pandas: a Foundational Python Library for Data Analysis and Statistics
24 likes60,830 views

Pandas is a Python library for data analysis and manipulation. It provides high performance tools for structured data, including DataFrame objects for tabular data with row and column indexes. Pandas aims to have a clean and consistent API that is both performant and easy to use for tasks like data cleaning, aggregation, reshaping and merging of data.


















![Reshaping
In [5]: df.unstack(’agefrom’).stack(’year’)
Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 20 / 25](https://image.slidesharecdn.com/slides-111118222930-phpapp01/85/pandas-a-Foundational-Python-Library-for-Data-Analysis-and-Statistics-20-320.jpg)





pandas: a Foundational Python Library for Data Analysis and Statistics
- 1. pandas: a Foundational Python library for Data Analysis and Statistics Wes McKinney PyHPC 2011, 18 November 2011 Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 1 / 25
- 2. An alternate title High Performance Structured Data Manipulation in Python Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 2 / 25
- 3. My background Former quant hacker at AQR Capital, now entrepreneur Background: math, statistics, computer science, quant finance. Shaken, not stirred Active in scientific Python community My blog: http://blog.wesmckinney.com Twitter: @wesmckinn Book! “Python for Data Analysis”, to hit the shelves later next year from O’Reilly Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 3 / 25
- 4. Structured data cname year agefrom ageto ls lsc pop ccode 0 Australia 1950 15 19 64.3 15.4 558 AUS 1 Australia 1950 20 24 48.4 26.4 645 AUS 2 Australia 1950 25 29 47.9 26.2 681 AUS 3 Australia 1950 30 34 44 23.8 614 AUS 4 Australia 1950 35 39 42.1 21.9 625 AUS 5 Australia 1950 40 44 38.9 20.1 555 AUS 6 Australia 1950 45 49 34 16.9 491 AUS 7 Australia 1950 50 54 29.6 14.6 439 AUS 8 Australia 1950 55 59 28 12.9 408 AUS 9 Australia 1950 60 64 26.3 12.1 356 AUS Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 4 / 25
- 5. Structured data A familiar data model Heterogeneous columns or hyperslabs Each column/hyperslab is homogeneously typed Relational databases (SQL, etc.) are just a special case Need good performance in row- and column-oriented operations Support for axis metadata Data alignment is critical Seamless integration with Python data structures and NumPy Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 5 / 25
- 6. Structured data challenges Table modification: column insertion/deletion Axis indexing and data alignment Aggregation and transformation by group (“group by”) Missing data handling Pivoting and reshaping Merging and joining Time series-specific manipulations Fast IO: flat files, databases, HDF5, ... Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 6 / 25
- 7. Not all fun and games We care nearly equally about Performance Ease-of-use (syntax / API fits your mental model) Expressiveness Clean, consistent API design is hard and underappreciated Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 7 / 25
- 8. The big picture Build a foundation for data analysis and statistical computing Craft the most expressive / flexible in-memory data manipulation tool in any language Preferably also one of the fastest, too Vastly simplify the data preparation, munging, and integration process Comfortable abstractions: master data-fu without needing to be a computer scientist Later: extend API with distributed computing backend for larger-than-memory datasets Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 8 / 25
- 9. pandas: a brief history Starting building April 2008 back at AQR Open-sourced (BSD license) mid-2009 29075 lines of Python/Cython code as of yesterday, and growing fast Heavily tested, being used by many companies (inc. lots of financial firms) in production Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 9 / 25
- 10. Cython: getting good performance My choice tool for writing performant code High level access to NumPy C API internals Buffer syntax/protocol abstracts away striding details of non-contiguous arrays, very low overhead vs. working with raw C pointers Reduce/remove interpreter overhead associated with working with Python data structures Interface directly with C/C++ code when necessary Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 10 / 25
- 11. Axis indexing Key pandas feature The axis index is a data structure itself, which can be customized to support things like: 1-1 O(1) indexing with hashable Python objects Datetime indexing for time series data Hierarchical (multi-level) indexing Use Python dict to support O(1) lookups and O(n) realignment ops. Can specialize to get better performance and memory usage Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 11 / 25
