Apache Spark: What's under the hood
4 likes929 views

This document provides an overview of Apache Spark's architectural components through the life of simple Spark jobs. It begins with a simple Spark application analyzing airline on-time arrival data, then covers Resilient Distributed Datasets (RDDs), the cluster architecture, job execution through Spark components like tasks and scheduling, and techniques for writing better Spark applications like optimizing partitioning and reducing shuffle size.






![// Read data rows
sc.textFile("hdfs:///.../flights").
2004,2,5...,AA,..,EWR,... 2004,3,22,...,UA,...SFO,... 2004,3,22,...,AA,...EWR,..
// Extract Airport (key) and Airline (value)
(EWR, AA) (SFO, UA) (EWR, UA)
(EWR, [AA, UA]) (SFO, UA)
// Discard duplicate pairs, and compute group size
mapValues(values => values.toSet.size).
// Return results to client
map(row => (row.split(",")(16), row.split(",")(8))).
// Group by Airport
groupByKey.
collect
(EWR, 2) (SFO, 1)
[ (EWR, 2), (SFO, 1) ]](https://image.slidesharecdn.com/dsk-3576apachesparkwhatsunderthehood-170216212840/85/Apache-Spark-What-s-under-the-hood-7-320.jpg)












![DAG Scheduler: Pipelining
2004,2,5...,AA,..,EWR,... 2004,3,22,...,UA,...SFO,... 2004,3,22,...,AA,...EWR,..
(EWR, AA) (SFO, UA) (EWR, UA)
(EWR, [AA, UA]) (SFO, UA)](https://image.slidesharecdn.com/dsk-3576apachesparkwhatsunderthehood-170216212840/85/Apache-Spark-What-s-under-the-hood-20-320.jpg)






![groupByKey
26
mapValues
groupByKey
Stage 2
collect
• After shuffle, each “reduce-side”
partition contains all groups of
the same key
• Within each partition,
groupByKey builds an in-
memory hash map
• EWR -> [UA, AA, ...]
• SFO -> [UA, ...]
• JFK -> [DL, UA, AA, DL, ...]
• Single key-values pair must fit in
memory. Can be spilled to disk in
its entirety.
Stage 1](https://image.slidesharecdn.com/dsk-3576apachesparkwhatsunderthehood-170216212840/85/Apache-Spark-What-s-under-the-hood-27-320.jpg)






































Apache Spark: What's under the hood
- 1. © 2015 IBM Corporation DSK-3576 Apache Spark: What's Under the Hood? Adarsh Pannu Senior Technical Staff Member IBM Analytics Platform adarshrp@us.ibm.com
- 2. Abstract This session covers Spark's architectural components through the life of simple Spark jobs. Those already familiar with the basic Spark API will gain deeper knowledge of how Spark works with the potential of becoming an advanced Spark user, administrator or contributor. 1
- 3. Outline Why Understand Spark Internals? To Write Better Applications. ● Simple Spark Application ● Resilient Distributed Datasets ● Cluster architecture ● Job Execution through Spark components ● Tasks & Scheduling ● Shuffle ● Memory management ● Writing better Spark applications: Tips and Tricks
- 4. First Spark Application On-Time Arrival Performance Dataset Record of every US airline flight since 1980s. Fields: Year, Month, DayofMonth UniqueCarrier,FlightNum DepTime, ArrTime, ActualElapsedTime ArrDelay, DepDelay Origin, Dest, Distance Cancelled, ... “Where, When, How Long? ...” 3
- 5. First Spark Application (contd.) 4 Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,CRS ArrTime,UniqueCarrier,FlightNum,TailNum,ActualElapsedTime,CRSElapse dTime,AirTime,ArrDelay,DepDelay,Origin,Dest,Distance,TaxiIn,TaxiOut,Can celled,CancellationCode,Diverted,CarrierDelay,WeatherDelay,NASDelay,S ecurityDelay,LateAircraftDelay 2004,2,5,4,1521,1530,1837,1838,CO,65,N67158,376,368,326,-1,-9,EWR,LAX,2454,... UniqueCarrier Origin Dest Year,Month,DayofMonth FlightNum ActualElapsedTime Distance DepTime
