?!? What’s a Java developer to do? - JDC2012 Cairo, Egypt
- 1. SQL, NoSQL, NewSQL? What's a developer to do? Chris Richardson Author of POJOs in Action Founder of the original CloudFoundry.com @crichardson crichardson@vmware.com
- 2. Overall presentation goal The joy and pain of building Java applications that use NoSQL and NewSQL 2
- 3. About Chris 3
- 4. About Chris 4
- 5. (About Chris) 5
- 6. About Chris() 6
- 7. About Chris 7
- 8. About Chris http://www.theregister.co.uk/2009/08/19/springsource_cloud_foundry/ 8
- 9. About Chris Developer Advocate for CloudFoundry.com Signup at CloudFoundry.com using promo code EgyptJUG 9
- 10. Agenda Why NoSQL? NewSQL? Persisting entities Implementing queries 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 10
- 11. Food to Go Take-out food delivery service “Launched” in 2006 Used a relational database (naturally) 11
- 12. Success Growth challenges Increasing domain model complexity Increasing traffic Increasing data volume Distribute across data centers But relational databases make this difficult…
- 13. Problem: Complex object graphs ?! ID COL1 COL2 COL… Poor performance • Many inserts • Many joins 13
- 14. Problem: Semi-structured data Customer attribute table Customer_Id Name Value 1 Region CA 1 Type Bank … … … • Lack of constraints • Poor query performance, e.g. multiple outer joins 14
- 15. Problem: Semi-structured data Customer table Id Name Street … Other_Attributes 1 Acme Inc 180 Main XML/JSON/Blob 2 Failed Bank 1 Wall Street … … … Can’t be queried 15
- 16. Problem: Schema evolution Id First_Name Last_Name 1 Maria Doe 2 John Smith … … … 9948429292 Ben Grayson Locks? Application downtime? Id First_Name Last_Name DOB 1 Maria Doe 10/14/38 … 16
- 17. Problem: Scaling Moore’s law is your friend BUT Scaling reads: Master/slave But beware of consistency issues Scaling writes Extremely difficult/impossible/expensive Vertical scaling is limited and requires $$ Horizontal scaling is limited/requires $$
- 18. Problem: distribution App App Synchronization DB DB WAN Datacenter 1 Datacenter 2 Many databases don’t support this out of the box 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 18
- 19. Solution: Buy high end technology http://upload.wikimedia.org/wikipedia/commons/e/e5/Rising_Sun_Yacht.JPG
- 20. Solution: Hire more developers Application-level sharding Build your own replication middleware … http://www.trekbikes.com/us/en/bikes/road/race_performance/madone_4_series/madone_4_5
- 21. Solution: Use NoSQL Benefits Higher Limited performance transactions Higher scalability Relaxed Richer data- consistency model Unconstrained data Drawbacks Schema-less 21
- 22. MongoDB Document-oriented database JSON-style documents: Lists, Maps, primitives Schema-less Transaction = update of a single document Rich query language for dynamic queries Tunable writes: speed reliability Highly scalable and available 22
- 23. MongoDB use cases Use cases High volume writes Complex data Semi-structured data Who is using it? Shutterfly, Foursquare Bit.ly Intuit SourceForge, NY Times GILT Groupe, Evite, SugarCRM 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 23
- 24. Apache Cassandra Column-oriented database/Extensible row store Think Row ~= java.util.SortedMap Transaction = update of a row Fast writes = append to a log Tunable reads/writes: consistency latency/availability Extremely scalable Transparent and dynamic clustering Rack and datacenter aware data replication CQL = “SQL”-like DDL and DML 24
- 25. Cassandra use cases Use cases • Big data • Multiple Data Center distributed database • Persistent cache • (Write intensive) Logging • High-availability (writes) Who is using it Digg, Facebook, Twitter, Reddit, Rackspace Cloudkick, Cisco, SimpleGeo, Ooyala, OpenX “The largest production cluster has over 100 TB of data in over 150 machines.“ – Casssandra web site 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 25