- 12. Axis indexing Every axis has an index Automatic alignment between differently-indexed objects: makes it nearly impossible to accidentally combine misaligned data Hierarchical indexing provides an intuitive way of structuring and working with higher-dimensional data Natural way of expressing “group by” and join-type operations As good or in many cases much more integrated/flexible than commercial or open-source alternatives to pandas/Python Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 12 / 25
- 13. The trouble with Python dicts... Python dict memory footprint can be quite large 1MM key-value pairs: something like 70mb on a 64-bit system Even though sizeof(PyObject*) == 8 Python dict is great, but should use a faster, threadsafe hash table for primitive C types (like 64-bit integer) BUT: using a hash table only necessary in the general case. With monotonic indexes you don’t need one for realignment ops Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 13 / 25
- 14. Some alignment numbers Hardware: Macbook Pro Core i7 laptop, Python 2.7.2 Outer-join 500k-length indexes chosen from 1MM elements Dict-based with random strings: 2.2 seconds Sorted strings: 400ms (5.5x faster) Sorted int64: 19ms (115x faster) Fortunately, time series data falls into this last category Alignment ops with C primitives could be fairly easily parallelized with OpenMP in Cython Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 14 / 25
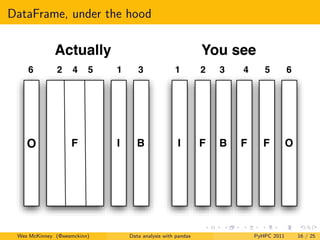
- 15. DataFrame, the pandas workhorse A 2D tabular data structure with row and column indexes Hierarchical indexing one way to support higher-dimensional data in a lower-dimensional structure Simplified NumPy type system: float, int, boolean, object Rich indexing operations, SQL-like join/merges, etc. Support heterogeneous columns WITHOUT sacrificing performance in the homogeneous (e.g. floating point only) case Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 15 / 25
- 16. DataFrame, under the hood Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 16 / 25
- 17. Supporting size mutability In order to have good row-oriented performance, need to store like-typed columns in a single ndarray “Column” insertion: accumulate 1 × N × . . . homogeneous columns, later consolidate with other like-typed into a single block I.e. avoid reallocate-copy or array concatenation steps as long as possible Column deletions can be no-copy events (since ndarrays support views) Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 17 / 25
- 18. Hierarchical indexing New this year, but really should have done long ago Natural result of multi-key groupby An intuitive way to work with higher-dimensional data Much less ad hoc way of expressing reshaping operations Once you have it, things like Excel-style pivot tables just “fall out” Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 18 / 25
- 19. Reshaping Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 19 / 25
- 20. Reshaping In [5]: df.unstack(’agefrom’).stack(’year’) Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 20 / 25
- 21. Reshaping implementation nuances Must deal with unbalanced group sizes / missing data Play vectorization tricks with the NumPy C-contiguous memory layout: no Python for loops allowed Care must be taken to handle heterogeneous and homogeneous data cases Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 21 / 25
- 22. GroupBy High level process split data set into groups apply function to each group (an aggregation or a transformation) combine results intelligently into a result data structure Can be used to emulate SQL GROUP BY operations Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 22 / 25
- 23. GroupBy Grouping closely related to indexing Create correspondence between axis labels and group labels using one of: Array of group labels (like a DataFrame column) Python function to be applied to each axis tick Can group by multiple keys For a hierarchically indexed axis, can select a level and group by that (or some transformation thereof) Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 23 / 25
- 24. GroupBy implementation challenges Computing the group labels from arbitrary Python objects is very expensive 77ms for 1MM strings with 1K groups 107ms for 1MM strings with 10K groups 350ms for 1MM strings with 100K groups To sort or not to sort (for iteration)? Once you have the labels, can reorder the data set in O(n) (with a much smaller constant than computing the labels) Roughly 35ms to reorder 1MM float64 data points given the labels (By contrast, computing the mean of 1MM elements takes 1.4ms) Python function call overhead is significant in cases with lots of small groups; much better (orders of magnitude speedup) to write specialized Cython routines Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 24 / 25
- 25. Demo, time permitting Wes McKinney (@wesmckinn) Data analysis with pandas PyHPC 2011 25 / 25