BSC and Integrating Persistent Data and Parallel Programming Models
Download as PPT, PDF2 likes1,206 views

The document outlines the goals and functions of the Barcelona Supercomputing Center (BSC), which focuses on R&D in various scientific fields and provides supercomputing services to researchers in Spain and Europe. It details BSC's collaborative efforts, technological advancements, including the development of data frameworks like DataClay, and initiatives to enhance energy efficiency in future supercomputers. The document also highlights the integration of persistent data with programming models to facilitate more efficient computational processes.















































BSC and Integrating Persistent Data and Parallel Programming Models
- 1. www.bsc.es Barcelona, September 22nd , 2015 Toni Cortes Leader of the storage-system research group BSC and integrating persistent data and parallel programming models
- 2. 2 Barcelona Supercomputing Center Centro Nacional de Supercomputación • BSC-CNS objectives: – R&D in Computer, Life, Earth and Engineering Sciences. – Supercomputing services and support to Spanish and European researchers. • BSC-CNS is a consortium that includes: – Spanish Government 60% – Catalonian Government 30% – Universitat Politècnica de Catalunya (UPC) 10% • 425 people, 40 countries
- 3. 3 BSC Scientific & Technical Departments
- 4. 4 Mission of BSC R&D Departments EARTH SCIENCES To develop and implement global and regional state-of-the-art models for short-term air quality forecast and long- term climate applications. LIFE SCIENCES To understand living organisms by means of theoretical and computational methods (molecular modeling, genomics, proteomics). CASE To develop scientific and engineering software to efficiently exploit super- computing capabilities (biomedical, geophysics, atmospheric, energy, social and economic simulations). COMPUTER SCIENCES To influence the way machines are built, programmed and used: programming models, performance tools, Big Data, computer architecture, energy efficiency.
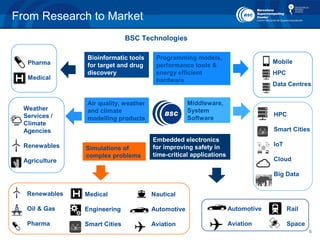
- 5. 5 From Research to Market Embedded electronics for improving safety in time-critical applications Middleware, System Software Automotive Aviation HPC Smart Cities IoT Cloud Big Data Bioinformatic tools for target and drug discovery Pharma Medical Air quality, weather and climate modelling products Weather Services / Climate Agencies Renewables Agriculture Simulations of complex problems Medical Engineering Smart Cities Nautical Automotive Aviation Renewables Oil & Gas Pharma BSC Technologies Programming models, performance tools & energy efficient hardware Mobile HPC Data Centres Rail Space
- 6. 8 Consolidate Spanish Position: Severo Ochoa Energy-efficiency for Exascale and Bigdata Energy-efficiency for Exascale and Bigdata Multidisciplinary research program to address the design and use of future Exascale supercomputers. – Programming models for energy-efficiency and Big Data. – Three challenging applications as a starting point for Interdepartamental collaboration. – Enhancing external cooperation. – Improving human resource management. – Building internal and external training platforms. – Articulating procedures for a better internal and external communication. • Consolidating the Institution as a world leader both in HPC research and applications and in the scientific and professional empowerment of its members.
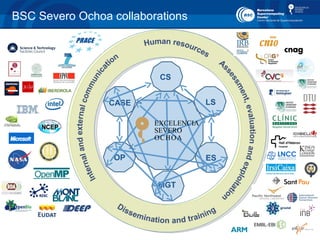
- 7. 9 BSC Severo Ochoa collaborations CS MGT OP CASE LS ES
- 8. 10 International collaborations: Joint- Laboratory on Extreme Scale Computing • In June 2014, the University of Illinois at Urbana-Champaign, INRIA, Argonne National Laboratory, Barcelona Supercomputing Center and Jülich Supercomputing Centre formed the Joint Laboratory on Extreme Scale Computing. • The Joint Laboratory focuses on software challenges found in extreme scale high-performance computers. • Researchers from the different centres regularly meet for workshops, and at the last one, organised by BSC in Barcelona in June 2015, over 100 researchers, from the six centres which are now members, took part.