- 26. Other NoSQL databases Type Examples Extensible columns/Column- Hbase oriented SimpleDB DynamoDB Graph Neo4j Key-value Redis Membase Document CouchDb http://nosql-database.org/ lists 122+ NoSQL databases 26
- 27. Solution: Use NewSQL Relational databases with SQL and ACID transactions AND New and improved architecture Radically better scalability and performance NewSQL vendors: ScaleDB, NimbusDB, …, VoltDB 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 27
- 28. Stonebraker’s motivations “…Current databases are designed for 1970s hardware …” Stonebraker: http://www.slideshare.net/VoltDB/sql-myths-webinar Significant overhead in “…logging, latching, locking, B-tree, and buffer management operations…” SIGMOD 08: Though the looking glass: http://dl.acm.org/citation.cfm?id=1376713 28
- 29. About VoltDB Open-source In-memory relational database Durability thru replication; snapshots and logging Transparent partitioning Fast and scalable …VoltDB is very scalable; it should scale to 120 partitions, 39 servers, and 1.6 million complex transactions per second at over 300 CPU cores… http://www.mysqlperformanceblog.com/2011/02/28/is-voltdb-really-as-scalable-as-they-claim/ 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 29
- 30. The future is polyglot persistence e.g. Netflix • RDBMS • SimpleDB • Cassandra • Hadoop/Hbase IEEE Software Sept/October 2010 - Debasish Ghosh / Twitter @debasishg 30
- 31. Spring Data is here to help For NoSQL databases http://www.springsource.org/spring-data 31
- 32. Spring Data sub-projects Various sub-projects SQL: Spring Data JPA, JDBC extensions Commons: Polyglot persistence Key-Value: Redis, Riak Document: MongoDB Graph: Neo4j GORM for NoSQL What you get: Wrapper classes analogous to JDBC template Generic Repository Cross-store persistence … 32
- 33. Proceed with caution Don’t commit to a NoSQL DB until you have done a significant POC Encapsulate your data access code so you can switch Hope that one day you won’t need ACID (or complex queries) 33
- 34. Agenda Why NoSQL? NewSQL? Persisting entities Implementing queries 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 34
- 35. Food to Go – Place Order use case 1. Customer enters delivery address and delivery time 2. System displays available restaurants 3. Customer picks restaurant 4. System displays menu 5. Customer selects menu items 6. Customer places order 35
- 36. Food to Go – Domain model (partial) class Restaurant { class TimeRange { long id; long id; String name; int dayOfWeek; Set<String> serviceArea; int openingTime; Set<TimeRange> openingHours; int closingTime; List<MenuItem> menuItems; } } class MenuItem { String name; double price; } 36
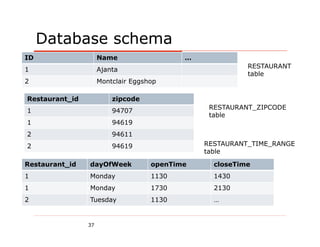
- 37. Database schema ID Name … RESTAURANT 1 Ajanta table 2 Montclair Eggshop Restaurant_id zipcode RESTAURANT_ZIPCODE 1 94707 table 1 94619 2 94611 2 94619 RESTAURANT_TIME_RANGE table Restaurant_id dayOfWeek openTime closeTime 1 Monday 1130 1430 1 Monday 1730 2130 2 Tuesday 1130 … 37
- 38. How to implement the repository? public interface AvailableRestaurantRepository { void add(Restaurant restaurant); Restaurant findDetailsById(int id); … } Restaurant ? TimeRange MenuItem Restaurant aggregate 38
- 39. MongoDB: persisting restaurants is easy Server Database: Food To Go Collection: Restaurants { "_id" : ObjectId("4bddc2f49d1505567c6220a0") "name": "Ajanta", "serviceArea": ["94619", "99999"], BSON = "openingHours": [ { binary "dayOfWeek": 1, JSON "open": 1130, "close": 1430 }, { Sequence "dayOfWeek": 2, "open": 1130, of bytes on "close": 1430 disk fast }, … ] i/o } 39
