A Comparative Analysis of Data Privacy and Utility Parameter Adjustment, Using Machine Learning Classification as a Gauge
1 like996 views

The document explores the complexities of balancing data privacy and utility through a heuristic known as the comparative classification error gauge (x-ceg). It outlines a methodology for generating synthetic data sets while ensuring acceptable levels of privacy and utility by applying various privacy algorithms and machine classifiers. The findings indicate that choosing the right threshold for classification error can help achieve a suitable trade-off, although achieving the optimal balance remains a challenging task.






















A Comparative Analysis of Data Privacy and Utility Parameter Adjustment, Using Machine Learning Classification as a Gauge
- 1. Complex Adaptive Systems 2013 – Baltimore, MD, USA A Comparative Analysis of Data Privacy and Utility Parameter Adjustment, Using Machine Learning Classification as a Gauge Kato Mivule and Claude Turner Computer Science Department Bowie State University Kato Mivule, Claude Turner, "A Comparative Analysis of Data Privacy and Utility Parameter Adjustment, Using Machine Learning Classification as a Gauge“ Procedia Computer Science, Volume 20, 2013, Pages 414-419 Bowie State University Department of Computer Science
- 2. Complex Adaptive Systems 2013 – Baltimore, MD, USA Agenda • • • • • • • • Introduction The Privacy Problem Data Privacy Techniques Methodology Experiment Results and Discussion Conclusion References Bowie State University Department of Computer Science
- 3. Complex Adaptive Systems 2013 – Baltimore, MD, USA Motivation • Generate synthetic data sets that meet privacy and utility requirements. • Find tolerable levels of utility while maintaining privacy. • Find acceptable trade-offs between privacy and utility needs. • Target the needle in the haystack while discounting the hay. Image source: http://siliconbeachclearly.com Bowie State University Department of Computer Science
- 4. Complex Adaptive Systems 2013 – Baltimore, MD, USA Introduction • Organizations have to comply to data privacy laws and regulations. • Implementation of data privacy is challenging and complex. • Personal identifiable information (PII) is removed and data distorted to attain privacy. • Utility (usefulness) of data diminishes during the data privacy process. Bowie State University Department of Computer Science
- 5. Complex Adaptive Systems 2013 – Baltimore, MD, USA Introduction • Attaining an equilibrium between data privacy and utility needs is intractable. • Trade-offs between privacy and utility needs, is required but problematic. • Given such complexity, we present a heuristic: The Comparative x-CEG approach. Data Privacy ~Differential Privacy ~Noise addition ~K-anonymity, etc... Data Utility ~Completeness ~Currency ~Accuracy Bowie State University Department of Computer Science
- 6. Complex Adaptive Systems 2013 – Baltimore, MD, USA Introduction • For example, using data suppression to attain privacy for categorical data: • Privacy might be guaranteed as PII and other sensitive data is removed. • Accounting for missing categorical entries becomes problematic. • In another example, using noise addition for privacy for numerical data: • High noise perturbation levels might provide privacy. • However, too much noise distorts the original traits of the data. Bowie State University Department of Computer Science
- 7. Complex Adaptive Systems 2013 – Baltimore, MD, USA The privacy definition problem • Privacy is a human and socially driven characteristic comprised of human traits such as acuities and sentiments. Katos, Stowell, and Bedner (2011). • The idea of privacy is fuzzy, confused with security and therefore difficult to engineer. Spiekermann (2012). • The human element is a key factor, data privacy is intrinsically tied to fuzziness and evolutions of how individuals view privacy. Mathews and Harel (2011). • An all-inclusive data privacy methodology should include the legal, technical, and ethical facets. Dayarathna (2011). Bowie State University Department of Computer Science
- 8. Complex Adaptive Systems 2013 – Baltimore, MD, USA The privacy definition problem • The complexities of defining privacy make it difficult for a generalized privacy solution. • Different individuals will have different privacy needs and thus tailored privacy solutions. • Quantifying data utility is likewise problematic, given the complexities of defining privacy. • “Perfect privacy can be achieved by publishing nothing at all, but this has no utility; perfect utility can be obtained by publishing the data exactly as received, but this offers no privacy” Dwork (2006) Bowie State University Department of Computer Science
- 9. Complex Adaptive Systems 2013 – Baltimore, MD, USA The privacy definition problem • Various methods have been employed to enumerate data utility by quantifying the statistical differences between the original and privatized datasets: • • • • • • The relative query error metric. Research value metric. Discernibility data metric. Classification error metric. The Shannon entropy. Information loss metric (mean square error). Bowie State University Department of Computer Science
