

![Which face is real?
[出典] http://www.whichfaceisreal.com/
3](https://image.slidesharecdn.com/withoutprofile-190630022826/85/StyleGAN-CVPR2019-DeNA-3-320.jpg)






























StyleGAN解説 CVPR2019読み会@DeNA
- 1. A Style-Based Generator Architecture for Generative Adversarial Networks 2019/06/29 1 CVPR2019 読み会@DeNA
- 2. 読む論文 “A Style-Based Generator Architecture for Generative Adversarial Networks” • CVPR 2019 Honorable Mention • 著者はNVIDIAの研究グループ • 内容 • スタイル変換の手法を取り入れることにより綺麗な画像を生成 • 1024x1024のサイズで実物と見紛うほどの顔画像を生成 2
- 3. Which face is real? [出典] http://www.whichfaceisreal.com/ 3
- 5. History of GAN Ian Goodfellow in ICLR 2019. 5
- 6. 論文概要 • スタイル変換の技術を応用した, 新しいGeneratorの構造を提案 • 潜在表現ベクトルzをAdaINのパラメーターとして導入 • これにより以下が実現 教師なしでの属性の分離 • 例) poseとidentity 教師なしでの確率的なばらつきのモデリング • 例) そばかす, 髪の毛の流れ方 • 画質等の評価指標で最高性能を達成 • 新しい評価指標・データセットの提案もこの論文の貢献 6
- 8. Style based generatorの構造 8 Mapping network 潜在表現zをMLPにより ベクトルwにマッピング wで貼られる空間Wを intermediate feature space (中間的な特徴空 間)としている Synthesis network 従来のgeneratorと同様 に, CNNで特徴マップを upsampleしていくこと により画像を生成
- 9. Style based generatorの構造 9 wは行列Aをかけたの ちに, 各レイヤーの特 徴マップに適用される スタイル変換の論文で 提案されたAdaINをこ こで使っている
- 10. AdaIN (Adaptive Instance Normalization) • スタイル変換の論文 (Huang et al. 2017) で提案された正規化手法 ※スタイル変換とは, ある画像に他の画像のスタイルを適用するタスク 10 X. Huang et al. “Arbitrary Style Transfer in Real- time with Adaptive Instance Normalization”, 2017.
- 11. AdaIN (Adaptive Instance Normalization) • スタイル変換の論文で提案された正規化手法 • 変換元の画像の特徴マップの平均・分散をスタイル画像の特徴マップの平均・分散 に合わせる操作 • 実は特徴マップの平均・分散を合わせることがスタイル変換の本質 11 𝑥 : 特徴マップ 𝑦 : スタイル画像の特徴マップ 𝜇, 𝜎 : 平均・分散 特徴マップを正規化 スタイル画像の平均・分散を適用
- 12. AdaIN (Adaptive Instance Normalization) • スタイル変換の論文で提案された正規化手法 • 変換元の画像の特徴マップの平均・分散をスタイル画像の特徴マップの平均・分散 に合わせる操作 • 実は特徴マップの平均・分散を合わせることがスタイル変換の本質 12 𝑥 : 特徴マップ 𝑦 : スタイル画像の特徴マップ 𝜇, 𝜎 : 平均・分散 特徴マップを正規化 スタイル画像の平均・分散を適用
- 13. AdaIN (Adaptive Instance Normalization) • StyleGANでは, 以下の式の𝑦𝑠,𝑖と𝑦 𝑏,𝑖をMapping Networkに よりzから生成している • 論文ではこれを「スタイル」と呼んでいる • ちなみに, Self-modulationというほぼ同じ手法がある 13 T. Cheng et al. “On Self Modulation for Generative Adversarial Networks”, ICLR, 2019.