- 40. Using the MongoDB CLI > r = {name: 'Ajanta'} > db.restaurants.save(r) > r { "_id" : ObjectId("4e555dd9646e338dca11710c"), "name" : "Ajanta" } > r = db.restaurants.findOne({name:"Ajanta"}) { "_id" : ObjectId("4e555dd9646e338dca11710c"), "name" : "Ajanta" } > r.type= "Indian” > db.restaurants.save(r) > db.restaurants.update({name:"Ajanta"}, {$set: {name:"Ajanta Restaurant"}, $push: { menuItems: {name: "Chicken Vindaloo"}}}) > db.restaurants.find() { "_id" : ObjectId("4e555dd9646e338dca11710c"), "menuItems" : [ { "name" : "Chicken Vindaloo" } ], "name" : "Ajanta Restaurant", "type" : "Indian" } > db.restaurants.remove(r.id) 40
- 41. Spring Data for Mongo code @Repository public class AvailableRestaurantRepositoryMongoDbImpl implements AvailableRestaurantRepository { public static String AVAILABLE_RESTAURANTS_COLLECTION = "availableRestaurants"; @Autowired private MongoTemplate mongoTemplate; @Override public void add(Restaurant restaurant) { mongoTemplate.insert(restaurant, AVAILABLE_RESTAURANTS_COLLECTION); } @Override public Restaurant findDetailsById(int id) { return mongoTemplate.findOne(new Query(where("_id").is(id)), Restaurant.class, AVAILABLE_RESTAURANTS_COLLECTION); } } 41
- 42. Spring Configuration @Configuration public class MongoConfig extends AbstractDatabaseConfig { @Value("#{mongoDbProperties.databaseName}") private String mongoDbDatabase; @Bean public Mongo mongo() throws UnknownHostException, MongoException { return new Mongo(databaseHostName); } @Bean public MongoTemplate mongoTemplate(Mongo mongo) throws Exception { MongoTemplate mongoTemplate = new MongoTemplate(mongo, mongoDbDatabase); mongoTemplate.setWriteConcern(WriteConcern.SAFE); mongoTemplate.setWriteResultChecking(WriteResultChecking.EXCEPTION); return mongoTemplate; } } 42
- 43. Cassandra data model Column Column Row Value Name Timestamp Key Keyspace Column Family K1 N1 V1 TS1 N2 V2 TS2 N3 V3 TS3 K2 N1 V1 TS1 N2 V2 TS2 N3 V3 TS3 Column name/value: number, string, Boolean, timestamp, and composite 43
- 44. Cassandra– inserting/updating data Column Family K1 N1 V1 TS1 N2 V2 TS2 N3 V3 TS3 … Idempotent= transaction CF.insert(key=K1, (N4, V4, TS4), …) Column Family K1 N1 V1 TS1 N2 V2 TS2 N3 V3 TS3 N4 V4 TS4 … 44
- 45. Cassandra– retrieving data Column Family K1 N1 V1 TS1 N2 V2 TS2 N3 V3 TS3 N4 V4 TS4 … CF.slice(key=K1, startColumn=N2, endColumn=N4) K1 N2 V2 TS2 N3 V3 TS3 N4 V4 TS4 Cassandra has secondary indexes but they aren’t helpful for these use cases 45
- 46. Option #1: Use a column per attribute Column Name = path/expression to access property value Column Family: RestaurantDetails openingHours[0].dayOfWeek Monday name Ajanta serviceArea[0] 94619 1 openingHours[0].open 1130 type indian serviceArea[1] 94707 openingHours[0].close 1430 Egg openingHours[0].dayOfWeek Monday name serviceArea[0] 94611 shop 2 Break openingHours[0].open 0830 type serviceArea[1] 94619 Fast openingHours[0].close 1430
- 47. Option #2: Use a single column Column value = serialized object graph, e.g. JSON Column Family: RestaurantDetails 2 attributes: { name: “Montclair Eggshop”, … } 1 attributes { name: “Ajanta”, …} 2 attributes { name: “Eggshop”, …} ✔ 47
- 48. Cassandra code public class AvailableRestaurantRepositoryCassandraKeyImpl implements AvailableRestaurantRepository { @Autowired Home grown private final CassandraTemplate cassandraTemplate; wrapper class public void add(Restaurant restaurant) { cassandraTemplate.insertEntity(keyspace, RESTAURANT_DETAILS_CF, restaurant); } public Restaurant findDetailsById(int id) { String key = Integer.toString(id); return cassandraTemplate.findEntity(Restaurant.class, keyspace, key, RESTAURANT_DETAILS_CF); … } … http://en.wikipedia.org/wiki/Hector 48
- 49. Using VoltDB Use the original schema Standard SQL statements BUT YOU MUST Write stored procedures and invoke them using proprietary interface Partition your data 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 49