- 10. Complex Adaptive Systems 2013 – Baltimore, MD, USA Bowie State University Department of Computer Science
- 11. Complex Adaptive Systems 2013 – Baltimore, MD, USA Methodology – The Comparative x-CEG Heuristic • We present the Comparative Classification Error Gauge (x-CEG) Heuristic. • The goal is to generate synthetic data sets with tolerable privacy and utility. Step 1: Apply various privacy algorithms on data, generating privatized data sets. Step 2: The privatized data sets are then subjected to different machine classifiers. Step 3: Empirical and Classification error results are gathered. Step 4: The threshold is computed from the empirical results in Step 3. Step 5: If the classification error is less or equal to a set threshold. Step 6: The process stops and that privatized data set is chosen. Step 7: Otherwise adjustments are made to the privacy algorithm parameters Step 8: Step 2 is repeated on the adjusted privatized data set. Step 9: Repeat until the set threshold requirement is satisfied. Step 10: Publish the privatized synthetic data set. Bowie State University Department of Computer Science
- 12. Complex Adaptive Systems 2013 – Baltimore, MD, USA Methodology – The Comparative x-CEG Heuristic Bowie State University Department of Computer Science
- 13. Complex Adaptive Systems 2013 – Baltimore, MD, USA Methodology – The Comparative x-CEG – Threshold Determination Heuristic. • The threshold value is chosen using the mean value and average value function value. • Classification accuracy of 82 percent for the Neural Nets was chosen. • We chose to use the Neural Nets results because of its overall better performance. Bowie State University Department of Computer Science
- 14. Complex Adaptive Systems 2013 – Baltimore, MD, USA Bowie State University Department of Computer Science
- 15. Complex Adaptive Systems 2013 – Baltimore, MD, USA Experiment •The Iris Fisher multivariate dataset from the UCI repository was used. •One hundred and fifty data points were used as the original data set. •The data numeric attributes: sepal length, sepal width, petal length, and petal width. •The categorical attribute: Iris-Setosa, Iris-Versicolor, and Iris-Virginica. Iris-Setosa, Iris-Versicolor, and Iris-Virginica; Source: http://en.wikipedia.org/wiki/Iris_flower_data_set Bowie State University Department of Computer Science
- 16. Complex Adaptive Systems 2013 – Baltimore, MD, USA The Experiment • The comparative x-CEG algorithm was implemented accordingly: • Three privacy algorithms: Additive, Multiplicative, and Logarithmic noise. • Five classifiers : KNN, Neural Nets (Feed-forward), Decision Trees, AdaBoost, and Naïve Bayes. • Tools: MATLAB for data privacy and Rapid Miner for machine learning. Bowie State University Department of Computer Science
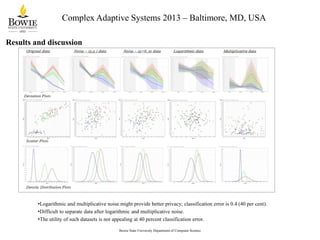
- 17. Complex Adaptive Systems 2013 – Baltimore, MD, USA Results and discussion • • • • The classification error of various privatized data sets is presented. Lower classification error might signify better data utility. Higher classification error might denote better privacy. Neural Nets provided the best performance in this experiment. Bowie State University Department of Computer Science
- 18. Complex Adaptive Systems 2013 – Baltimore, MD, USA Results and discussion •A threshold or trade-off point classification error is set at 0.1867, or 18.67 per cent; the mean value is at 0.2214. • However, this could be lower, depending on user privacy and utility needs. •Therefore, any point between the mean value and the average value function value , is chosen. Bowie State University Department of Computer Science
- 19. Complex Adaptive Systems 2013 – Baltimore, MD, USA Results and discussion •Logarithmic and multiplicative noise might provide better privacy; classification error is 0.4 (40 per cent). •Difficult to separate data after logarithmic and multiplicative noise. •The utility of such datasets is not appealing at 40 percent classification error. Bowie State University Department of Computer Science
- 20. Complex Adaptive Systems 2013 – Baltimore, MD, USA Bowie State University Department of Computer Science
- 21. Complex Adaptive Systems 2013 – Baltimore, MD, USA Conclusion •Employing the Comparative x-CEG heuristic could generate adequate empirical data to assist in selecting a trade-off point for preferred data privacy and utility levels. •However, more rigorous empirical studies are needed to further test this hypothesis. •Finding the optimal balance between privacy and utility needs remains an intractable problem. •For future work, we seek to study optimal trade-off points based on larger empirical datasets, and on a case by case basis. •Also, we plan to conduct analytical and empirical work comparing various data privacy algorithms not covered in this study. Bowie State University Department of Computer Science
- 22. Complex Adaptive Systems 2013 – Baltimore, MD, USA Bowie State University Department of Computer Science
