Low complexity low-latency architecture for matching
Download as PPTX, PDF1 like720 views

This document discusses architectures for matching data encoded with error-correcting codes to reduce latency and complexity. It proposes a new architecture that parallelizes comparison of the data and parity portions of systematic codes. It also introduces a butterfly-formed weight accumulator to efficiently compute Hamming distance. Evaluation shows the proposed architecture reduces latency and hardware complexity compared to conventional decode-and-compare and encode-and-compare architectures.



















![References
[1] J. Chang, M. Huang, J. Shoemaker, J. Benoit, S.-L. Chen, W. Chen, S. Chiu, R. Ganesan, G.
Leong, V. Lukka, S. Rusu, and D. Srivastava, “The 65-nm 16-MB shared on-die L3 cache for the
dual-core Intel xeon processor 7100 series,” IEEE J. Solid-State Circuits, vol. 42, no. 4, pp. 846–
852, Apr. 2007.
[2] J. D. Warnock, Y.-H. Chan, S. M. Carey, H. Wen, P. J. Meaney, G. Gerwig,H. H. Smith, Y. H.
Chan, J. Davis, P. Bunce, A. Pelella, D. Rodko, P. Patel, T. Strach, D. Malone, F. Malgioglio, J.
Neves, D. L. Rude, and W. V. Huott “Circuit and physical design implementation of the
microprocessor chip for the zEnterprise system,” IEEE J. Solid-State Circuits, vol. 47, no. 1, pp.
151–163, Jan. 2012.
[3] H. Ando, Y. Yoshida, A. Inoue, I. Sugiyama, T. Asakawa, K. Morita, T. Muta, and T.
Motokurumada, S. Okada, H. Yamashita, and Y. Satsukawa, “A 1.3 GHz fifth generation
SPARC64 microprocessor,” in IEEE ISSCC. Dig. Tech. Papers, Feb. 2003, pp. 246–247.
[4] M. Tremblay and S. Chaudhry, “A third-generation 65nm 16-core 32-thread plus 32-scout-
thread CMT SPARC processor,” in ISSCC. Dig. Tech. Papers, Feb. 2008, pp. 82–83.
[5] AMD Inc. (2010). Family 10h AMD Opteron Processor Product Data Sheet, Sunnyvale, CA,
USA [Online]. Available: http://support.amd.com/us/Processor_TechDocs/40036.pdf
[6] W. Wu, D. Somasekhar, and S.-L. Lu, “Direct compare of information coded with error-
correcting codes,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 20, no. 11, pp. 2147–
2151, Nov. 2012.
[7] S. Lin and D. J. Costello, Error Control Coding: Fundamentals and Applications, 2nd ed.
Englewood Cliffs, NJ, USA: Prentice-Hall, 2004.
[8] Y. Lee, H. Yoo, and I.-C. Park, “6.4Gb/s multi-threaded BCH encoder and decoder for multi-
channel SSD controllers,” in ISSCC Dig. Tech. Papers, 2012, pp. 426–427.](https://image.slidesharecdn.com/low-complexitylow-latencyarchitectureformatching-150323085216-conversion-gate01/85/Low-complexity-low-latency-architecture-for-matching-21-320.jpg)

Low complexity low-latency architecture for matching
- 1. Low-Complexity Low-Latency Architecture for Matching of Data Encoded With Hard Systematic Error-Correcting Codes By Bhavya K V Mtech 1st Sem JSSATE
- 2. Overview Abstract Introduction Decode and Compare architecture Encode and compare architecture Proposed architecture Evaluation Conclusion
- 3. Abstract A new architecture for matching the data, protected with an ECC is presented to reduce latency and complexity. We know that the code word of an ECC is usually represented in a systematic form consisting of the raw data and the parity information generated by encoding. The proposed architecture parallelizes the comparison of the data and that of the parity information. To further reduce the latency and complexity, in addition, a new butterfly-formed weight accumulator (BWA) is proposed for the efficient computation of the Hamming distance.
