Text analytics in Python and R with examples from Tobacco Control
Download as PPTX, PDF23 likes15,245 views

This document discusses text analytics techniques for summarizing and analyzing unstructured text documents, with examples from analyzing documents related to tobacco control. It covers data cleaning and standardization steps like removing punctuation, stopwords, stemming, and deduplication. It also discusses frequency analysis using document-term matrices, topic modeling using LDA, and unsupervised and supervised classification techniques. The document provides examples analyzing posts from new users versus highly active users on an online forum, identifying topics and comparing topic distributions between different user groups.






![• Translating text to consistent form
– Scrapy returns unicode strings
– Māori Maori
• SWAPSET =
[[ u"Ā", "A"], [ u"ā", "a"], [ u"ä", "a"]]
• translation_table =
dict([(ord(k), unicode(v)) for k, v in settings.SWAPSET])
• cleaned_content =
html_content.translate(translation_table)
– Or…
• test=u’Māori’ (you already have unicode)
• Unidecode(test) (returns ‘Maori’)](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/85/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-7-320.jpg)




![Deduplication
• Python sets
– shingles1 = set(get_shingles(record1['standardised_content']))
• Shingling and Jaccard similarity
– (a,rose,is,a,rose,is,a,rose)
– {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose)}
• {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is)}
–
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf a free text
http://www.cs.utah.edu/~jeffp/teaching/cs5955/L4-Jaccard+Shingle.pdf](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/85/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-12-320.jpg)
![Frequency Analysis
• Document-Term Matrix
– politi.dtm <- DocumentTermMatrix(politi.corpus_stemmed,
control = list(wordLengths=c(4,Inf)))
• Frequent and co-occurring terms
– findFreqTerms(politi.dtm, 5000)
[1] "2011" "also" "announc" "area" "around"
[6] "auckland" "better" "bill" "build" "busi"
– findAssocs(politi.dtm, "smoke", 0.5)
smoke tobacco quit smokefre smoker 2025 cigarett
1.00 0.74 0.68 0.62 0.62 0.58 0.57](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/85/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-13-320.jpg)