- 6. First Spark Application (contd.) Which airports handles the most airline carriers? ! Small airports (E.g. Ithaca) only served by a few airlines ! Larger airports (E.g. Newark) handle dozens of carriers In SQL, this translates to: SELECT Origin, count(distinct UniqueCarrier) FROM flights GROUP BY Origin 5
- 7. // Read data rows sc.textFile("hdfs:///.../flights"). 2004,2,5...,AA,..,EWR,... 2004,3,22,...,UA,...SFO,... 2004,3,22,...,AA,...EWR,.. // Extract Airport (key) and Airline (value) (EWR, AA) (SFO, UA) (EWR, UA) (EWR, [AA, UA]) (SFO, UA) // Discard duplicate pairs, and compute group size mapValues(values => values.toSet.size). // Return results to client map(row => (row.split(",")(16), row.split(",")(8))). // Group by Airport groupByKey. collect (EWR, 2) (SFO, 1) [ (EWR, 2), (SFO, 1) ]
- 8. sc.textFile("hdfs:///.../flights"). mapValues(values => values.toSet.size). map(row => (row.split(",")(16), row.split(",")(8))). groupByKey. collect Base RDD Transformed RDDs Action
- 9. What’s an RDD? 8 CO780, IAH, MCI CO683, IAH, MSY CO1707, TPA, IAH ... UA620, SJC, ORD UA675, ORD, SMF UA676, ORD, LGA ... DL282, ATL, CVG DL2128, CHS, ATL DL2592, PBI, LGA DL417, FLL, ATL ... Resilient Distributed Datasets • Key abstraction in Spark Immutable collection of objects • Distributed across machines Can be operated on in parallel Can hold any kind of data Hadoop datasets Parallelized Scala collections RDBMS or No-SQL, ... Can recover from failures, be cached, ...
- 10. Resilient Distributed Datasets (RDD) 1. Set of partitions (“splits” in Hadoop) 2. List of dependencies on parent RDDs 3. Function to compute a partition given its parent(s) 4. (Optional) Partitioner (hash, range) 5. (Optional) Preferred location(s) 9 Lineage Optimized Execution
- 11. We’ve written the code, what next? Spark supports four different cluster managers: ● Local: Useful only for development ● Standalone: Bundled with Spark, doesn’t play well with other applications ● YARN ● Mesos Each mode has a similar “logical” architecture although physical details differ in terms of which/where processes and threads are launched. 10
- 12. Spark Cluster Architecture: Logical View 11 Driver represents the application. It runs the main() function. SparkContext is the main entry point for Spark functionality. Represents the connection to a Spark cluster. Executor runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. Task Driver Program SparkContext Cluster Manager Executor Cache Task
- 13. What’s Inside an Executor? 12 Task Task Task Internal Threads Single JVM Running Tasks RDD1-1 RDD2-3 Cached RDD partitions Shuffle, Transport, GC, ... Free Task Slots Broadcast-1 Broadcast-2 Other global memory
- 14. Spark Cluster Architecture: Physical View 13 Task Task Task RDD P1 RDD P2 RDD P3 Internal Threads Node 1 Executor 1 Task Task Task RDD P5 RDD P6 RDD P1 Internal Threads Node 2 Executor 2 Task Task Task RDD P3 RDD P4 RDD P2 Internal Threads Node 3 Executor 3 Driver
- 15. Ok, can we get back to the code? 14
- 16. Spark Execution Model 15 sc.textFile(”..."). map(row =>...). groupByKey. mapValues(...). collect Application Code RDD DAG DAG and Task Scheduler Executor(s) Task Task Task Task
- 17. Spark builds DAGs 16 Directed (arrows) Acyclic (no loops) Graph • Spark applications are written in a functional style. • Internally, Spark turns a functional pipeline into a graph of RDD objects. sc.textFile("hdfs:///.../flightdata"). mapValues(values => values.toSet.size). map(row => (row.split(",")(16), row.split(",")(8))). groupByKey. collect
- 18. Spark builds DAGs (contd.) 17 HadoopRDD MapPartitionsRDD MapPartitionsRDD ShuffleRDD MapPartitionsRDD Data-set level View Partition level View • Spark has a rich collection of operations that generally map to RDD classes • HadoopRDD, FilteredRDD, JoinRDD, etc.