- 9. 11 JLESC: working together towards success Resilience I/O, Storage and Visualisation Parallel ProgrammingTools Applications and Numerical Algorithms
- 10. 12 Link to EU & Spanish Large Industries Research into advanced technologies for the exploration of hydrocarbons, subterranean and subsea reserve modelling and fluid flows Repsol-BSC Research Center Iberdrola Renovables Model to estimate onshore and offshore wind production
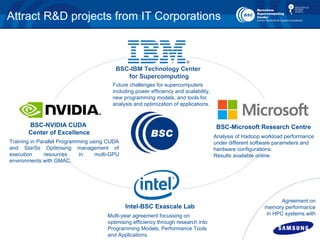
- 11. 13 Attract R&D projects from IT Corporations Analysis of Hadoop workload performance under different software parameters and hardware configurations. Results available online. BSC-Microsoft Research Centre Future challenges for supercomputers including power efficiency and scalability, new programming models, and tools for analysis and optimization of applications. BSC-IBM Technology Center for Supercomputing Training in Parallel Programming using CUDA and StarSs Optimising management of execution resources in multi-GPU environments with GMAC. BSC-NVIDIA CUDA Center of Excellence Multi-year agreement focussing on optimising efficiency through research into Programming Models, Performance Tools and Applications. Intel-BSC Exascale Lab Agreement on memory performance in HPC systems with
- 12. 14 Help to define the future of global HPC International Roadmapping Leadership in Exascale Enabling the Data Revolution Contributing to Standardisation
- 13. 15 Increase Industry Collaboration. BSC & Industry 2012
- 14. 16 Increase Industry Collaboration. BSC & Industry 2015
- 15. 17 Spin-off creation PELE project (Protein Energy Landscape Exploration) NAR, 41, W322-8 (2013); J. Comp Chem 31, 1224-35 (2010) Hormonal nuclear receptors (joint project with AstraZeneca) We can observe how a drug finds its target and we can study, at an atomic level, the way in which they get linked. We can study different effects caused by mutations, as well as new drugs. First BSC’s Spin Off: How a drug finds its target
- 16. 18 BSC People
- 17. www.bsc.es Barcelona, September 22nd , 2015 Toni Cortes Leader of the storage-system research group BSC and integrating persistent data and parallel programming models
- 18. Agenda The pillars The dark side The secret potential Time to wake up!
- 19. From a different perspective… “We cannot solve our problems with the same thinking we used when we created them” Albert Einstein Some of today’s thinking –Data stored in • Files • Databases –Data is a 2nd -class citizen • Accessed with its own primitives • Data and code are different
- 20. Agenda The motivation The pillars The dark side The secret potential Time to wake up!
- 21. Before everything started The pillars of dataClay What ignited our research, our “big bang” – Different data models: persistent vs. non persistent – New storage devices: byte addressable – Coupling data and code – Sharing is what really matters And then dataClay came to life … (more details on how all fits together in the next minutes)
- 22. Two data models! Why waste time doing it twice? Today – We have one data model for volatile data – Traditional data structures and/or objects – We have a different data model for the persistent data – Relational database, NoSQL database, files Future – Store data in the same way as when volatile – Store objects and their relations
- 23. New storage devices Better to be prepared on time New storage hardware is coming – Storage class memory – Non-volatile RAM Main characteristics – Performance between memory and SSDs – Byte addressable File systems or table based DB are not the right abstraction – Both were designed to use block devices – Can be used, but would be a pity • What a potential loss!! • Imagine a Horse-drawn Ferrari?
- 24. Coupling data and computation They can live isolated, but … Computation and data are two different abstractions – They are separated This brings the problem of – Should I move the data to compute it? • Does not work for big data sets – Should I move computation to the data? • Deployment difficult If data and code were the same thing … – Using data would be much easier – (and safer see more in a few minutes)
- 25. Data sharing today And why it is not enough Download files – Flexible – Only for static data – Avoid unneeded copies and transfers – Data provider loses control over the downloaded data “Data services” an API to access the data – Data provider keeps control – Both dynamic and static data – No unneeded copies or transfers – API restricted to what the provider can do
- 26. Agenda The motivation The pillars The technology The dark side The secret potential Time to wake up!
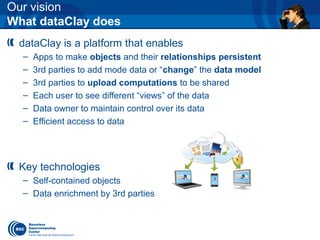
- 27. Our vision What dataClay does dataClay is a platform that enables – Apps to make objects and their relationships persistent – 3rd parties to add mode data or “change” the data model – 3rd parties to upload computations to be shared – Each user to see different “views” of the data – Data owner to maintain control over its data – Efficient access to data Key technologies – Self-contained objects – Data enrichment by 3rd parties
- 28. Key technology Self-contained objects Push the idea of data services to the limit – Based on the OO paradigm Data Client App Client App Data Data Data FunctionsFunctions Security, Integrity, …Security, Integrity, … Data Security, ... Functions Data service Data store Data store
- 29. Self-contained objects But, what is really new? Self-contained and data services – Same concept different implementation? Then… – … we need something else … – … something to make it really flexible!
