Man2
0 recomendaciones664 vistas

Este documento presenta información sobre estimación de parámetros, contraste de hipótesis y análisis de datos. Explica cómo calcular intervalos de confianza para proporciones poblacionales a partir de una muestra. También describe cómo determinar el tamaño mínimo necesario de una muestra para lograr un nivel deseado de precisión. Finalmente, introduce conceptos clave relacionados con el contraste de hipótesis como hipótesis nula, medida de discrepancia y nivel de significación.















































![• Sabemos que n tiene que ser un número
natural y es igual al número de elementos
muestreados. Por su parte, p se encuentra en
el intervalo cerrado [0, 1], es decir, que puede
tomar cualquier valor entre 0 y 1, incluyendo
estos valores. Por ello el espacio de búsqueda
paramétrico viene dado por los intervalos [0,
1] para cada n entero.
• Dado un valor concreto de n, el espacio de
búsqueda sería el intervalo desde 0 hasta 1.](https://image.slidesharecdn.com/tema1diseosdeinvestigacinyanlisisdedatos3-111026123852-phpapp01/85/Man2-48-320.jpg)







































Man2
- 1. DISEÑOS DE INVESTIGACIÓN Y ANÁLISIS DE DATOS TEMA 1 Estimación de parámetros y contraste de hipótesis
- 2. Ejemplo 1.6 • Para dejar constancia real de las preferencias de los padres sobre la lengua vehicular en la que prefieren que se eduque a sus hijos, una determinada asociación de padres realiza una encuesta sobre una muestra de 800 familias residentes en una determinada autonomía bilingüe, encontrando que 280 familias son partidarias de que todas de las asignaturas se enseñen en Castellano. Con un nivel de confianza del 95% ¿entre que valores se encontrará la proporción de padres que en esa Comunidad son partidarios de que todas las asignaturas se impartan en Castellano?
- 3. Distribución muestral de la proporción DM de la proporción N sujetos=800 Variable X= familias dicotómica 280 (partidario partidarias castellano castellano =p si/no) MUESTRA POBLACIÓN
- 4. Distribución muestral de la proporción DM de la proporción N sujetos=800 Variable X= familias dicotómica 280 (partidario partidarias castellano castellano si/no) MUESTRA P=280/800=0.35 POBLACIÓN
- 5. Al tratarse de una muestra grande (N=800), la distribución binomial se aproxima a la normal. Buscamos en la tabla los valores Z que dejan una probabilidad central del 95% y son -1,96 y +1,96.
- 6. Al tratarse de una muestra grande (N=800), la distribución binomial se aproxima a la normal. Buscamos en la tabla los valores Z que dejan una probabilidad central del 95% y son -1,96 y +1,96.
- 10. P=0.35 N = 800
- 11. P=0.35 N = 800
- 12. • Por consiguiente, la proporción poblacional, , es un valor comprendido entre 0,317 (31,7%) y 0,383 (38,3%) con una probabilidad o nivel de confianza, del 95%.
- 13. Amplitud del intervalo de confianza y su relación con el tamaño muestral • La amplitud de un intervalo de confianza depende de dos factores: el nivel de confianza y el error típico de la distribución muestral del estadístico. Este segundo factor está en proporción inversa al tamaño de la muestra: cuanto mayor es el tamaño de la muestra, menor es el error típico (manteniendo constante el resto de factores, ceteris paribus)
- 14. Ejemplo: CI de la media • El error típico de la media, cuando se desconoce la varianza poblacional y además la muestra es pequeña, es • y para obtener el intervalo de confianza se multiplica por el valor de la distribución t de Student para el nivel de confianza (NC) que se haya estipulado.
- 15. • Es decir, el error máximo de estimación y lo designamos con E, es:
- 16. • Si despejamos el tamaño muestral (n) y lo ponemos en función del resto de elementos el resultado es:
- 17. • Si el tamaño de la muestra es grande, entonces la distribución de referencia es la normal tipificada y la expresión anterior se transforma en:
- 18. Cálculo del tamaño de la muestra en función del nivel de confianza y del error máximo de estimación
- 19. Ejemplo 1.7 • Se desea calcular el tamaño muestral (n) necesario en una encuesta electoral de manera que la precisión de la proporción de voto estimada, o error máximo de estimación, sea de ± 0,02.