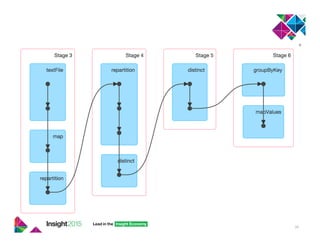
- 19. DAG Scheduler 18 textFile mapValues map groupByKey Stage 1 Stage 2 collect • Split the DAG into stages • A stage marks the boundaries of a pipeline • One stage is completed before starting the next stage
- 20. DAG Scheduler: Pipelining 2004,2,5...,AA,..,EWR,... 2004,3,22,...,UA,...SFO,... 2004,3,22,...,AA,...EWR,.. (EWR, AA) (SFO, UA) (EWR, UA) (EWR, [AA, UA]) (SFO, UA)
- 21. Task Scheduler (contd.) 20 textFile map Stage 1 • Turn the Stages into Tasks • Task = Data + Computation • Ship tasks across the cluster • All RDDs in the stage have the same number of partitions • One task computes each pipeline
- 22. Task Scheduler (contd.) 21 textFile map Stage 1 hdfs://.../flights (partition 1) hdfs://.../flights (partition 2) hdfs://.../flights (partition 3) hdfs://.../flights (partition 4) Computation Data Task 1 Task 2 Task 3 Task 4 1 2 3 4
- 23. 22 Task Scheduler (contd.) HDFS Partitions Time • 3 cores • 4 partitions1 2 2 3 3 4 MapPartitionsRDD HadoopRDD 1 MapPartitionsRDD HadoopRDD 2 MapPartitionsRDD HadoopRDD 3 MapPartitionsRDD HadoopRDD 4
- 24. Task Scheduler: The Shuffle 23 textFile mapValues map groupByKey Stage 1 Stage 2 collect • All-to-all data movement
- 25. Task Scheduler: The Shuffle (contd.) • Redistributes data among partitions • Typically hash-partitioned but can have user-defined partitioner • Avoided when possible, if data is already properly partitioned • Partial aggregation reduces data movement ! Similar to Map-Side Combine in MapReduce 24 1 2 3 1 2 4Stage 1 Stage 2
- 26. Task Scheduler: The Shuffle (contd.) 25 1 1 2 1 2 2 1 2 3 1 2 4 1 2 • Shuffle writes intermediate files to disk • These files are pulled by the next stage • Two algorithms: sort- based (new/default) and hash-based (older)
- 27. groupByKey 26 mapValues groupByKey Stage 2 collect • After shuffle, each “reduce-side” partition contains all groups of the same key • Within each partition, groupByKey builds an in- memory hash map • EWR -> [UA, AA, ...] • SFO -> [UA, ...] • JFK -> [DL, UA, AA, DL, ...] • Single key-values pair must fit in memory. Can be spilled to disk in its entirety. Stage 1
- 28. Task Execution 27 Stage 2 Stage 1 Stage N • Spark jobs can have any number of stages (1, 2, ... N) • There’s a shuffle between stages • The last stage ends with an “action” – sending results back to client, writing files to disk, etc.
- 29. 28
- 30. 29
- 31. 30
- 32. Writing better Spark applications How can we optimize our application? Key considerations: • Partitioning – How many tasks in each stage? • Shuffle – How much data moved across nodes? • Memory pressure – Usually a byproduct of partitioning and shuffling • Code path length – Is your code optimal? Are you using the best available Spark API for the job? 31
- 33. Writing better Spark applications: Partitioning • Too few partitions? ! Less concurrency ! More susceptible to data skew ! Increased memory pressure • Too many partitions ! Over-partitioning leads to very short-running tasks ! Administrative inefficiencies outweigh benefits of parallelism • Need a reasonable number of partitions ! Usually a function of number of cores in cluster ( ~2 times is a good rule of thumb) ! Ensure tasks task execution time > serialization time 32
- 34. Writing better Spark applications: Memory • Symptoms ! Bad performance ! Executor failures (OutOfMemory errors) • Resolution ! Use GC and other traces to track memory usage ! Give Spark more memory ! Tweak memory distribution between User memory vs Spark memory ! Increase number of partitions ! Look at your code! 33
- 35. Rewriting our application sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => (row.split(",")(16), row.split(",")(8))). groupByKey. mapValues(values => values.toSet.size). collect 34 Partitioning Shuffle size Memory pressure Code path length
- 36. Rewriting our application (contd.) sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => (row.split(",")(16), row.split(",")(8))). repartition(16). groupByKey. mapValues(values => values.toSet.size). collect 35 Partitioning Shuffle size Memory pressure Code path length How many stages do you see? Answer: 3
- 37. 36
- 38. Rewriting our application (contd.) sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => (row.split(",")(16), row.split(",")(8))). repartition(16). distinct. groupByKey. mapValues(values => values.toSet.size). collect 37 Partitioning Shuffle size Memory pressure Code path length How many stages do you see now? Answer: 4
- 39. 38
- 40. Rewriting our application (contd.) sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => (row.split(",")(16), row.split(",")(8))). distinct(numPartitions = 16). groupByKey. mapValues(values => values.size). collect 39 Partitioning Shuffle size Memory pressure Code path length
- 41. 40
