Power-Efficient Programming Using Qualcomm Multicore Asynchronous Runtime Environment (MARE)
1 like1,429 views

Qualcomm's Multicore Asynchronous Runtime Environment (MARE) is a programming model designed for writing power-efficient and concurrent applications on mobile devices. It provides a C++ API to facilitate parallel processing across available cores and supports both CPU and GPU execution. MARE includes predefined patterns to simplify the development of parallel applications while focusing on efficient task scheduling and power management.











![12
Example: Vector Addition
Advanced algorithms split iterations across cores for best performance and power
void foo(vector const& a, vector const& b, vector &c) {
for(size_t i = 0; i < b.size(); ++i ) {
c[i] = alpha * a[i] + b[i];
});
}
void foo(vector const& a, vector const& b, vector &c) {
mare::pfor_each(0, b.size(), [&](size_t i) {
c[i] = alpha * a[i] + b[i];
});
}](https://image.slidesharecdn.com/23powerefficientprogrammingmontesinos9-140926174441-phpapp02/85/Power-Efficient-Programming-Using-Qualcomm-Multicore-Asynchronous-Runtime-Environment-MARE-12-320.jpg)





![18
Hello World!
#include <stdio.h>
#include <mare/mare.h>
int main() {
mare::runtime::init(); // Initialize MARE runtime
auto hello = mare::create_task([]{ printf("Hello ”); }); // Create task that prints “Hello ”
auto world = mare::create_task([]{ printf(“World!n”); }); // Create task that prints “World!”
hello >> world; // Ensure that “World!” Prints after “Hello ”
mare::launch(hello); // Launch hello task
mare::launch(world); // Launch world task
mare::wait_for(world); // Wait for world to complete
mare::runtime::shutdown(); // Shutdown the MARE runtime and exit
return 0;
}](https://image.slidesharecdn.com/23powerefficientprogrammingmontesinos9-140926174441-phpapp02/85/Power-Efficient-Programming-Using-Qualcomm-Multicore-Asynchronous-Runtime-Environment-MARE-18-320.jpg)














![34
Pipeline Example - Backup Slide
Define stage functions using lambda expressions, function pointers or callable objects
using context = mare::pipeline<File*>::context;
auto stage0 = [context& ctx] {
File* input_file = ctx.get_data();
return do_something0(ctx.get_iter_id(), input_file);
};
using st_input = mare::stage_input<size_t>;
auto stage1 = [context& ctx, st_input& in] {
return do_something1(ctx.get_iter_id(), in[0]);
};
using db_input = mare::stage_input<double>;
auto stage2_body = [context& ctx, db_input& in]->char{
return do_something2(ctx.get_iter_id(), in[1]);
};](https://image.slidesharecdn.com/23powerefficientprogrammingmontesinos9-140926174441-phpapp02/85/Power-Efficient-Programming-Using-Qualcomm-Multicore-Asynchronous-Runtime-Environment-MARE-34-320.jpg)
Power-Efficient Programming Using Qualcomm Multicore Asynchronous Runtime Environment (MARE)
- 1. Power-Efficient Programming Using Qualcomm® Multicore Asynchronous Runtime Environment Pablo Montesinos, Qualcomm Technologies, Inc.
- 2. 2 How can we write native parallel applications that use all available cores?
- 3. 3 How can we easily write native parallel applications that use all available cores?
- 4. 4 How can we easily write native parallel applications that use all available cores in a battery- powered device?
- 5. 5 How can we easily write native parallel applications that use all the available compute units in a battery-powered device?