- 20. • Asumiendo que la proporción de votos a favor y en contra es del 50% (máxima incertidumbre):
- 21. Con este número de sujetos, el investigador se asegura de que la amplitud del intervalo de confianza será de 4 puntos porcentuales (+/- 0.02 porcentual).
- 23. • Si la precisión de la estimación fuera de 0,01 entonces el tamaño de la muestra pasaría a ser de 9604 sujetos. Es decir: cuanto más pequeño queramos que sea el error máximo (mayor precisión), mayor tendrá que ser el número de sujetos a utilizar.
- 24. Contraste de hipótesis • Una hipótesis estadística es una afirmación sobre una población que puede someterse a prueba a través una muestra aleatoria de esa población. Una vez que la hipótesis se ha contrastado con los datos de la muestra es el momento de tomar alguna decisión respecto a su resultado. El contraste de hipótesis es, pues, una parte esencial del método científico.
- 25. • En general, siempre se parte de algún interrogante que se plantea en el ámbito de una investigación, a la luz de un determinado marco teórico.
- 26. • Una vez planteada la cuestión, hay que buscar una respuesta que adopte la forma de afirmación empíricamente verificable, es decir, debemos ser capaces de operativizar nuestras preguntas para que tengan entidad de hipótesis científicas. La mejor manera de hacerlo es plantearla en términos estadísticos; esto significa que las afirmaciones que se realicen estén relacionadas de alguna manera con una o más distribuciones de probabilidad.
- 27. • Una hipótesis científica se pueden trasladar a diferentes hipótesis estadísticas, las cuales, al contrastarse dan respuesta a dicha hipótesis científica.
- 28. • Las hipótesis estadísticas planteadas para dar respuesta a las hipótesis científicas se conocen como hipótesis nula, y se representa por H0. Las hipótesis nulas pueden contener afirmaciones como las siguientes: H0: la variable X tiene distribución normal N(50,5).
- 29. • Dependiendo de cómo esté formulada la hipótesis nula se habla de la dirección del contraste. Si, por ejemplo, H0 está planteada como igualdad de las medias de hombres y mujeres, mientras que la alternativa es simplemente su negación (las medias no son iguales) se dice que es un contraste bilateral.
- 30. • Si, por el contrario, conocemos la dirección en que H0 puede ser falsa, como por ejemplo en la hipótesis , o, en general, cuando en la investigación se plantea que un método de aprendizaje, un fármaco, un determinado proceso industrial, etc. tiene efecto positivo (o negativo) sobre lo que estamos estudiando, entonces tenemos un contraste unilateral en la medida en que indicamos la dirección de ese efecto.
- 31. • Una vez que se ha planteado la hipótesis, es preciso definir lo que se conoce como la medida de discrepancia: una medida estandarizada dentro de alguna distribución de probabilidad.
- 32. • La medida de discrepancia, al ser estandarizada, no depende de las unidades en que esté medida la variable y su formulación habitual es:
- 33. • Además de definir la discrepancia es preciso considerar qué cantidad de ésta consideramos admisible. Es decir, debemos determinar, a priori, cuál será la diferencia máxima entre el estimador y el parámetro que estamos dispuestos a considerar compatible con la H0.
- 34. • Esta decisión dependerá tanto de la distribución de probabilidad de la medida de discrepancia (Z, t, , …), como de la dirección 2 del contraste (bilateral, unilateral), como del riesgo que estamos dispuestos a asumir ( ).
- 35. Ejemplo • En una H0 del tipo frente a H1 Un contraste así es del tipo unilateral, y una medida de discrepancia sería
- 36. • Para que se pueda rechazar H0, y por tanto aceptar H1, deberemos encontrar valores grandes y positivos de esta medida, ya que los valores negativos de la T van a favor de H0.
- 37. • Este valor de la discrepancia También se establece en términos de la probabilidad de obtener una discrepancia mayor que la observada. • Esta probabilidad es la que se conoce como nivel p-crítico, y en la mayor parte de las investigaciones se rechazará H0 si este valor es menor de 0,05 o 0,01 (alpha).