- 42. Rewriting our application (contd.) sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => { val cols = row.split(",") (cols(16), cols(8)) }). distinct(numPartitions = 16). groupByKey. mapValues(values => values.size). collect 41 Partitioning Shuffle size Memory pressure Code path length
- 43. Rewriting our application (contd.) sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => { val cols = row.split(",") (cols(16), cols(8)) }). distinct(numPartitions = 16). map(e => (e._1, 1)). reduceByKey(_ + _). collect 42 Partitioning Shuffle size Memory pressure Code path length
- 44. Original sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => (row.split(",")(16), row.split(",")(8))). groupByKey. mapValues(values => values.toSet.size). collect Revised sc.textFile("hdfs://localhost:9000/user/Adarsh/flights"). map(row => { val cols = row.split(",") (cols(16), cols(8)) }). distinct(numPartitions = 16). map(e => (e._1, 1)). reduceByKey(_ + _). collect 43 OutOfMemory Error after running for several minutes on my laptop Completed in seconds
- 45. Writing better Spark applications: Configuration How many Executors per Node? --num-executors OR spark.executor.instances How many tasks can each Executor run simultaneously? --executor-cores OR spark.executor.cores How much memory does an Executor have? --executor-memory OR spark.executor.memory How is the memory divided inside an Executor? spark.storage.memoryFraction and spark.shuffle.memoryFraction How is the data stored? Partitioned? Compressed? 44
- 46. As you can see, writing Spark jobs is easy. However, doing so in an efficient manner takes some know-how. Want to learn more about Spark? ______________________________________________ Reference slides are at the end of this slide deck. 45
- 47. 46 Notices and Disclaimers Copyright © 2015 by International Business Machines Corporation (IBM). No part of this document may be reproduced or transmitted in any form without written permission from IBM. U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM. Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. THIS DOCUMENT IS DISTRIBUTED "AS IS" WITHOUT ANY WARRANTY, EITHER EXPRESS OR IMPLIED. IN NO EVENT SHALL IBM BE LIABLE FOR ANY DAMAGE ARISING FROM THE USE OF THIS INFORMATION, INCLUDING BUT NOT LIMITED TO, LOSS OF DATA, BUSINESS INTERRUPTION, LOSS OF PROFIT OR LOSS OF OPPORTUNITY. IBM products and services are warranted according to the terms and conditions of the agreements under which they are provided. Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice. Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary. References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business. Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation. It is the customer’s responsibility to insure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer is in compliance with any law.
- 48. 47 Notices and Disclaimers (con’t) Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products in connection with this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the ability of any such third-party products to interoperate with IBM’s products. IBM EXPRESSLY DISCLAIMS ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. The provision of the information contained herein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual property right. • IBM, the IBM logo, ibm.com, Aspera®, Bluemix, Blueworks Live, CICS, Clearcase, Cognos®, DOORS®, Emptoris®, Enterprise Document Management System™, FASP®, FileNet®, Global Business Services ®, Global Technology Services ®, IBM ExperienceOne™, IBM SmartCloud®, IBM Social Business®, Information on Demand, ILOG, Maximo®, MQIntegrator®, MQSeries®, Netcool®, OMEGAMON, OpenPower, PureAnalytics™, PureApplication®, pureCluster™, PureCoverage®, PureData®, PureExperience®, PureFlex®, pureQuery®, pureScale®, PureSystems®, QRadar®, Rational®, Rhapsody®, Smarter Commerce®, SoDA, SPSS, Sterling Commerce®, StoredIQ, Tealeaf®, Tivoli®, Trusteer®, Unica®, urban{code}®, Watson, WebSphere®, Worklight®, X-Force® and System z® Z/OS, are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml.
- 49. © 2015 IBM Corporation Thank You
- 50. We Value Your Feedback! Don’t forget to submit your Insight session and speaker feedback! Your feedback is very important to us – we use it to continually improve the conference. Access your surveys at insight2015survey.com to quickly submit your surveys from your smartphone, laptop or conference kiosk. 49
- 51. Acknowledgements Some of the material in this session was informed and inspired by presentations done by: Matei Zaharia (Creator of Apache Spark) Reynold Xin Aaron Davidson Patrick Wendell ... and dozens of other Spark contributors. 50
- 53. Intro What is Spark? How does it relate to Hadoop? When would you use it? 1-2 hours Basic Understand basic technology and write simple programs 1-2 days Intermediate Start writing complex Spark programs even as you understand operational aspects 5-15 days, to weeks and months Expert Become a Spark Black Belt! Know Spark inside out. Months to years How deep do you want to go?