- 4. Introduction Data comparison is widely used in computing, such as the tag matching in a cache memory and the virtual-to-physical address translation in a translation look aside buffer(TLB). The circuit, therefore, must be designed to have as low latency as possible, or the components will be disqualified, where the overall performance of the whole system would be severely deteriorated.
- 5. Decode and Compare architecture Recent computers employ (ECCs) to protect data and improve reliability that has complicated decoding procedure, which must precede the data comparison, which increases the critical path and complexity.
- 6. Encode and compare architecture Which encodes the incoming data and then compares it with the retrieved data. Therefore, the method eliminates the complex decoding from the critical path. In performing the comparison, the method does not examine whether the retrieved data is exactly the same as the incoming data. Instead, it checks if the retrieved data resides in the error correctable range of the code word corresponding to the incoming data.
- 7. Let tmax and rmax denote the numbers of maximally correctable a detectable errors, respectively. The cases are summarized as follows. 1) If d = 0, X matches Y exactly. 2) If 0 < d <= tmax, X will match Y provided at most tmax errors in Y are corrected. 3) If tmax < d <= rmax, Y has detectable but uncorrectable errors. In this case, the cache may issue a system fault so as to make the central processing unit take a proper action. 4) If rmax < d, X does not match Y.
- 8. To compute the Hamming distance The following half adders (HAs) are used to count the number of 1’s in two adjacent bits in the vector. The numbers of 1’s are accumulated by passing through the following SA tree.
- 9. Disadvantages of encode and compare architecture For the checking necessitates an additional circuit i.e., saturate adder(SA) block are included for calculating the Hamming distance. Effectiveness of a practical ECC code word is usually represented in a systematic form in which the data and parity parts are together with each other. In addition, as the SA always forces its output not to be greater than the number of detectable errors by more than one, it contributes to the increase of the entire circuit complexity.
- 10. Proposed architecture This paper presents a new architecture that can reduce the latency and complexity of the data comparison by using the characteristics of systematic codes. A. Datapath Design for Systematic Codes. B. Architecture for Computing the Hamming Distance. C. General Expressions for the Complexity and the Latency.
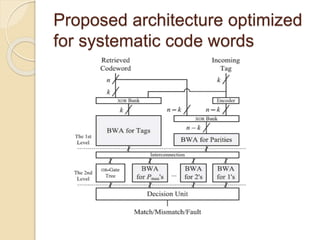
- 11. Datapath Design for Systematic Codes In the SA-based architecture the comparison of two code words is invoked after the incoming tag is encoded. Therefore, the critical path consists of a series of the encoding and the n-bit comparison as shown in Fig.. However this method did not consider the fact that is the ECC code word is of a systematic form in which the data and parity parts are completely separated as shown in Fig.
- 12. As the data part of a systematic code word is exactly the same as the incoming tag field, it is immediately available for comparison while the parity part becomes available only after the encoding is completed. The comparison of the k-bit tags can be started before the remaining (n–k)-bit comparison of the parity bits.
- 13. Proposed architecture optimized for systematic code words
- 14. Architecture for Computing the Hamming Distance The Datapath design contains multiple butterfly- formed weight accumulators (BWAs) proposed to improve the latency and complexity of the Hamming distance computation. The basic function of the BWA is to count the number of 1’s among its input bits. It consists of multiple stages of HAs as shown in Fig a. .
- 15. Since what we need is not the precise Hamming distance but the range it belongs to, it is possible to simplify the circuit. In that case, we can replace several HAs with a simple OR-gate tree as shown in Fig.(b).
- 16. General Expressions for the Complexity and the Latency The complexity of the proposed architecture, C, can be expressed as Where CXOR, CENC, C2nd, CDU, and CBWA(n) are the complexities of XOR banks, an encoder, the second level circuits, the decision unit, and a BWA for n inputs, respectively.
