Task Scheduling Algorithm for Multicore Processor Systems with Turbo Boost and Hyper-Threading
Download as PPTX, PDF1 like1,514 views

The document discusses a task scheduling algorithm for multicore processor systems that optimally utilizes turbo boost and hyper-threading technologies to minimize total computation time. It outlines the current issues with existing scheduling algorithms that do not account for dynamic frequency scaling and network contention. The proposed method improves execution time by up to 35% while maintaining an average estimation error of 4% for task execution times.


![Related Works(1/2)
• Task scheduling algorithm taking account of
network contention [1]
• Formulates communication delay between processors
– Reduces network contention
– No multicore processors
– No scaling of operating frequency
[1] O. Sinnen and LA. Sousa: ``Communication Contention in Task Scheduling,"
IEEE Transactions on Parallel and Distributed Systems, Vol. 16, No. 6, pp. 503-515,
2005.
4](https://image.slidesharecdn.com/pdpta-turboboost-140827013934-phpapp01/85/Task-Scheduling-Algorithm-for-Multicore-Processor-Systems-with-Turbo-Boost-and-Hyper-Threading-4-320.jpg)
![Related Works(2/2)
• Task scheduling algorithm taking account of
multicore processor and fail-stop model [2]
– Considers both network contention and failure of
multiple processors on a single die
– No consideration for change of operating
frequency
[2] S. Gotoda, N. Shibata and M. Ito : ``Task scheduling algorithm for multicore
processor system for minimizing recovery time in case of single node fault,"
International Symposium on Cluster, Cloud, and Grid Computing (CCGrid), pp. 260-
267, 2012.
5](https://image.slidesharecdn.com/pdpta-turboboost-140827013934-phpapp01/85/Task-Scheduling-Algorithm-for-Multicore-Processor-Systems-with-Turbo-Boost-and-Hyper-Threading-5-320.jpg)





![Modelling Effective Frequency
State of cores Frequency
[ c , i ] , [ i , i ] , [ i , i ] , [ i , i ] To be measured
[ c , i ] , [ c , i ] , [ i , i ] , [ i , i ] To be measured
Operating frequency when Turbo Boost is enabled
(The processor has 4 cores 8 hardware threads)
i:idle, c:computation heavy
m:memory access heavy, n:In between c and m
• We want to predict the operating frequency from
the number of working cores
– We changed the number of working cores
– We measured the operating frequency
Physical core Hardware thread
13](https://image.slidesharecdn.com/pdpta-turboboost-140827013934-phpapp01/85/Task-Scheduling-Algorithm-for-Multicore-Processor-Systems-with-Turbo-Boost-and-Hyper-Threading-13-320.jpg)
![Results of Measurement
State Freq Ratio Effective freq.
[ c , c ] 3.1GHz 0.84 2.6GHz
[ m , m ] 3.1GHz 0.76 2.3GHz
[ n , n ] 3.1GHz 0.79 2.5GHz
Only Turbo Boost is used
Only Hyper Threading is used
State of cores
i : idle
c : computation heavy
m : memory-access
heavy
n : In between c and m
When Turbo Boost is used
Effective freq. depends on
number of working cores
When Hyper-Threading is
used
Effective freq. depends on
properties of programs
State of cores Effective freq.