- 38. Procedimiento para el contraste de hipótesis • La metodología del contraste de hipótesis es fruto de los trabajos de Fisher, Neyman y Pearson y su lógica recuerda a la de un juicio en un estado de derecho, en el cual el acusado siempre es inocente hasta que las pruebas no demuestren lo contrario.
- 39. Procedimiento para el contraste de hipótesis • En los contrastes de hipótesis, las pruebas son las evidencias recogidas en los datos muestrales provenientes de una investigación bien diseñada. • Si estos datos aportan resultados significativamente diferentes de los planteados en la hipótesis nula, ésta es rechazada y, en caso contrario, es aceptada.
- 40. • Los procedimientos para el cálculo de los intervalos de confianza -y buena parte de los contrastes de hipótesis- se basan en una serie de supuestos (v.gr., que la muestra procede de una población de puntuaciones que se distribuyen según una función de distribución conocida, como la curva normal, o sobre el nivel de medida de la variable, etc.).
- 41. • Estos procedimientos y otros que no se han presentado todavía (ANOVA, regresión múltiple, etc.), se engloban en lo que se conoce como “métodos paramétricos” ya que todos los cálculos matemáticos que se realizan dependen del supuesto de que las puntuaciones proceden de una familia de distribuciones paramétrica particular.
- 42. Ejemplos • Si en un contraste de hipótesis realizamos el supuesto de distribución según la curva normal, tendríamos toda una familia o conjunto de funciones de densidad de probabilidad (f.d.p.) que tienen todas la misma forma (campana de Gauss). Por consiguiente, cada elemento de este conjunto se diferenciaría del resto no por su forma sino por sus parámetros, es decir, por su media y su desviación típica
- 43. • La estadística paramétrica funciona realizando supuestos sobre los valores de y En este . sentido, podemos decir que la estadística paramétrica toma en consideración un “espacio paramétrico”. En el caso del supuesto de normalidad este espacio paramétrico vendría dado por todos los valores posibles para y . Este espacio, se puede representar gráficamente
- 45. • Es importante señalar que valores como la mediana, el rango, etc., no son parámetros de una distribución normal. Así, los únicos parámetros de la distribución normal son y ya que son los valores que aparecen en su definición analítica:
- 46. • Sin embargo, toda función normal tiene mediana (o cualquier estadístico de sesgo, curtosis, etc.). De forma sucinta, la mediana no es un parámetro de la función normal (ni ningún otro estadístico de posición) porque no aparece en la expresión analítica que la define.
- 47. • Pongamos otro ejemplo de familia paramétrica. Si asumimos que el fenómeno que estamos estudiando se distribuye según una Binomial, entonces tendremos que realizar una búsqueda en el espacio de todas las funciones binomiales. Estas funciones tienen dos parámetros: n y p (el número de ensayos o veces que se repite un experimento de Bernouilli y la probabilidad de éxito en cada ensayo, respectivamente).
- 48. • Sabemos que n tiene que ser un número natural y es igual al número de elementos muestreados. Por su parte, p se encuentra en el intervalo cerrado [0, 1], es decir, que puede tomar cualquier valor entre 0 y 1, incluyendo estos valores. Por ello el espacio de búsqueda paramétrico viene dado por los intervalos [0, 1] para cada n entero. • Dado un valor concreto de n, el espacio de búsqueda sería el intervalo desde 0 hasta 1.
- 50. • De la misma forma que antes, p y n son parámetros de la distribución binomial porque aparecen en su expresión analítica:
- 51. • Podemos decir que la aparición de una variable que no sea la variable independiente (v.g., x) en la expresión analítica de una función de densidad de probabilidad (f.p.d) la caracteriza como un parámetro de esa distribución porque define a la distribución. • Por su parte, los parámetros caracterizan unívocamente a la función.
- 52. • En definitiva, la denominación de “técnicas paramétricas” procede de la búsqueda de los parámetros subyacentes a unos datos asumiendo que éstos se distribuyen en la población según una función de probabilidad o de densidad de probabilidad concreta . • Todos los tests paramétricos asumen una determinada forma (normal, binomial, etc.) para la distribución poblacional de los datos observados en la muestra (variable dependiente) y esta forma depende de unos parámetros, distintos y propios de cada f.d.p.