- 50. About VoltDB stored procedures Key part of VoltDB Replication = executing stored procedure on replica Logging = log stored procedure invocation Stored procedure invocation = transaction 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 50
- 51. About partitioning Partition column RESTAURANT table ID Name … 1 Ajanta 2 Eggshop … 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 51
- 52. Example cluster Partition 1a Partition 2a Partition 3a ID Name … ID Name … ID Name … 1 Ajanta 2 Eggshop … .. … … … Partition 3b Partition 1b Partition 2b ID Name … ID Name … ID Name … … .. 1 Ajanta 2 Eggshop … … … VoltDB Server 1 VoltDB Server 2 VoltDB Server 3 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 52
- 53. Single partition procedure: FAST SELECT * FROM RESTAURANT WHERE ID = 1 High-performance lock free code ID Name … ID Name … ID Name … 1 Ajanta 1 Eggshop … .. … … … … … … VoltDB Server 1 VoltDB Server 2 VoltDB Server 3 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 53
- 54. Multi-partition procedure: SLOWER SELECT * FROM RESTAURANT WHERE NAME = ‘Ajanta’ Communication/Coordination overhead ID Name … ID Name … ID Name … 1 Ajanta 1 Eggshop … .. … … … … … … VoltDB Server 1 VoltDB Server 2 VoltDB Server 3 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 54
- 55. Chosen partitioning scheme <partitions> <partition table="restaurant" column="id"/> <partition table="service_area" column="restaurant_id"/> <partition table="menu_item" column="restaurant_id"/> <partition table="time_range" column="restaurant_id"/> <partition table="available_time_range" column="restaurant_id"/> </partitions> Performance is excellent: much faster than MySQL 55
- 56. Stored procedure – AddRestaurant @ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”) public class AddRestaurant extends VoltProcedure { public final SQLStmt insertRestaurant = new SQLStmt("INSERT INTO Restaurant VALUES (?,?);"); public final SQLStmt insertServiceArea = new SQLStmt("INSERT INTO service_area VALUES (?,?);"); public final SQLStmt insertOpeningTimes = new SQLStmt("INSERT INTO time_range VALUES (?,?,?,?);"); public final SQLStmt insertMenuItem = new SQLStmt("INSERT INTO menu_item VALUES (?,?,?);"); public long run(int id, String name, String[] serviceArea, long[] daysOfWeek, long[] openingTimes, long[] closingTimes, String[] names, double[] prices) { voltQueueSQL(insertRestaurant, id, name); for (String zipCode : serviceArea) voltQueueSQL(insertServiceArea, id, zipCode); for (int i = 0; i < daysOfWeek.length ; i++) voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]); for (int i = 0; i < names.length ; i++) voltQueueSQL(insertMenuItem, id, names[i], prices[i]); voltExecuteSQL(true); return 0; } } 56
- 57. VoltDb repository – add() @Repository public class AvailableRestaurantRepositoryVoltdbImpl implements AvailableRestaurantRepository { @Autowired private VoltDbTemplate voltDbTemplate; @Override public void add(Restaurant restaurant) { invokeRestaurantProcedure("AddRestaurant", restaurant); } private void invokeRestaurantProcedure(String procedureName, Restaurant restaurant) { Object[] serviceArea = restaurant.getServiceArea().toArray(); long[][] openingHours = toArray(restaurant.getOpeningHours()); Flatten Object[][] menuItems = toArray(restaurant.getMenuItems()); Restaurant voltDbTemplate.update(procedureName, restaurant.getId(), restaurant.getName(), serviceArea, openingHours[0], openingHours[1], openingHours[2], menuItems[0], menuItems[1]); } 57
- 58. VoltDbTemplate wrapper class public class VoltDbTemplate { private Client client; VoltDB client API public VoltDbTemplate(Client client) { this.client = client; } public void update(String procedureName, Object... params) { try { ClientResponse x = client.callProcedure(procedureName, params); … } catch (Exception e) { throw new RuntimeException(e); } } 58