- 23. Complex Adaptive Systems 2013 – Baltimore, MD, USA References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. K. Mivule, C. Turner, and S.-Y. Ji, “Towards A Differential Privacy and Utility Preserving Machine Learning Classifier,” in Procedia Computer Science, 2012, vol. 12, pp. 176–181. V. Rastogi, D. Suciu, and S. Hong, “The Boundary Between Privacy and Utility in Data Publishing,” in 33rd international conference on Very large data bases (VLDB ’07), 2007, pp. 531–542. M. Sramka, R. Safavi-naini, J. Denzinger, and M. Askari, “A Practice-oriented Framework for Measuring Privacy and Utility in Data Sanitization Systems Categories and Subject Descriptors,” in In Proceedings of the 2010 EDBT/ICDT Workshops, 2010, p. 27. R. C.-W. Wong, A. W.-C. Fu, K. Wang, and J. Pei, “Minimality Attack in Privacy Preserving Data Publishing,” Proceedings of the 33rd international conference on Very large data bases, pp. 543–554, 2007. A. Meyerson and R. Williams, “On the complexity of optimal K-anonymity,” in Proceedings of the twenty third ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems PODS 04, 2004, pp. 223–228. H. Park and K. Shim, “Approximate algorithms for K-anonymity,” in Proceedings of the 2007 ACM SIGMOD international conference on Management of data SIGMOD 07, 2007, pp. 67–78. A. Krause and E. Horvitz, “A Utility-Theoretic Approach to Privacy in Online Services,” Journal of Artificial Intelligence Research, vol. 39, pp. 633–662, 2010. Y. W. Y. Wang and X. W. X. Wu, Approximate inverse frequent itemset mining: privacy, complexity, and approximation. 2005. A. Ghosh, T. Roughgarden, and M. Sundararajan, “Universally Utility-Maximizing Privacy Mechanisms,” Proceedings of the 41st annual ACM symposium on Symposium on theory of computing STOC 09, p. 351, 2008. H. Brenner and K. Nissim, “Impossibility of Differentially Private Universally Optimal Mechanisms,” FOCS, no. 860, pp. 71–80, 2010. V. Rastogi, D. Suciu, and S. Hong, “The Boundary between Privacy and Utility in Data Publishing,” VLDB ’07, pp. 531–542, 2007. T. Li and N. Li, “On the tradeoff between privacy and utility in data publishing,” ACM SIGKDD, KDD ’09, pp. 517–526, 2009. S. Fienberg, A. Rinaldo, and X. Yang, “Differential privacy and the risk-utility tradeoff for multi-dimensional contingency tables,” in Privacy in Statistical Databases, Vol. 6344., Josep Domingo-Ferrer and Emmanouil Magkos, Eds. Springer, 2011, pp. 187–199. C. Dwork, “Differential Privacy,” in Automata languages and programming, vol. 4052, no. d, M. Bugliesi, B. Preneel, V. Sassone, and I. Wegener, Eds. Springer, 2006, pp. 1–12. V. Katos, F. Stowell, and P. Bednar, “Data Privacy Management and Autonomous Spontaneous Security,” in Lecture Notes in Computer Science Volume 6514, 2011, pp. 123–139. R. Dayarathna, “Taxonomy for Information Privacy Metrics,” JICLT, vol. 6, no. 4, pp. 194–206, 2011. S. Spiekermann, “The challenges of privacy by design,” Communications of the ACM, vol. 55, no. 7, p. 38, Jul. 2012. M. Friedewald, D. Wright, S. Gutwirth, and E. Mordini, “Privacy, data protection and emerging sciences and technologies: towards a common framework,” Innovation: The European Journal of Social Science Research, vol. 23, no. 1, pp. 61–67, Mar. 2010. G. J. Matthews and O. Harel, “Data confidentiality: A review of methods for statistical disclosure limitation and methods for assessing privacy,” Statistics Surveys, vol. 5, pp. 1–29, 2011. H. Tian, “Privacy-preserving data mining through data publishing and knowledge model sharing,” Dissertation, The University of Texas at San Antonio, 2012. S. Morton, M. Mahoui, and P. J. Gibson, “Data anonymization using an improved utility measurement,” in Proceedings of the 2nd ACM SIGHIT symposium on International health informatics - IHI ’12, 2012, pp. 429–436. R. J. Bayardo and R. Agrawal, “Data Privacy through Optimal k-Anonymization,” in 21st ICDE’05, pp. 217–228, 2005. V. S. Iyengar, “Transforming data to satisfy privacy constraints,” ACM SIGKDD, KDD ’02, pp. 279–288, 2002. M. H. Dunham(b), Data Mining, Introductory and Advanced Topics. Upper Saddle River, New Jersey: Prentice Hall, 2003, pp. 58–60. A. Oganian and J. Domingo-ferrer, “On the complexity of optimal microaggregation for statistical disclosure control,” Statistical Journal of the United Nations Economic Commission for Europe, vol. 4, no. 18, pp. 345–353., 2001. J. Kim, “A Method For Limiting Disclosure in Microdata Based Random Noise and Transformation,” in Proceedings of the Survey Research Methods, American Statistical Association,, 1986, vol. Jay Kim, A, no. 3, pp. 370–374. K. Mivule, “Utilizing Noise Addition for Data Privacy , an Overview,” in IKE 2012, pp. 65–71, 2012. J. J. Kim and W. E. Winkler, “Multiplicative Noise for Masking Continuous Data, Research Report Series, Statistics #2003-01, Statistical Research Division,” Washington, D.C., 2003. K. Bache and M. Lichman, “Iris Fisher Dataset - UCI Machine Learning Repository.” University of California, School of Information and Computer Science., Irvine, CA, 2013. Bowie State University Department of Computer Science