[ c , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz
[ c , i ] [ c , i ] [ i , i ] [ i , i ] 3.5GHz
[ c , i ] [ c , i ] [ c , i ] [ i , i ] 3.3GHz
[ c , i ] [ c , i ] [ c , i ] [ c , i ] 3.1GHz
[ m , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz
[ m , i ] [ m , i ] [ m , i ] [ m , i ] 3.1GHz
[ n , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz
[ n , i ] [ n , i ] [ n , i ] [ n , i ] 3.1GHz
14](https://image.slidesharecdn.com/pdpta-turboboost-140827013934-phpapp01/85/Task-Scheduling-Algorithm-for-Multicore-Processor-Systems-with-Turbo-Boost-and-Hyper-Threading-14-320.jpg)

















![Yosuke Wakisaka, Naoki Shibata, Keiichi
Yasumoto, Minoru Ito, and Junji Kitamichi : Task
Scheduling Algorithm for Multicore Processor
Systems with Turbo Boost and Hyper-
Threading, In Proc. of The 2014 International
Conference on Parallel and Distributed Processing
Techniques and Applications(PDPTA'14), pp. 229-
235, 2014-07-21 [ PDF ]
34](https://image.slidesharecdn.com/pdpta-turboboost-140827013934-phpapp01/85/Task-Scheduling-Algorithm-for-Multicore-Processor-Systems-with-Turbo-Boost-and-Hyper-Threading-34-320.jpg)
Task Scheduling Algorithm for Multicore Processor Systems with Turbo Boost and Hyper-Threading
- 1. Yosuke Wakisaka Naoki Shibata Junji Kitamichi‡ Keiichi Yasumoto Minoru Ito Nara Institute of Science and Technology ‡University of Aizu Task Scheduling Algorithm for Multicore Processor Systems with Turbo Boost and Hyper-Threading 1
- 2. • Multicore processors – Widely used in distributed computing environments • Data centers, supercomputers, ordinary PCs, mobile devices – Dynamic control of the CPU’s operating frequency • Turbo Boost(Intel), Turbo Core(AMD), Dynamic frequency scaling(nVidia GPUs) – Efficient computation while saving power • Hyper Threading(Intel), Simultaneous multithreading(IBM POWER) Background 2
- 3. Objective of Research • Efficient task scheduling – Utilizing the latest technologies – Minimize total computation time • No known scheduling algorithms takes account of these technologies Dynamic scaling of operating speed by Turbo Boost and Hyper-Threading Delay of communication by network contention 3
- 4. Related Works(1/2) • Task scheduling algorithm taking account of network contention [1] • Formulates communication delay between processors – Reduces network contention – No multicore processors – No scaling of operating frequency [1] O. Sinnen and LA. Sousa: ``Communication Contention in Task Scheduling," IEEE Transactions on Parallel and Distributed Systems, Vol. 16, No. 6, pp. 503-515, 2005. 4
- 5. Related Works(2/2) • Task scheduling algorithm taking account of multicore processor and fail-stop model [2] – Considers both network contention and failure of multiple processors on a single die – No consideration for change of operating frequency [2] S. Gotoda, N. Shibata and M. Ito : ``Task scheduling algorithm for multicore processor system for minimizing recovery time in case of single node fault," International Symposium on Cluster, Cloud, and Grid Computing (CCGrid), pp. 260- 267, 2012. 5
- 6. Outline 1. Background 2. Related Works 3. Modelling of Computing System 4. Proposed Method 5. Evaluation 6. Conclusion 6
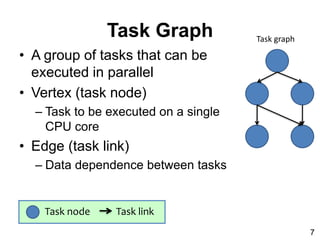
- 7. Task Graph • A group of tasks that can be executed in parallel • Vertex (task node) – Task to be executed on a single CPU core • Edge (task link) – Data dependence between tasks 7 Task node Task link Task graph
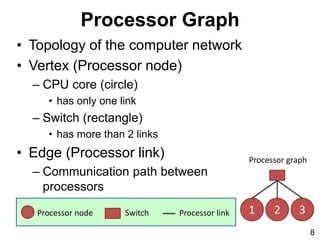