- 17. The latency of the proposed architecture, L, can be expressed as where LXOR, LENC, L2nd, LDU, and LBWA(n) are the latencies of an XOR bank, an encoder, the second level circuits, the decision unit, and a BWA for n inputs, respectively. As one of BWAs at the first level finishes earlier than the other, some components at the second level may start earlier. Similarly, some BWAs or the OR-gate tree at the second level may provide their output earlier to the decision unit so that the unit can begin its operation without waiting for all of its inputs. In such cases, L2nd and LDU can be partially hidden by the critical path of the preceding circuits, and L becomes shorter than the given expression.
- 18. Evaluation For a set of four codes including the (31, 25) code, Table shows the latencies and hardware complexities resulting from three architectures: 1) the conventional decode-and-compare; 2) the SA-based direct compare; and 3) the proposed ones.
- 19. As shown in Table the proposed architecture is effective in reducing the latency as well as the hardware complexity even with considering the practical factors. Latencies of the SA-based architecture and the proposed one are dominated by SAs and HAs, respectively. As the bit-width doubles, at least one more stage of SAs or HAs needs to be added.
- 20. Conclusion The proposed architecture examines whether the incoming data matches the stored data if a certain number of erroneous bits are corrected. To reduce the latency, the comparison of the data is parallelized with the encoding process that generates the parity information. As the proposed architecture is effective in reducing the latency as well as the complexity considerably, it can be regarded as a promising solution for the comparison of ECC-protected data. Though this brief focuses only on the tag match of a cache memory, the proposed method is applicable to applications that need such comparison.
- 21. References [1] J. Chang, M. Huang, J. Shoemaker, J. Benoit, S.-L. Chen, W. Chen, S. Chiu, R. Ganesan, G. Leong, V. Lukka, S. Rusu, and D. Srivastava, “The 65-nm 16-MB shared on-die L3 cache for the dual-core Intel xeon processor 7100 series,” IEEE J. Solid-State Circuits, vol. 42, no. 4, pp. 846– 852, Apr. 2007. [2] J. D. Warnock, Y.-H. Chan, S. M. Carey, H. Wen, P. J. Meaney, G. Gerwig,H. H. Smith, Y. H. Chan, J. Davis, P. Bunce, A. Pelella, D. Rodko, P. Patel, T. Strach, D. Malone, F. Malgioglio, J. Neves, D. L. Rude, and W. V. Huott “Circuit and physical design implementation of the microprocessor chip for the zEnterprise system,” IEEE J. Solid-State Circuits, vol. 47, no. 1, pp. 151–163, Jan. 2012. [3] H. Ando, Y. Yoshida, A. Inoue, I. Sugiyama, T. Asakawa, K. Morita, T. Muta, and T. Motokurumada, S. Okada, H. Yamashita, and Y. Satsukawa, “A 1.3 GHz fifth generation SPARC64 microprocessor,” in IEEE ISSCC. Dig. Tech. Papers, Feb. 2003, pp. 246–247. [4] M. Tremblay and S. Chaudhry, “A third-generation 65nm 16-core 32-thread plus 32-scout- thread CMT SPARC processor,” in ISSCC. Dig. Tech. Papers, Feb. 2008, pp. 82–83. [5] AMD Inc. (2010). Family 10h AMD Opteron Processor Product Data Sheet, Sunnyvale, CA, USA [Online]. Available: http://support.amd.com/us/Processor_TechDocs/40036.pdf [6] W. Wu, D. Somasekhar, and S.-L. Lu, “Direct compare of information coded with error- correcting codes,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 20, no. 11, pp. 2147– 2151, Nov. 2012. [7] S. Lin and D. J. Costello, Error Control Coding: Fundamentals and Applications, 2nd ed. Englewood Cliffs, NJ, USA: Prentice-Hall, 2004. [8] Y. Lee, H. Yoo, and I.-C. Park, “6.4Gb/s multi-threaded BCH encoder and decoder for multi- channel SSD controllers,” in ISSCC Dig. Tech. Papers, 2012, pp. 426–427.
- 22. THANK YOU