- 59. VoltDb server configuration <?xml version="1.0"?> <deployment> <project> <cluster hostcount="1" <info> <name>Food To Go</name> sitesperhost="5" kfactor="0" /> ... </info> </deployment> <database> <schemas> <schema path='schema.sql' /> </schemas> <partitions> <partition table="restaurant" column="id"/> ... </partitions> <procedures> <procedure class='net.chrisrichardson.foodToGo.newsql.voltdb.procs.AddRestaurant' /> ... </procedures> </database> </project> voltcompiler target/classes src/main/resources/sql/voltdb-project.xml foodtogo.jar bin/voltdb leader localhost catalog foodtogo.jar deployment deployment.xml 59
- 60. Performance Benchmarking is still work in progress but so far http://www.youtube.com/watch? v=b2F-DItXtZs Mongo Cassandra VoltDB Insert for PK Awesome Fast* Awesome Find by PK Awesome Fast Incredible * Cassandra can be clustered for improved write performance 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 60
- 61. Agenda Why NoSQL? NewSQL? Persisting entities Implementing queries 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 61
- 62. Finding available restaurants Available restaurants = Serve the zip code of the delivery address AND Are open at the delivery time public interface AvailableRestaurantRepository { List<AvailableRestaurant> findAvailableRestaurants(Address deliveryAddress, Date deliveryTime); … } 62
- 63. Finding available restaurants on Monday, 6.15pm for 94619 zip select r.* Straightforward from restaurant r three-way join inner join restaurant_time_range tr on r.id =tr.restaurant_id inner join restaurant_zipcode sa on r.id = sa.restaurant_id Where ’94619’ = sa.zip_code and tr.day_of_week=’monday’ and tr.openingtime <= 1815 and 1815 <= tr.closingtime 63
- 64. MongoDB = easy to query { serviceArea:"94619", Find a openingHours: { $elemMatch : { restaurant "dayOfWeek" : "Monday", "open": {$lte: 1815}, that serves } "close": {$gte: 1815} the 94619 zip } } code and is open at DBCursor cursor = collection.find(qbeObject); while (cursor.hasNext()) { 6.15pm on a DBObject o = cursor.next(); … Monday } db.availableRestaurants.ensureIndex({serviceArea: 1}) 64
- 65. MongoTemplate-based code @Repository public class AvailableRestaurantRepositoryMongoDbImpl implements AvailableRestaurantRepository { @Autowired private final MongoTemplate mongoTemplate; @Override public List<AvailableRestaurant> findAvailableRestaurants(Address deliveryAddress, Date deliveryTime) { int timeOfDay = DateTimeUtil.timeOfDay(deliveryTime); int dayOfWeek = DateTimeUtil.dayOfWeek(deliveryTime); Query query = new Query(where("serviceArea").is(deliveryAddress.getZip()) .and("openingHours”).elemMatch(where("dayOfWeek").is(dayOfWeek) .and("openingTime").lte(timeOfDay) .and("closingTime").gte(timeOfDay))); return mongoTemplate.find(AVAILABLE_RESTAURANTS_COLLECTION, query, AvailableRestaurant.class); } mongoTemplate.ensureIndex(“availableRestaurants”, new Index().on("serviceArea", Order.ASCENDING)); 65
- 66. BUT how to do this with Cassandra??! How can Cassandra support a query that has ? A 3-way join Multiple = > and < We need to implement an index Queries instead of data model drives NoSQL database design 66
- 67. ... And use a slice operation columnFamily.slice(key=keyVal, startColumn=startVal, endColumn=endVal) = select * from columnFamily where key = keyVal and col >= startVal and col <= endVal 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 67
- 68. Simplification #1: Denormalization Restaurant_id Day_of_week Open_time Close_time Zip_code 1 Monday 1130 1430 94707 1 Monday 1130 1430 94619 1 Monday 1730 2130 94707 1 Monday 1730 2130 94619 2 Monday 0700 1430 94619 … SELECT restaurant_id FROM time_range_zip_code WHERE day_of_week = ‘Monday’ Simpler query: AND zip_code = 94619 No joins Two = and two < AND 1815 < close_time AND open_time < 1815 68