Text analytics in Python and R with examples from Tobacco Control
- 1. Text Analytics with and (w/ examples from Tobacco Control) @BenHealey
- 2. The Process Look intenselyFrequencies Classification Bright Idea Gather Clean Standardise De-dup and select
- 3. http://scrapy.org Spiders Items Pipelines - readLines, XML / Rcurl / scrapeR packages - tm package (factiva plugin), twitteR - Beautiful Soup - Pandas (eg, financial data) http://blog.siliconstraits.vn/building-web-crawler-scrapy/
- 7. • Translating text to consistent form – Scrapy returns unicode strings – Māori Maori • SWAPSET = [[ u"Ā", "A"], [ u"ā", "a"], [ u"ä", "a"]] • translation_table = dict([(ord(k), unicode(v)) for k, v in settings.SWAPSET]) • cleaned_content = html_content.translate(translation_table) – Or… • test=u’Māori’ (you already have unicode) • Unidecode(test) (returns ‘Maori’)
- 8. • Dealing with non-Unicode – http://nedbatchelder.com/text/unipain.html – Some scraped html will be in latin1 (mismatch UTF8) – Have your datastore default to UTF-8 – Learn to love whack-a-mole • Dealing with too many spaces: – newstring = ' '.join(mystring.split()) – Or… use re • Don’t forget the metadata! – Define a common data structure early if you have multiple sources
- 9. Text Standardisation • Stopwords – "a, about, above, across, ... yourself, yourselves, you've, z” • Stemmers – "some sample stemmed words" "some sampl stem word“ • Tokenisers (eg, for bigrams) – BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 2, max = 2)) – tdm <- TermDocumentMatrix(crude, control = list(tokenize = BigramTokenizer)) – ‘and said’, ‘and security’ Natural Language Toolkittm package
- 10. Text Standardisation libs = c("RODBC", "RWeka“, "Snowball","wordcloud", "tm" ,"topicmodels") … cleanCorpus = function(corpus) { corpus.tmp = tm_map(corpus, tolower) # ??? Not sure. corpus.tmp = tm_map(corpus.tmp, removePunctuation) corpus.tmp = tm_map(corpus.tmp, removeWords, stopwords("english")) corpus.tmp = tm_map(corpus.tmp, stripWhitespace) return(corpus.tmp) } posts.corpus = cleanCorpus(posts.corpus) posts.corpus_stemmed = tm_map(posts.corpus, stemDocument)
- 11. Text Standardisation • Using dictionaries for stem completion politi.tdm <- TermDocumentMatrix(politi.corpus) politi.tdm = removeSparseTerms(politi.tdm, 0.99) politi.tdm = as.matrix(politi.tdm) # get word counts in decreasing order, put these into a plain text doc. word_freqs = sort(rowSums(politi.tdm), decreasing=TRUE) length(word_freqs) smalldict = PlainTextDocument(names(word_freqs)) politi.corpus_final = tm_map(politi.corpus_stemmed, stemCompletion, dictionary=smalldict, type="first")
- 12. Deduplication • Python sets – shingles1 = set(get_shingles(record1['standardised_content'])) • Shingling and Jaccard similarity – (a,rose,is,a,rose,is,a,rose) – {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose)} • {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is)} – http://infolab.stanford.edu/~ullman/mmds/ch3.pdf a free text http://www.cs.utah.edu/~jeffp/teaching/cs5955/L4-Jaccard+Shingle.pdf
- 13. Frequency Analysis • Document-Term Matrix – politi.dtm <- DocumentTermMatrix(politi.corpus_stemmed, control = list(wordLengths=c(4,Inf))) • Frequent and co-occurring terms – findFreqTerms(politi.dtm, 5000) [1] "2011" "also" "announc" "area" "around" [6] "auckland" "better" "bill" "build" "busi" – findAssocs(politi.dtm, "smoke", 0.5) smoke tobacco quit smokefre smoker 2025 cigarett 1.00 0.74 0.68 0.62 0.62 0.58 0.57
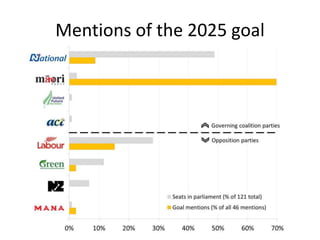
- 15. Mentions of the 2025 goal
- 16. Mentions of the 2025 goal
- 17. Top 100 terms: Tariana Turia Note: Documents from Aug 2011 – July 2012 Wordcloud package
- 18. Top 100 terms: Tony Ryall Note: Documents from Aug 2011 – July 2012
- 19. • Exploration and feature extraction – Metadata gathered at time of collection (eg, Scrapy) – RODBC or MySQLdb with plain ol’ SQL – Native or package functions for length of strings, sna, etc. • Unsupervised – nltk.cluster – tm, topicmodels, as.matrix(dtm) kmeans, etc. • Supervised – First hurdle: Training set – nltk.classify – tm, e1071, others… Classification
- 20. 2 posts or fewer more than 750 posts 846 1,157 23 45,499 41.0% 1.3% 1.1% 50.1%
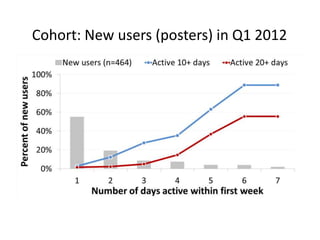
- 21. Cohort: New users (posters) in Q1 2012
- 22. • LDA (topicmodels) – New users – Highly active users Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 good smoke just smoke feel day time day quit day thank week get can dont well patch realli one like will start think will still Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 quit good day like feel smoke one well day thing can take great your just will stay done now get luck strong awesom get time
- 23. • LDA (topicmodels) – Highly active users (HAU) – HAU1 (F, 38, PI) – HAU2 (F, 33, NZE) – HAU3 (M, 48, NZE) Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 quit good day like feel smoke one well day thing can take great your just will stay done now get luck strong awesom get time 18% 14% 40% 8% 20% 31% 21% 27% 6% 16% 16% 9% 21% 49% 5%
- 24. Recap • Your text will probably be messy – Python, R-based tools reduce the pain • Simple analyses can generate useful insight • Combine with data of other types for context – source, quantities, dates, network position, history • May surface useful features for classification Slides, Code: message2ben@gmail.com
Editor's Notes
- #5: Gather stage.
- #6: Gather stage.
- #7: Clean stage
- #8: Clean stage
- #9: Clean stage
- #10: Standardise stage
- #11: Standardise stage
- #12: Standardise stage0.99 is generous. Lower would remove more terms.A term-document matrix where those terms from x are removed which have at least asparse percentage of empty (i.e., terms occurring 0 times in a document) elements. I.e., the resulting matrix contains only terms with a sparse factor of less than sparse.TermDocumentMatrix (terms along side (rows), docs along top (columns))
- #13: Dedup and select stage
- #14: Analysis stage
- #15: Analysis stage
- #16: Analysis stage
- #17: Analysis stage
- #18: Analysis stage
- #19: Analysis stage
- #20: Analysis stageDragonfly talk by Marcus Frean on LatentDirichletAllocation
- #21: Analysis stage (exploratory)
- #22: Analysis stage (Exploratory)
- #23: Analysis stage (Unsupervised classification)
- #24: Analysis stage (Unsupervised classification)