- 8. Processor Graph • Topology of the computer network • Vertex (Processor node) – CPU core (circle) • has only one link – Switch (rectangle) • has more than 2 links • Edge (Processor link) – Communication path between processors 8 Processor node Processor linkSwitch Processor graph 321
- 9. Task Scheduling • Task scheduling problem – assigns a processor node to each task node – minimizes total execution time – An NP-hard problem 9 1 One processor node is assigned to each task node 321 Processor graph Task graph
- 10. Core2 2 processors are working Turbo Boost • Technology for accelerating multicore processors – Scales operating frequencies according to the usage of each core – Higher frequency if small number of cores are working – Lower frequency if all of the cores are working • Assumption – Operating frequency only depends on usage of each core • It does not depend on temperature – Frequency is switched instantly, anytime Core0 Core1 Core3 4 processors are working Idle 3 processors are working 10 Frequency
- 11. Hyper-Threading Physical processor core Hardware Resource Register file 1 Register file 2 Thread 1 Thread 2 Hardware Thread 1 Hardware Thread 2 • Multiple hardware threads are executed on a single physical processor – Hardware resources are shared among multiple threads – Reduces performance penalty by pipeline stall • We define Effective operating frequency • Speed index reflecting reduction of executing speed by sharing resources between hardware threads 11
- 12. Modelling Frequency Control by Turbo Boost and Hyper-Threading • Effective operating frequency depends on only – The number of working processors – The property of executed program • We measure the operating frequencies corresponding to processor states beforehand – Programs with different properties are executed on multiple cores at a time – We measure the operating frequency of the real devices 12
- 13. Modelling Effective Frequency State of cores Frequency [ c , i ] , [ i , i ] , [ i , i ] , [ i , i ] To be measured [ c , i ] , [ c , i ] , [ i , i ] , [ i , i ] To be measured Operating frequency when Turbo Boost is enabled (The processor has 4 cores 8 hardware threads) i:idle, c:computation heavy m:memory access heavy, n:In between c and m • We want to predict the operating frequency from the number of working cores – We changed the number of working cores – We measured the operating frequency Physical core Hardware thread 13
- 14. Results of Measurement State Freq Ratio Effective freq. [ c , c ] 3.1GHz 0.84 2.6GHz [ m , m ] 3.1GHz 0.76 2.3GHz [ n , n ] 3.1GHz 0.79 2.5GHz Only Turbo Boost is used Only Hyper Threading is used State of cores i : idle c : computation heavy m : memory-access heavy n : In between c and m When Turbo Boost is used Effective freq. depends on number of working cores When Hyper-Threading is used Effective freq. depends on properties of programs State of cores Effective freq. [ c , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz [ c , i ] [ c , i ] [ i , i ] [ i , i ] 3.5GHz [ c , i ] [ c , i ] [ c , i ] [ i , i ] 3.3GHz [ c , i ] [ c , i ] [ c , i ] [ c , i ] 3.1GHz [ m , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz [ m , i ] [ m , i ] [ m , i ] [ m , i ] 3.1GHz [ n , i ] [ i , i ] [ i , i ] [ i , i ] 3.7GHz [ n , i ] [ n , i ] [ n , i ] [ n , i ] 3.1GHz 14
- 15. Outline 1. Background 2. Related Works 3. Modelling of Computing System 4. Proposed Method 5. Evaluation 6. Conclusion 15