- 69. Simplification #2: Application filtering SELECT restaurant_id, open_time FROM time_range_zip_code WHERE day_of_week = ‘Monday’ Even simpler query AND zip_code = 94619 • No joins AND 1815 < close_time • Two = and one < AND open_time < 1815 69
- 70. Simplification #3: Eliminate multiple =’s with concatenation Restaurant_id Zip_dow Open_time Close_time 1 94707:Monday 1130 1430 1 94619:Monday 1130 1430 1 94707:Monday 1730 2130 1 94619:Monday 1730 2130 2 94619:Monday 0700 1430 … SELECT restaurant_id, open_time FROM time_range_zip_code WHERE zip_code_day_of_week = ‘94619:Monday’ AND 1815 < close_time key range 70
- 71. Column family with composite column names as an index Restaurant_id Zip_dow Open_time Close_time 1 94707:Monday 1130 1430 1 94619:Monday 1130 1430 1 94707:Monday 1730 2130 1 94619:Monday 1730 2130 2 94619:Monday 0700 1430 … Column Family: AvailableRestaurants JSON FOR JSON FOR (1430,0700,2) (2130,1730,1) 94619:Monday EGG AJANTA JSON FOR (1430,1130,1) AJANTA
- 72. Querying with a slice Column Family: AvailableRestaurants JSON FOR JSON FOR (1430,0700,2) (2130,1730,1) EGG AJANTA 94619:Monday JSON FOR (1430,1130,1) AJANTA slice(key= 94619:Monday, sliceStart = (1815, *, *), sliceEnd = (2359, *, *)) JSON FOR (2130,1730,1) 94619:Monday AJANTA 18:15 is after 17:30 {Ajanta} 72
- 73. Needs a few pages of code private void insertAvailability(Restaurant restaurant) { for (String zipCode : (Set<String>) restaurant.getServiceArea()) { @Override for (TimeRange tr : (Set<TimeRange>) restaurant.getOpeningHours()) { public List<AvailableRestaurant> findAvailableRestaurants(Address deliveryAddress, Date deliveryTime) { String dayOfWeek = format2(tr.getDayOfWeek()); int dayOfWeek = DateTimeUtil.dayOfWeek(deliveryTime); String openingTime = format4(tr.getOpeningTime()); int timeOfDay = DateTimeUtil.timeOfDay(deliveryTime); String closingTime = format4(tr.getClosingTime()); String zipCode = deliveryAddress.getZip(); String key = formatKey(zipCode, format2(dayOfWeek)); String restaurantId = format8(restaurant.getId()); HSlicePredicate<Composite> predicate = new HSlicePredicate<Composite>(new CompositeSerializer()); String key = formatKey(zipCode, dayOfWeek); Composite start = new Composite(); Composite finish = new Composite(); String columnValue = toJson(restaurant); start.addComponent(0, format4(timeOfDay), ComponentEquality.GREATER_THAN_EQUAL); finish.addComponent(0, format4(2359), ComponentEquality.GREATER_THAN_EQUAL); Composite columnName = new Composite(); predicate.setRange(start, finish, false, 100); columnName.add(0, closingTime); final List<AvailableRestaurantIndexEntry> closingAfter = new ArrayList<AvailableRestaurantIndexEntry>(); columnName.add(1, openingTime); columnName.add(2, restaurantId); ColumnFamilyRowMapper<String, Composite, Object> mapper = new ColumnFamilyRowMapper<String, Composite, Object>() { @Override ColumnFamilyUpdater<String, Composite> updater public Object mapRow(ColumnFamilyResult<String, Composite> results) { = compositeCloseTemplate.createUpdater(key); for (Composite columnName : results.getColumnNames()) { String openTime = columnName.get(1, new StringSerializer()); String restaurantId = columnName.get(2, new StringSerializer()); updater.setString(columnName, columnValue); closingAfter.add(new AvailableRestaurantIndexEntry(openTime, restaurantId, results.getString(columnName))); } return null; } }; compositeCloseTemplate.update(updater); } compositeCloseTemplate.queryColumns(key, predicate, mapper); } List<AvailableRestaurant> result = new LinkedList<AvailableRestaurant>(); } for (AvailableRestaurantIndexEntry trIdAndAvailableRestaurant : closingAfter) { if (trIdAndAvailableRestaurant.isOpenBefore(timeOfDay)) result.add(trIdAndAvailableRestaurant.getAvailableRestaurant()); } return result; } 73