- 53. • Pero a veces nos encontramos con datos, poblaciones o situaciones en que no podemos asumir los supuestos subyacentes a los tests paramétricos y necesitamos procedimientos cuya validez no dependa de esos supuestos. En este caso se nos hace necesario acudir a otro conjunto de técnicas que no exijan buscar los parámetros de la distribución poblacional de los datos.
- 54. • Por contraposición a los anteriores métodos, se los conoce como “métodos no paramétricos”. • Los contrastes de hipótesis no paramétricos se realizan con datos procedentes de una población en la que la variable de estudio no tiene una distribución de probabilidad conocida.
- 55. Las etapas de un contraste de hipótesis las vamos a resumir en los siguientes puntos: 1. Condiciones de la investigación y supuestos que cumplen los datos observados. 2. Formulación de la hipótesis nula y de la alternativa. 3. Estadístico de contraste. 4. Regla de decisión.
- 56. Condiciones de la investigación y supuestos que cumplen los datos observados • Al diseñar cualquier investigación se puede trabajar con una, dos, tres o más muestras, las cuales pueden ser independientes o relacionadas, seleccionadas por muestreo aleatorio o no y en los que se recoge información sobre una o más variables medidas con la misma o diferentes escalas de medida (nominal, ordinal, de intervalo o de razón).
- 57. Condiciones de la investigación y supuestos que cumplen los datos observados • Estos datos pueden provenir de poblaciones en la que la variable de estudio tiene una determinada distribución de probabilidad conocida o desconocida. Todas estas características tanto del diseño como de los datos condicionan tanto la hipótesis que se puede someter a contrastación empírica como el procedimiento de análisis de datos más adecuado para someter a contrastación empírica la hipótesis.
- 58. Formulación de la hipótesis nula y de la alternativa • De acuerdo a los objetivos de la investigación se formula la hipótesis que genera un contraste bilateral o unilateral.
- 59. Estadístico de contraste • El estadístico de contraste es un valor numérico que se calcula aplicando una fórmula especial a los datos muestrales y que asegura que la distribución muestral del mismo en todas las muestras posibles sigue una forma funcional conocida y tabulada. • El valor que adopta el estadístico de contraste se considera como una medida de la discrepancia entres los datos observados y los datos teóricos planteados en la hipótesis nula.
- 60. Estadístico de contraste • Esta medida es una variable aleatoria con una determinada distribución de probabilidad (normal, t, chi-cuadrado, etc.) que va a aportar información empírica sobre la afirmación hecha en H0. Su elección dependerá de las condiciones de investigación y los supuestos que cumplan los datos observados: nivel de medida de los datos, varianza poblacional conocida (o no), etc.
- 61. Regla de decisión • Una vez calculado el estadístico de contraste o discrepancia entre los datos empíricos observados en la muestra y los datos teóricos que planteamos en la hipótesis nula queda tomar una decisión respecto al rechazo o no de la hipótesis nula.
- 62. Regla de decisión • Para ello, hay que establecer el nivel de confianza (y su complementario, o nivel de significación alpha) que representa la probabilidad para no rechazar H0 siendo cierta y calcular la probabilidad de obtener unos resultados como los observados en la muestra bajo la hipótesis de la veracidad de H0. • Esta última probabilidad recibe el nombre de nivel p- crítico. Si el nivel p-crítico es muy pequeño en comparación con rechazamos la H0 y en caso , contrario la mantenemos.
- 63. • Si, bajo el supuesto de que H0 es cierta, se calcula la probabilidad de obtener unos resultados como los observados en la muestra (nivel p-crítico): • Si esta probabilidad es muy pequeña en comparación con alpha, pueden ocurrir dos cosas: – o bien la hipótesis nula es cierta y se ha producido una situación muy poco probable (pero no imposible) – o bien la hipótesis nula es falsa.
- 64. Parece más lógico (o probable) inclinarse por esta segunda opción y ante la evidencia que proporcionan los datos obtenidos en la investigación, se opta por rechazar la hipótesis nula, asumiendo que esta afirmación tiene un cierto riesgo o probabilidad de equivocarnos.
- 65. • Por otra parte, al fijar el nivel de significación, automáticamente se fija el valor o valores críticos de la distribución muestral que marcará la máxima diferencia que podemos admitir, por simple azar, entre el valor teórico planteado en H0 y el valor obtenido en la muestra.
- 66. • Este valor, o valores críticos, definen -en la distribución muestral del estadístico de contraste- los límites entre la zona de rechazo o no de la H0-.