- 30. 3rd -party enrichment What is it exactly? By enrichment we understand: – Adding new information (fields or data) to existing datasets – Adding new code to existing datasets • New methods • New implementations This enrichment should – Be possible during the life of data – Not be limited to the data owner – Enable different views of the data to different users/clients • Not everybody should see the same enrichments • Several enrichments should be available concurrently – Enable the avoidance of queries
- 31. 3rd -party enrichment And now animated Data can be enriched both with data and code Code will be executed in the provider infrastructure Enrichment Client App Data-provider Infrastructure
- 32. Using a single infrastructure? Killing the bottleneck Using a “single” infrastructure may become a bottleneck Security and privacy policies should be part of the data – Thus, data could be offloaded to other infrastructures • Without breaking the data policies – Data owner enables 3rd party enrichment and … … does not lose control How it is implemented? – Policies are defined using a declarative language – Policies enforced as part of object methods
- 33. Distributing objects Efficient usage of resources – Data and code can be offloaded • to resources not accessible by the data provider Data Security, ... Functions Provider Infrastructure Client Infrastructure Cloud
- 34. Agenda The motivation The pillars The technology The dark side The integration into the parallel programming language The secret potential Time to wake up!
- 35. Task-based programming Task is the unit of work Data dependences between tasks – Imply partial order – Exhibit potential parallelism – Imply local synchronization • Not global! Implicit workflow
- 36. COMPSs Sequential programming – General purpose programming language + annotations • Currently Java and Python Task based – Builds a task graph at runtime • Express potential concurrency • Includes dependencies – Simple linear address space Unaware of computing platform – Enabled by the runtime for clusters, clouds and grids
- 37. Python (PyCOMPSs) syntax How to write PyCOMPS code Invoke tasks – As functions/methods API for data synchronization Task definition in function declaration – decorators class Foo(object): @task() def myMethod(self): … foo = Foo() myFunction( foo ) foo.myMethod() … foo = compss_wait_on(foo) foo.bar() Main Program @task( par = INOUT ) def myFunction(par): … myF myM synch Function definition
- 38. Parallel execution ... T1 (data1, out data2); T2 (data4, out data5); T3 (data2, data5, out data6); T4 (data7, out data8); T5 (data6, data8, out data9); ... T10 T20 T30 T40 T50
- 39. COMPSs framework COMPSs Runtime Job ManagerJob Manager Computing Infrastructure Application Resource ManagerResource Manager SchedulerScheduler Task AnalyzerTask Analyzer Data Info ProviderData Info Provider DAG Application Code Worker Persitent Worker Worker Worker
- 40. ExecuteTask dataClay as a COMPSs worker Executes a method (possibly static) in a given backend – Acts as COMPSs worker threads As opposed to direct method execution – You can decide the execution backend executeTask – Asynchronous • Result can be checked by using getResult Job ManagerJob Manager Computing Infrastructure Worker Persitent Worker Worker Worker dataClay
- 41. A trivial example to follow Input: collection of persons – Person … Integer age … Boolean isOlder (limit, outCollection) { if (age>limit) add self into outCollection } Output: collection of persons older than a given age (limit)
- 42. “Per object” parallelism COMPSs “instantiates” one worker per object – Iterates over a collection using a standard iterator • Instantiates the method in the node where the object is – Targeted at object methods – getLocations • Blocking may be needed – Object-method granularity may be too small – It implies grouping objects in the same backend Task 1 Task 2 Task 3 Task 4 Task 5 Task 6
- 43. “Per object” parallelism Declare method isOlder as a parallel task Code For element in the collection // For each element // This method is executed in parallel // in the node where the data is element.isOlder(age) Parallelizing for each element may be too small –Blocking
- 44. “Per object” parallelism Create a new method isOlderBlocking(age,ini,num) For element between ini and ini+num element.isOlder(age) Code For i in (#elements in collection/block) // For each element // This method is executed in parallel element.isOlderBloking(age,i*block, block) Now we have the right granularity –The scientist needs to define blocking size –And placement if locality is important!!!
- 45. “Per backend” parallelism COMPSs “instantiates” one worker per backend – Obtains all locations using on the collection • getLocations – Each task executes a collection method • Iterates over a “local” iterator – Will only return objects in the current back end – Work stealing may be implemented if needed Task 1 Task 2 Task 3
- 46. “Per backend” parallelism Create a new collection method isOlderCollection(age) For element in collection using local iterator // No parallelism here element.isOlder(age) Define this method as “parallel” Code // Parallelism: executed in all backends with // elements isOlderCollection (age) Now we have the right granularity –Scientists did not have to write “special” code • Only encapsulated and used a “local” iterator
- 47. “Other” iterators These are just examples, other iterators could be defined – To implement locality as in a close backend – To implement work stealing – To take into account heterogeneity The iterators are implemented as general in the collection – Scientist only need to understand what they do • And use them
- 48. Agenda The motivation The pillars The technology The dark side The integration into the parallel programming language The secret potential Conclusions Time to wake up!
- 49. Conclusions Ideas to take back home Integrating persistent data into the programming model – Unifies the model for both persistent and volatile data – Simplifies the decision of where to compute • Code is part of the data – Enables the use of data parallelism • Iterators can be adapted transparently to the programmer – Enables data distribution • Behavior policies are embedded
- 50. I talk, they do the work Thanks to … Current team – Anna Queralt – Jonathan Martí – Daniel Gasull – Juanjo Costa – Alex Barceló Master students – David Gracia – Christos Ioannidis Former team members – Ernest Artiaga