- 16. Problem in Existing Scheduling • Tasks are assigned in order • Assumes fixed executing speed • When operating frequency is dynamically changed – Operating frequency is high when the first task is assigned – Frequency is reduced as many tasks are assigned to cores Core1 Core2 Core3 Core4 a Resulting schedule Existing scheduling technique :Freq. for 1 core execution 1 2 3 4 a b c 12 1 2 1 d e :Freq. for 2 core execution Execution Time 16
- 17. • Tasks are assigned in order • Assumes fixed executing speed • When operating frequency is dynamically changed – Operating frequency is high when the first task is assigned – Frequency is reduced as many tasks are assigned to cores Problem in Existing Scheduling Core1 Core2 Core3 Core4 a Resulting schedule :Freq. for 1 core execution 1 2 3 4 a b c 12 1 2 1 d e :Freq. for 2 core execution b Execution Time Existing scheduling technique 17
- 18. • Tasks are assigned in order • Assumes fixed executing speed • When operating frequency is dynamically changed – Operating frequency is high when the first task is assigned – Frequency is reduced as many tasks are assigned to cores Problem in Existing Scheduling :Freq. for 1 core execution :Freq. for 2 core execution a Resulting schedule 1 2 3 4 a b c 12 1 2 1 d e Core1 Core2 Core3 Core4 a b Execution Time Existing scheduling technique 18
- 19. • Tasks are assigned in order • Assumes fixed executing speed • When operating frequency is dynamically changed – Operating frequency is high when the first task is assigned – Frequency is reduced as many tasks are assigned to cores Problem in Existing Scheduling :Freq. for 1 core execution :Freq. for 2 core execution Core1 Core2 Core3 Core4 Resulting schedule a 1 2 3 4 a b c 12 1 2 1 d e b Execution time for a is increased because b is assigned Execution Time Existing scheduling technique 19
- 20. • Execution time changes by assigning following tasks • We cannot know which core is assigned to which task until the scheduling is finished Problem and Solution Problem • Tentatively assign tasks and estimate the operating frequencies Solution 20
- 21. Proc 2 N1 Execution Time Proc 1 Core1 Core2 Core3 Core4 Estimating Execution Time of Tasks Node 1 32 4 Link 5 a c db d 2 2 2 22 21 43 Task graph Processor graph comm. TB 1core TB 2Core HT • Initial assignment of the first task 21
- 22. Proc 2 N1 Execution Time Proc 1 Core1 Core2 Core3 Core4 Estimating Execution Time of Tasks Node 1 32 4 Link 5 a c db d 2 2 2 22 21 43 comm. TB 1core TB 2Core HT N2 • Initial assignment of the second task Task graph Processor graph 22
- 23. Proc 2 N1 N4 C Execution Time Proc 1 Core1 Core2 Core3 Core4 Tentative Assignment Node 1 32 4 Link 5 a c db d 2 2 2 22 21 43 comm. TB 1core TB 2Core HT • We calculate communication time using the existing method • Operating frequency is tentatively fixed N3 C N5 Tentatively assigned N2 Task graph Processor graph 23
- 24. Proc 2 • Operating frequency is determined by observing usage of each core C Execution Time Proc 1 Core1 Core2 Core3 Core4 Determining Operating Freq. Node 1 32 4 Link 5 a c db d 2 2 2 22 21 43 comm. TB 1core TB 2Core HT C N1 N3 N4 N2 N5 Task graph Processor graph 24
- 25. Proc 2 C Proc 1 Core1 Core2 Core3 Core4 C N1 N4 N2 N5 Selecting Processor to Assign • Processor is assigned so that the whole processing time of the task graph is minimized Proc 2 C Execution Time Proc 1 Core1 Core2 Core3 Core4 comm. TB 1core TB 2Core HT C N1 N3 N4 N2 N5 Execution Time C N3 C 0 5 10 0 5 10 9 11 Compare the execution time of the whole task graph 25