- 54. Intro Spark Go through these additional presentations to understand the value of Spark. These speakers also attempt to differentiate Spark from Hadoop, and enumerate its comparative strengths. (Not much code here) " Turning Data into Value, Ion Stoica, Spark Summit 2013 Video & Slides 25 mins https://spark-summit.org/2013/talk/turning-data-into-value " Spark: What’s in it your your business? Adarsh Pannu 60 mins IBM Insight Conference 2015 " How Companies are Using Spark, and Where the Edge in Big Data Will Be, Matei Zaharia, Video & Slides 12 mins http://conferences.oreilly.com/strata/strata2014/public/schedule/detail/33057 " Spark Fundamentals I (Lesson 1 only), Big Data University <20 mins https://bigdatauniversity.com/bdu-wp/bdu-course/spark-fundamentals/
- 55. Basic Spark " Pick up some Scala through this article co-authored by Scala’s creator, Martin Odersky. Link http://www.artima.com/scalazine/articles/steps.html Estimated time: 2 hours
- 56. Basic Spark (contd.) " Do these two courses. They cover Spark basics and include a certification. You can use the supplied Docker images for all other labs. 7 hours
- 57. Basic Spark (contd.) " Go to spark.apache.org and study the Overview and the Spark Programming Guide. Many online courses borrow liberally from this material. Information on this site is updated with every new Spark release. Estimated 7-8 hours.
- 58. Intermediate Spark " Stay at spark.apache.org. Go through the component specific Programming Guides as well as the sections on Deploying and More. Browse the Spark API as needed. Estimated time 3-5 days and more.
- 59. Intermediate Spark (contd.) • Learn about the operational aspects of Spark: " Advanced Apache Spark (DevOps) 6 hours # EXCELLENT! Video https://www.youtube.com/watch?v=7ooZ4S7Ay6Y Slides https://www.youtube.com/watch?v=7ooZ4S7Ay6Y " Tuning and Debugging Spark Slides 48 mins Video https://www.youtube.com/watch?v=kkOG_aJ9KjQ • Gain a high-level understanding of Spark architecture: " Introduction to AmpLab Spark Internals, Matei Zaharia, 1 hr 15 mins Video https://www.youtube.com/watch?v=49Hr5xZyTEA " A Deeper Understanding of Spark Internals, Aaron Davidson, 44 mins Video https://www.youtube.com/watch?v=dmL0N3qfSc8 PDF https://spark-summit.org/2014/wp-content/uploads/2014/07/A-Deeper- Understanding-of-Spark-Internals-Aaron-Davidson.pdf
- 60. Intermediate Spark (contd.) • Experiment, experiment, experiment ... " Setup your personal 3-4 node cluster " Download some “open” data. E.g. “airline” data on stat-computing.org/dataexpo/2009/ " Write some code, make it run, see how it performs, tune it, trouble-shoot it " Experiment with different deployment modes (Standalone + YARN) " Play with different configuration knobs, check out dashboards, etc. " Explore all subcomponents (especially Core, SQL, MLLib)
- 61. Read the original academic papers " Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing, Matei Zaharia, et. al. " Discretized Streams: An Efficient and Fault- Tolerant Model for Stream Processing on Large Clusters, Matei Zaharia, et. al. " GraphX: A Resilient Distributed Graph System on Spark, Reynold S. Xin, et. al. " Spark SQL: Relational Data Processing in Spark, Michael Armbrust, et. al. Advanced Spark: Original Papers
- 62. Advanced Spark: Enhance your Scala skills This book by Odersky is excellent but it isn’t meant to give you a quick start. It’s deep stuff. " Use this as your primary Scala text " Excellent MooC by Odersky. Some of the material is meant for CS majors. Highly recommended for STC developers. 35+ hours
- 63. Advanced Spark: Browse Conference Proceedings Spark Summits cover technology and use cases. Technology is also covered in various other places so you could consider skipping those tracks. Don’t forget to check out the customer stories. That is how we learn about enablement opportunities and challenges, and in some cases, we can see through the Spark hype ☺ 100+ hours of FREE videos and associated PDFs available on spark- summit.org. You don’t even have to pay the conference fee! Go back in time and “attend” these conferences!
- 64. Advanced Spark: Browse YouTube Videos YouTube is full of training videos, some good, other not so much. These are the only channels you need to watch though. There is a lot of repetition in the material, and some of the videos are from the conferences mentioned earlier.
- 65. Advanced Spark: Check out these books Provides a good overview of Spark much of material is also available through other sources previously mentioned. Covers concrete statistical analysis / machine learning use cases. Covers Spark APIs and MLLib. Highly recommended for data scientists.
- 66. Advanced Spark: Yes ... read the code Even if you don’t intend to contribute to Spark, there are a ton of valuable comments in the code that provide insights into Spark’s design and these will help you write better Spark applications. Don’t be shy! Go to github.com/ apache/spark and check it to out.