- 7. 7 What is Qualcomm MARE? The effective solution for efficient mobile computing Qualcomm MARE is a programming model and a runtime system that provides simple yet powerful abstractions and building blocks for writing concurrent, power-efficient software − Simple C++ API allows developers to express concurrency − Enables heterogeneous execution to fully utilize a mobile SoC − User-level library that runs on any Android device Current version is v0.11, available at http://developers.qualcomm.com/mare
- 8. 8 MARE Workflow Understand your algorithms and focus on the application logic, not on the hardware 1. Map your application logic to predefined MARE building blocks (patterns) 2. If the current MARE patterns do not capture part of your application: − Use MARE tasks and groups − If your algorithm can be generalized as a pattern, let us know so that we can add it to our pattern collection 3. Link your app with Qualcomm MARE Runtime − Runtime schedules code in all available compute units
- 9. 9 MARE Patterns A pattern is a commonly occurring combination of task relationships and data accesses Pattern Name Description mare::pfor_each Processes the elements of a collection in parallel mare::pscan Performs and in-place parallel prefix operation for all elements of a collection mare::ptransform Performs a map operation on all elements of a collection, returns a new collection mare::pdivide_and_conquer Divides problem into subproblems, solves them, and merges their solutions in parallel mare::pipeline A sequence of processing stages that can execute concurrently on a data stream
- 10. 10 MARE Patterns A pattern is a commonly occurring combination of task distribution and data access Pattern Name Description mare::pfor_each Processes the elements of a collection in parallel mare::pscan Performs and in-place parallel prefix operation for all elements of a collection mare::ptransform Performs a map operation on all elements of a collection, returns a new collection mare::pdivide_and_conquer Divides problem into subproblems, solves them, and merges their solutions in parallel mare::pipeline A sequence of processing stages that can execute concurrently on a data stream
- 11. 11 MARE pfor_each Pattern Boost the performance of your application by changing just one line Exploit data parallelism in loops Easy replacement for traditional “for” loops MARE automatically splits the iteration space based on dynamic system load
- 12. 12 Example: Vector Addition Advanced algorithms split iterations across cores for best performance and power void foo(vector const& a, vector const& b, vector &c) { for(size_t i = 0; i < b.size(); ++i ) { c[i] = alpha * a[i] + b[i]; }); } void foo(vector const& a, vector const& b, vector &c) { mare::pfor_each(0, b.size(), [&](size_t i) { c[i] = alpha * a[i] + b[i]; }); }
- 13. 13 MARE Pipeline Pattern Use the pipeline pattern in streaming applications A pipeline is a linear, unidirectional chain of stages (no feedback loops allowed) − A stage is a function that is executed repeatedly over a stream of data. − Each stage iteration consumes the output of the previous and produces an output Two types of stages: − Serial stages execute their iterations sequentially − Parallel stages execute their iterations concurrently
- 14. 14 MARE Pipeline Features Useful for computational photography algorithms Programmers can specify the following parameters for each stage: − Iteration lag: minimum number of iterations that a stage runs ahead of its successor − Degree of concurrency: number of consecutive stage iterations that can run in parallel − Iteration rate: rate of iterations between two consecutive stages Use these parameters to size the sliding window − The sliding window is a fixed-size buffer between stages − Limits memory usage and improves locality
- 15. 15 MARE Pipeline Example A pipeline that ages, blurs and scales and image Read image row Read image row Read image row Read image row Age and blur Scale and Save
- 16. 16 MARE Pipeline Example Define stage functions using lambda expressions, function pointers or callable objects // Create pipeline with pipeline instance specific data of type File* mare::pipeline<FileInfo*> pipe; // Add a serial stage pipe.add_stage(mare::serial_stage(), read_image_row); // Add a parallel stage, (lag = 2, doc = 4) to age and blur image pipe.add_stage(mare::parallel_stage(4), mare::iteration_lag(2), age_and_blur_row); // Add a serial stage to scale and save the image, runs 2x more iterations than previous stage pipe.add_stage(mare::serial_stage(), mare::iteration_rate(1, 2), scale_and_save_row); // Launch pipeline and process all rows pipe.launch_and_wait(&finfo, finfo.get_source_height());
- 17. 17 MARE API in a Nutshell Enable expression of parallelism for large classes of applications Two intuitive concepts: − Tasks are units of work that can be asynchronously executed − Groups are sets of tasks that can be canceled or waited on And a simple but powerful API: − Create CPU/GPU tasks and groups − Setup dependencies between tasks − Add tasks to one or more groups − Launch tasks − Cancel tasks and groups − Wait for tasks and groups − Finish after tasks and groups
- 18. 18 Hello World! #include <stdio.h> #include <mare/mare.h> int main() { mare::runtime::init(); // Initialize MARE runtime auto hello = mare::create_task([]{ printf("Hello ”); }); // Create task that prints “Hello ” auto world = mare::create_task([]{ printf(“World!n”); }); // Create task that prints “World!” hello >> world; // Ensure that “World!” Prints after “Hello ” mare::launch(hello); // Launch hello task mare::launch(world); // Launch world task mare::wait_for(world); // Wait for world to complete mare::runtime::shutdown(); // Shutdown the MARE runtime and exit return 0; }
- 19. 19 MARE GPU Compute Seamless integration of CPU and GPU execution Create GPU tasks by using OpenCL kernels as tasks bodies − The MARE Runtime dispatches them to the graphics driver − MARE takes care of OpenCL boiler plate code Automatic data movement between CPU and GPU based on usage patterns − Use mare::buffer to let the runtime manage data across devices − Programmer can also explicitly synchronize storage between CPU and GPU Adding GPU patterns to patterns library, current version supports mare::pfor_each Both GPU and CPU tasks use the same API − MARE runtime manages the dependencies between all types of tasks
- 20. 20 Task Cancelation Discard unwanted tasks by canceling them Use mare::cancel(task) to cancel a task What does it mean? − If the task hasn’t started running, it will never run. All its successors will get canceled too − If the task has already finished, cancelation means nothing − If the task is running, it’s up to the programmer to decide what to do. Successfully canceling a task causes its successors to also get canceled − We call this cancelation propagation
- 21. 21 Easy Non-blocking Parallelization in MARE Unleash asynchrony throughout your application using mare::finish_after mare::wait_for is an easy way to create dynamic dependencies between tasks, however: − It might block − If you have many outstanding mare::wait_for in your app, performance may suffer mare::finish_after allows the creation of dynamic dependencies without blocking − Enables high-performance continuation-passing-style parallelization Many algorithms will benefit from its use, for example divide and conquer.