- 26. Outline 1. Background 2. Related Works 3. Modelling of Computing System 4. Proposed Method 5. Evaluation 6. Conclusion 26
- 27. Evaluation • Items to be evaluated – Execution time of the whole task graph – Accuracy of estimation of execution time • Compared method – We extended the Sinnen’s scheduling method in a straight-forward way • Sinnen’s method only considers network contention • We switched the subroutine to calculate the task execution time with our model • The first method only assigns to the physical cores (SinnenPhysical) • The second method assigns to all hardware threads (SinnenLogical) 27
- 28. Configuration • System – CPU:Intel Core i7 3770T(2.5GHz, 4 cores, 8 hardware threads, single socket) – Memory:16.0GB – OS:Windows7 SP1(64bit) – Java(TM) SE (1.6.0 21, 64bit) – Gigabit LAN subsystem using the Intel 82579V Gigabit Ethernet Controller • Network – 4 computers are connected with Gigabit Ethernet – 420Mbps bandwidth (Measured with the real system) 28
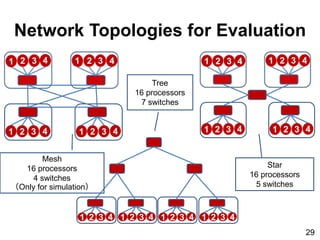
- 29. Network Topologies for Evaluation 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 Star 16 processors 5 switches Mesh 16 processors 4 switches (Only for simulation) Tree 16 processors 7 switches 29
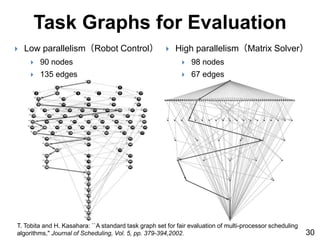
- 30. Task Graphs for Evaluation High parallelism(Matrix Solver) 98 nodes 67 edges Low parallelism(Robot Control) 90 nodes 135 edges T. Tobita and H. Kasahara: ``A standard task graph set for fair evaluation of multi-processor scheduling algorithms," Journal of Scheduling, Vol. 5, pp. 379-394,2002. 30
- 31. Execution Time of Whole Task Graph • Execution time is reduced by up to 35% • Higher parallelism leads to more reduction – Because of greater freedom of choosing which core to assign TaskExecutionTime (sec) 16% 35% 9% 24% 0 50 100 150 200 250 Robot Solver Robot Solver Tree Star SinnenPhysical SinnenLogical Proposed 31
- 32. 0 50 100 150 200 250 Robot Solver Robot Solver Tree Star SinnenPhysical Simulation SinnenPhysical Experiment System SinnenLogical Simulation SinnenLogical Experiment System Proposed Simulation Proposed Experiment System Accuracy of Estimation of Execution Time • Estimation error is 4% in average, 7% at maximum TaskExecutionTime (sec) 5 % 6 % 7 % 7 % 6 % 5 % 5 % 6 % 4 % 1 % 2 % 1 % 32
- 33. Conclusion • Task scheduling method for multicore processor systems – Considering dynamic scaling of operating frequency by Turbo Boost and Hyper Threading – Network contention • We modeled frequency control by Turbo Boost and Hyper-Threading 33
- 34. Yosuke Wakisaka, Naoki Shibata, Keiichi Yasumoto, Minoru Ito, and Junji Kitamichi : Task Scheduling Algorithm for Multicore Processor Systems with Turbo Boost and Hyper- Threading, In Proc. of The 2014 International Conference on Parallel and Distributed Processing Techniques and Applications(PDPTA'14), pp. 229- 235, 2014-07-21 [ PDF ] 34
Editor's Notes
- #4: この様な要望にこたえるには,最新の処理高速化技術を考慮し,処理時間全体を短縮する効率的なタスクスケジューリング手法が必要となります. しかし,既存手法の中にはこれら最新技術を考慮してタスクの割り当てを行う手法は存在しません. そこで本研究ではターボブースト及びハイパースレッディングによる動作周波数の動的変更とネットワークによる特性を考慮するタスクスケジューリング手法の提案を行います. この研究では,一つのタスクグラフ全体の処理時間を最小化することを目指します.
- #8: ジョブ:実行されるデータの固まり タスクノード:並列実行可能なデータ タスクリンク:依存関係を含むタスク間のデータの流れを表す。
- #10: タスクスケジューリング問題は最適化問題で,NP困難に属し, 様々なヒューリスティックな手法が提案されている.
- #12: ハイパースレッディングでは一つの物理プロセッサ上で複数の論理プロセッサを動作させ,各論理プロセッサでスレッドを処理することで,プロセッサの処理並列度を向上します. ハイパースレッディングでは複数の論理プロセッサが物理プロセッサ内の実行リソースを共有して動作するため,物理プロセッサで処理する場合に比べ,実行速度が低下してしまう.