- 74. What did I just do to query the data? Wrote code to maintain an index Reduced performance due to extra writes 74
- 75. Mongo vs. Cassandra DC1 DC2 Shard A Master Shard B Master MongoDB Remote DC1 Client DC2 Client DC1 DC2 Async Cassandra Or Cassandra Cassandra Sync DC1 Client DC2 Client 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 75
- 76. VoltDB - attempt #1 @ProcInfo( singlePartition = false) public class FindAvailableRestaurants extends VoltProcedure { ... } ERROR 10:12:03,251 [main] COMPILER: Failed to plan for statement type(findAvailableRestaurants_with_join) select r.* from restaurant r,time_range tr, service_area sa Where ? = sa.zip_code and r.id =tr.restaurant_id and r.id = sa.restaurant_id and tr.day_of_week=? and tr.open_time <= ? and ? <= tr.close_time Error: "Unable to plan for statement. Likely statement is joining two partitioned tables in a multi-partition statement. This is not supported at this time." ERROR 10:12:03,251 [main] COMPILER: Catalog compilation failed. Bummer! 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 76
- 77. VoltDB - attempt #2 @ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”) public class AddRestaurant extends VoltProcedure { public final SQLStmt insertAvailable= new SQLStmt("INSERT INTO available_time_range VALUES (?,?,?, ?, ?, ?);"); public long run(....) { ... for (int i = 0; i < daysOfWeek.length ; i++) { voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]); for (String zipCode : serviceArea) { voltQueueSQL(insertAvailable, id, daysOfWeek[i], openingTimes[i], closingTimes[i], zipCode, name); } } ... public final SQLStmt findAvailableRestaurants_denorm = new SQLStmt( voltExecuteSQL(true); "select restaurant_id, name from available_time_range tr " + return 0; "where ? = tr.zip_code " + } "and tr.day_of_week=? " + } "and tr.open_time <= ? " + " and ? <= tr.close_time "); Works but queries are only slightly faster than MySQL! 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 77
- 78. VoltDB - attempt #3 <partitions> ... <partition table="available_time_range" column="zip_code"/> </partitions> @ProcInfo( singlePartition = false, ...) public class AddRestaurant extends VoltProcedure { ... } @ProcInfo( singlePartition = true, partitionInfo = "available_time_range.zip_code: 0") public class FindAvailableRestaurants extends VoltProcedure { ... } Queries are really fast but inserts are not Partitioning scheme – optimal for some use cases but not others 78
- 79. Performance Benchmarking is still work in progress but so far Mongo Cassandra VoltDB Insert for find available Awesome Ok* Ok Find available Ok Ok Awesome restaurants * Cassandra can be clustered for improved write performance 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 79
- 80. Is NewSQL/NoSQL a good fit for Food To Go? Cassandra Mongo VoltDB Representing Easy Very easy Easy restaurants PK-lookup Easy Easy Easy Find available Lots of code Easy Tricky restaurants query Use as SOR Yes – if Yes – for single Yes distribution datacenter required 80
- 81. Summary… Relational databases are great BUT there are limitations Each NoSQL database solves some problems BUT Limited transactions: NoSQL = NoACID One day needing ACID major rewrite Query-driven, denormalized database design … NewSQL databases such as VoltDB provides SQL, ACID transactions and incredible performance BUT Not all operations are fast Non-JDBC API 81
- 82. … Summary Very carefully pick the NewSQL/ NoSQL DB for your application Consider a polyglot persistence architecture Encapsulate your data access code so you can switch Startups = avoid NewSQL/NoSQL for shorter time to market? 3/18/12 Copyright (c) 2011 Chris Richardson. All rights reserved. Slide 82
- 83. Thank you! Signup at CloudFoundry.com using promo code EgyptJUG My contact info: chris.richardson@springsource.com @crichardson 83