- 14. Style based generatorの構造 14 Synthesis networkの入 力は潜在表現zでなく固 定されたテンソル (これにより性能が結構 上がる)
- 16. ノイズの役割 • ノイズは, 生成画像の確率的な 要素を司る • 例) 髪の毛の流れ方, 肌のしわ 16
- 17. ノイズの役割 • ノイズは, 生成画像の確率的な要素を司る • 例) 髪の毛の流れ方, 肌のしわ 17
- 18. mixing regularization • AdaINのパラメータ𝑤1, 𝑤2を𝑧1, 𝑧2から生成し, こ れらをランダムで学習中に入れ替える • 連続する層のスタイルが相関するのを防ぐ狙い • これによりFIDスコアが少し上がった 18 例) 異なるzか ら生成したパラ メータを導入
- 19. 提案手法まとめ • Style based generatorでは以下の手法を提案 • 潜在ベクトルを変換した後AdaINの層に導入 • Synthesis networkの入力を固定テンソルに変更 • 各層にノイズを付与 • Style mixing 19
- 20. 実験 : 生成画像の質 • CELEBA-HQとFFHQデータセットで画質 (FID score) を評価 • FFHQは新しいデータセット 提案手法によりスコアが向上 20
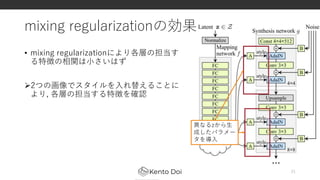
- 21. mixing regularizationの効果 • mixing regularizationにより各層の担当す る特徴の相関は小さいはず 2つの画像でスタイルを入れ替えることに より, 各層の担当する特徴を確認 21 異なるzから生 成したパラメー タを導入
- 22. mixing regularizationの効果 • source(上段)のstyleをdestination(左列)と mix • 上: coarse style (42 – 82) • 姿勢, 髪型, 顔の形, メガネの有無など • 中: middle style (162 – 322) • 髪型, 目など • 下: fine style (642 - 10242) • 髪, 肌の色 それぞれのスタイルは異なる特性を担当 22 Styleをmix
- 23. 特徴量のdisentanglementについて • disentanglementとは, 特徴を分解すること • ここでは, 潜在空間の1つの方向が画像の1つの特徴に対応していることと定義 • すると, 潜在空間が図の左のような形になるべき場合がある • 例えば「性別」「髭の長さ」という2軸でみると女性で髭の長いサンプルは少ない • 従来のGANでは潜在空間がガウス分布なので特徴を2軸に分離できない • StyleGANでは𝑧から写像した𝑤により潜在空間が作られるので実現可能 23
- 24. Perceptual path length • 先行研究(*)によると潜在空間をinterpolateして画像を生成した時, 途中で 不自然に画像が変化してしまう問題がある • これは潜在空間が「もつれている」ことを示す • 潜在空間の「曲がり具合」が少ないほど, 画像がスムーズに変化する Perceptual path lengthという指標により評価 24 * S. Laine. Feature-based metrics for exploring the latent space of generative models. ICLR workshop poster, 2018. 滑らかに変化してほしい S. Laine. Feature-based metrics for exploring the latent space of generative models. ICLR workshop poster, 2018.
- 25. Perceptual path length • お気持ち • 潜在表現zを2点の間で線形補間すると, 生成画像の特徴も線形に変化するはず • ここでは, 生成画像の特徴の変化を知覚損失(*)により測定 • つまり, 潜在空間が「曲がって」いないほど知覚損失の差は小さくなる 25 潜在空間 生成画像から抽出した特徴の空間 Generatorによる写像 𝑧1 𝑧2 𝐹(𝐺 𝑧1 ) 𝐹(𝐺 𝑧2) 潜在空間が「曲がって」 いる場合=距離大 潜在空間が「曲がって」 いない場合=距離小 線形補間 * J. Johnson et al. “Perceptual Losses for Real-Time Style Transfer and Super-Resolution”, ICCV, 2017.
- 26. Perceptual path length • perceptual path lengthは小さい程よい • 提案手法は既存手法に加えてpath lengthが短い 特徴空間が「曲がってない」 26
- 27. Linear separability 1. 画像の二値分類できる特徴(例: 性別)を分類する補助ネットワーク (discriminatorと同様の構造)を学習 2. 20万枚画像を生成 3. 分類器のスコアが高い10万枚について, 潜在表現とラベルのペアを作成 4. 潜在表現とラベルのペアの分類をSVMで学習 5. エントロピーH(Y|X)を計算 • (X: SVMの推定ラベル, Y: 補助ネットワークがつけたラベル) • 上のスコアを40個のアトリビュートで計算し平均 • このスコアが低いほど潜在表現が分離しやすい→良い 27
- 28. The FFHQ datase • 1024 x 1024の高画質画像を7万枚収集 • CELEBA-HQよりも年齢, 人種, 背景, メガネ, 帽子など外見が多様な画像を集めた • こちらのURLから使用可能 (http://stylegan.xyz/code) 28
- 29. まとめ • スタイル変換の技術を応用した新しいgeneratorの構造を提案 • 生成画像の質の指標で既存手法を上回った • 提案手法には以下のような特性が • 高レベルの特徴を分離して学習 • 確率的なばらつきを学習 • 潜在空間の線型性 • 潜在空間の「曲がり具合」や「どれだけ分離できるか」という性能 を測る指標を提案 29
- 30. おまけ : StyleGANを使っている論文 • 例) HoloGAN • StyleGANの構造にさらに3次元的な変形を行うレイヤーを追加 生成される画像の姿勢を制御できる 30 T. N. Phuoc et al. “HoloGAN: Unsupervised learning of 3D representations from natural images”, arXiv, 2019.
- 31. おまけ : StyleGAN in twitter 31
- 32. おまけ : StyleGAN in twitter 32
- 33. おまけ : StyleGAN in twitter 33
- 34. 参考文献 1. T. Karras et al. “A Style-Based Generator Architecture for Generative Adversarial Network”, 2018. 2. T. Karras et al. “Progressive Growing of GANs for Improved Quality, Stability, and Variation”, ICLR, 2018. 3. X. Huang et al. “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization”, 2017. 4. T. Cheng et al. “On Self Modulation for Generative Adversarial Networks”, ICLR, 2019. 5. S. Laine. “Feature-based metrics for exploring the latent space of generative models”, ICLR workshop poster, 2018. 6. J. Johnson et al. “Perceptual Losses for Real-Time Style Transfer and Super- Resolution”, ICCV, 2017. 7. T. N. Phuoc et al. “HoloGAN: Unsupervised learning of 3D representations from natural images”, arXiv, 2019. 34