- #13: 本研究ではこれらの2つの技術による動作周波数モデルを構築する. 構築するモデルはプロセッサの使用状況にのみ依存し動作周波数を一意に決定出来るものであり,割り当てるプロセッサの使用状況をしらべ,タスクを処理する動作周波数を決定するために利用する. この動作周波数モデルの構築は実機実験を通して負荷プログラムを複数回実行し,その際の動作周波数を測定を行い,測定した結果をもとに行います.
- #14: 構築する動作周波数モデルは次のようになっています. ターボブースト時の動作周波数を求めるために 負荷プログラムを用いて各プロセッサの状態を以下の4状態にします. そして,物理プロセッサに割り当てて同時に実行する負荷プログラムの数変更しその時々の動作周波数を測定します. 4コア8スレッドのマルチコアプロセッサの動作周波数モデルの例を示します. この様に括弧で囲まれている2つの値で物理プロセッサを表現し,括弧内の各値は論理プロセッサを表現しています.
- #15: モデル化の実験結果です. ターボブースト及びハイパースレッディング時の実効動作周波数はこの様な結果になりました. ターボブースト時はプロセッサの状態に関わらず,使用する物理プロセッサの数にのみ依存して動作周波数が変更していることが確認できました. ハイパースレッディング時は論理プロセッサの状態に依存して実効動作周波数が変化していることがわかります. 提案手法におけるプロセッサの動作周波数の決定では,この結果を用いて,プロセッサが各状態である場合の実効動作周波数を一意に決定します.
- #28: 提案手法を評価するためにシミュレーションによる比較を行いました. タスクグラフの処理時間とスケジュールの生成に要する時間を評価項目とします. 比較手法として既存手法をマルチコア環境に適用させるため本研究で構築した動作周波数モデルを使用して,タスクの処理時間を算出するように拡張した2つの手法を用意した. これら2つの手法はそれぞれ物理プロセッサのみに割り当てを行う手法と論理プロセッサに割り当てを行う
- #32: これら2つのグラフは組み合わせ毎の処理時間を表しています. 左がシミュレーションにより推定した処理時間,右がシミュレーションした結果を基に実機上で実行した際の実行時間です. これらの結果からシミュレーションでは最大で43%処理時間を短縮し,実機実験では最大35%の処理時間を短縮していることが判ります. タスクグラフの並列度別にみると,提案手法は並列度が低いRobot Controlのタスクグラフにくらべ,並列度の高いMatrixSolverのタスクグラフの方が処理時間の削減率が大きいことが判る. これは並列度が低いと割り当てパターンがある程度限定されてしまうため,提案手法による割り当てパターンの選択による効果が低いためだと考えられる また,ネットワークの種類ごとに見ると通信に掛るコストが大きなTreeにくらべ,コストの少ないMeshやStarでは比較手法と提案手法の処理時間の差が小さい これは比較手法でも本研究で作成した動作周波数モデルを用いた割り当てを行っており,提案手法によってスケジュールされた結果とある程度似通ったスケジュールがなされているためであると考えられる.しかし,通信コストが大きいTreeでは比較手法はその時々で最速になるようにスケジュールを行うため比較的同じダイの上にスケジュールしがちであるが,提案手法は後続のタスクを考慮してネットワークを介した通信が発生しても全体の処理時間を下げることが可能であるなら別のダイにタスクを割り当てようとするため処理時間の差が大きくなっていると考えられる.
- #33: 先ほどの結果を今度はスケジュール結果毎にシミュレーションと実機実験で比較したものがこのグラフになります. 全ての場合でシミュレーションで作成した動作周波数モデルを用いて推定した処理時間と実際に実機上で動作させた場合の実行時間の差は最大7%,平均でおよそ4%となった. この様にシミュレーションと実機実験での処理時間にわずかではあるが差が生じてしまうのはスケジュール手法における動作周波数モデル内の誤差や,実機上でのネットワークが不安定であり,帯域が安定していないからではないかと思われる.