- 22. 22 Advantages of Using Qualcomm MARE Simple Productive Efficient Tasks are a natural way to express parallelism Familiar C++ programming Uniform multithreading and heterogeneous programming Focus on application logic, not on thread management Task mapping and dependencies allow the MARE runtime to make intelligent scheduling decisions, optimizing both power and performance. Parallel and heterogeneous execution improves power and thermal efficiency.
- 23. 23 Advantages of Using Qualcomm MARE Simple Productive Efficient Tasks are a natural way to express parallelism Familiar C++ programming Uniform multithreading and heterogeneous programming Focus on application logic, not on thread management Task mapping and dependencies allow the MARE runtime to make intelligent scheduling decisions, optimizing both power and performance. Parallel and heterogeneous execution improves power and thermal efficiency.
- 24. 24 Achieve Power Efficiency Using MARE Runtime uses a holistic view of the application structure to make better scheduling decisions Operating systems see applications as unstructured streams of instructions Power and thermal management are therefore reactive MARE uses a proactive approach that saves energy, reduces peak power, and avoids thermal throttling: − MARE makes scheduling decisions based on the task graph and the state of the system − MARE provides APIs so that programmer can help runtime make these decisions
- 25. 25 MARE Power API Only available in Qualcomm Snapdragon Static power management: − User chooses amongst four predefined power modes: normal, efficient, perf_burst and saver. − mare::power::request_mode(mode, duration) Dynamic Power Management: − Tries to minimize energy consumption preserving user-defined Quality of Service − Works well with “main loop” based applications (games, streams, …) − mare::power:set_goal(desired, tolerance) // Before the main loop − mare::regulate(measured) // Within the main loop − mare::power::clear_goal() // After the main loop
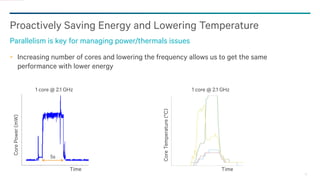
- 26. 26 Proactively Saving Energy and Lowering Temperature Parallelism is key for managing power/thermals issues Increasing number of cores and lowering the frequency allows us to get the same performance with lower energy
- 27. 27 Proactively Saving Energy and Lowering Temperature Parallelism is key for managing power/thermals issues Increasing number of cores and lowering the frequency allows us to get the same performance with lower energy CorePower(mW) CoreTemperature(°C) 1 core @ 2.1 GHz 1 core @ 2.1 GHz MARE 4 cores @ 1 GHz MARE 4 cores @ 1 GHz Time Time 10C 5s 2.8s
- 28. 28 Proactively Saving Energy and Lowering Temperature Parallelism is key for managing power/thermals issues Increasing number of cores and lowering the frequency allows us to get the same performance with lower energy CorePower(mW) CoreTemperature(°C) 1 core @ 2.1 GHz 1 core @ 2.1 GHz MARE 4 cores @ 1 GHz MARE 4 cores @ 1 GHz Time Time 10oC 5s 2.8s
- 29. 29 Case Study Partner Seth Bernsen, GM, Thundersoft America.
- 30. 30 Qualcomm MARE The effective solution for efficient mobile computing MARE patterns are an easy and powerful way to make your algorithms parallel MARE tasks and groups abstractions enable the parallelization of irregular algorithms MARE’s heterogeneous runtime allows you to exploit the whole SoC, not just the CPU − MARE v0.11 supports CPU and GPU − DSP is on the works, stay tuned MARE’s advanced power and thermal management uses programmer input to proactively save energy, reduce peak power, and avoid thermal throttling Current version is v0.11, and it’s available at http://developers.qualcomm.com/mare
- 31. 31 For more information on Qualcomm, visit us at: www.qualcomm.com & www.qualcomm.com/blog Qualcomm is a trademark of Qualcomm Incorporated, registered in the United States and other countries. Other products and brand names may be trademarks or registered trademarks of their respective owners Thank you FOLLOW US ON:
- 32. 32 Canceling a Running Task Cooperative cancelation enables cancelation of running tasks MARE won’t kill tasks that are canceled while executing Running tasks may check whether they have been canceled mare::abort_on_cancel() checks whether the task or any of the groups the task belongs to have been canceled. If so: − It does not return to the task − MARE propagates the cancelation to its successors − MARE chooses a new task to execute
- 33. 33 Removes unwanted shaky motion from videos. Complex process, with several stages: − Estimate the global inter-fame motion vectors − Smooth the vectors − Compute the transformation matrix − Use the matrix to warp and stabilize frames. Electronic Image Stabilization (EIS)
- 34. 34 Pipeline Example - Backup Slide Define stage functions using lambda expressions, function pointers or callable objects using context = mare::pipeline<File*>::context; auto stage0 = [context& ctx] { File* input_file = ctx.get_data(); return do_something0(ctx.get_iter_id(), input_file); }; using st_input = mare::stage_input<size_t>; auto stage1 = [context& ctx, st_input& in] { return do_something1(ctx.get_iter_id(), in[0]); }; using db_input = mare::stage_input<double>; auto stage2_body = [context& ctx, db_input& in]->char{ return do_something2(ctx.get_iter_id(), in[1]); };