- 67. • La zona de rechazo depende del nivel de significación, 1- y es el , área de la distribución muestral que corresponde a un valor de la discrepancia tan alejado de H0 que la probabilidad de que se produzca es muy baja, si efectivamente H0 es verdadera.
- 68. • La región de no rechazo, complementaria a la anterior depende del nivel de confianza y es el área de la distribución muestral que corresponde a valores pequeños de la discrepancia tan poco alejados la H0 que la probabilidad de que se produzca es alta si efectivamente la H0 es verdadera, por lo que no representa evidencia suficiente para rechazarla.
- 69. • Por tanto, el valor o valores críticos corresponden a la máxima diferencia teórica que cabe esperar por simple azar entre los datos empíricos y los datos teóricos, de tal forma que si el estadístico de contraste se sitúa en la zona de NO rechazo, podemos concluir que la diferencia observada no es significativa y se debe a los errores aleatorios por lo que no podemos rechazar la hipótesis nula con un determinado nivel de confianza.
- 70. • De forma similar si el estadístico de contraste se sitúa en la zona de rechazo indicaría que la diferencia observada entre los datos empíricos y los datos teóricos no puede atribuirse a errores aleatorias y concluimos que la diferencia observada es significativa, lo que nos lleva a rechazar la hipótesis nula con un determinado nivel de confianza.
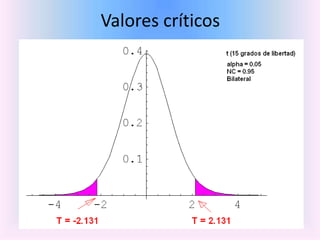
- 71. • Con independencia de la forma de la función de distribución del estadístico de contraste, si el contraste es bilateral tendremos tres zonas delimitadas por los dos valores críticos de la distribución muestral
- 72. • Si el contraste es unilateral izquierdo solo tendremos dos zonas, siendo la región de rechazo la situada en la parte izquierda de la distribución.
- 73. • Si el contraste es unilateral derecho, la región de rechazo se situará en la parte derecha de la distribución muestral
- 74. • En cualquier caso, ya sea comparando el estadístico de contraste con el valor crítico o comparando el nivel p-crítico con el nivel de significación, la decisión que se toma respecto a la H0 es la misma.
- 75. Ejemplo
- 77. Valores críticos
- 78. Ejemplo: si T = 1.93, H0
- 79. Ejemplo: si T = 2.5, No H0
- 82. • Puesto que no hay verdades absolutas y siempre existe un riesgo de error, formalmente la hipótesis nula NUNCA se acepta (solo No se rechaza).
- 83. Conclusión • Formulada la hipótesis nula, que es la que sometemos a contrastación empírica asumiendo que es provisionalmente verdadera y una vez calculado el estadístico de contraste, se concluye rechazando o no la hipótesis nula (lógica “crisp”). • Si no tenemos evidencia suficiente para rechazarla, se está señalando que la hipótesis se mantiene porque es compatible con la evidencia muestral (el acusado en el juicio no es culpable), y si se rechaza se quiere significar que la evidencia muestral no avala la hipótesis (las pruebas están en contra del acusado) y por tanto se rechaza.
- 84. Interpretación • La conclusión en términos de rechazo o no de la hipótesis nula tiene su correspondiente interpretación dentro del contexto de la investigación y de la hipótesis y objetivos que el investigador formula en su trabajo.
- 85. Ordalía • Yo que ponía la mano dentro del fuego por ti, mira como me he quemado de tanta fé que te dí. • Diana Navarro, Una y no más. (2.20 seg.)
- 86. JOKE OF THE DAY Statistics play an important role in genetics. For instance, statistics prove that numbers of offspring is an inherited trait. If your parent didn't have any kids, odds are you won't either.
- 87. JOKE OF THE DAY Statistics play an important role in genetics. For instance, statistics prove that numbers of offspring is an inherited trait. If your parent didn't have any kids, odds are you won't either.
- 88. Joke of the day • Checking some questionnaires that had just been filled in, a census clerk was amazed to note that one of them contained figures 121 and 125 in the spaces for "Age of Mother, If Living" and "Age of Father, if Living." "Surely your parents can't be as old as this?" asked the incredulous clerk. • "Well no," was the answer, "but they would be IF LIVING!"