[Paper introduction] Performance Capture of Interacting Characters with Handheld Kinects
Download as PPTX, PDF0 likes390 views

This document summarizes a paper that presents a method for capturing full performance of interacting characters using only 3 handheld Kinect sensors. The method reconstructs a skeleton motion and time-varying surface geometry of humans from the asynchronous and uncalibrated Kinect sensor data. It matches geometric data from the Kinects to a human body model and optimizes the skeleton poses and camera parameters. Non-rigid deformations of the human surface are estimated through Laplacian deformation. The method is shown to capture complex motions with self-occlusions better than traditional multi-camera motion capture systems.






![Scene models at time t
• Human model
– Laser scanner provide a static mesh with embedded
skeleton of each performer
[*]
• 5,000 vertices of meshes
• k-th performer’s Skeleton with
31 degrees of freedom: C tk
GND (r=3m)
• Ground plane model (fixed)
– Center of Environment
– Planar mesh with circular boundary
• Camera extrinsic parameters of i-th Kinect
– Translation, rotation: L tk
7
[*] F. Remondino: “3-D reconstruction of static human body shape from image sequence,” CVIU, Vol.93, No.1. pp.65-85](https://image.slidesharecdn.com/nakazawaeccvintrover1-121208205029-phpapp02/85/Paper-introduction-Performance-Capture-of-Interacting-Characters-with-Handheld-Kinects-7-320.jpg)





[Paper introduction] Performance Capture of Interacting Characters with Handheld Kinects
- 1. Notice • This power point is made by Mitsuru Nakazawa, NOT an original author, for paper introduction of ECCV2012 1
- 2. Presenter: Mitsuru NAKAZAWA Performance Capture of Interacting Characters with Handheld Kinects Genzhi Ye1 Yebin Liu1 Nils Hasler2 Xiangyang Ji1 Qionghai Dai1 Christian Theobalt2 1: Deptartment of Automation, Tsinghua University 2: Graphics, Vision & Video Group, Max-Planck Institute for Informatics ECCV2012 paper introduction 2
- 3. Introduction movie URL: http://media.au.tsinghua.edu.cn/yegenzhi/HandheldKinectsMocap_ECCV2012.jsp (Accessed on 26th Nov. 2012) 3
- 4. Related works Multi-view motion capture approaches Reconstruct a skeletal motion model & detailed dynamic surface geometry Deal with people wide apparel Require controlled studio setup (many number of sync video cameras) Marker-less motion capture from a single range sensor Estimate complex poses at real-time frame rates Difficult to capture 3D, complex, detailed model 4
- 5. Objective freely move Full performance capture Operator of moving humans using only 3 handheld, Performer moving Kinects Reconstruct a skeleton motion & time varying surface geometry of humans in general apparel Handle fast and complex motion with many self- occlusions & non-rid surface deformation Not need studios with controlled lighting and many stationary cameras 5
- 6. Data capture Operator Performer Capture environment Captured data from 3 Kinects Asynchronous capture Use a start recording signal to all PCs connected through Wi-Fi Intrinsic calibration Apply Zhang’s method Alignment between the color image and the range data Use the OpenNI API 6
- 7. Scene models at time t • Human model – Laser scanner provide a static mesh with embedded skeleton of each performer [*] • 5,000 vertices of meshes • k-th performer’s Skeleton with 31 degrees of freedom: C tk GND (r=3m) • Ground plane model (fixed) – Center of Environment – Planar mesh with circular boundary • Camera extrinsic parameters of i-th Kinect – Translation, rotation: L tk 7 [*] F. Remondino: “3-D reconstruction of static human body shape from image sequence,” CVIU, Vol.93, No.1. pp.65-85
- 8. Overview of the proposed method at time t Geometric matching of Kinect point to Point Could Segmentation vertices of a human model Optimization of skeleton & camera pose Non-rigid deformation of the human surface via Laplacian deformation 8
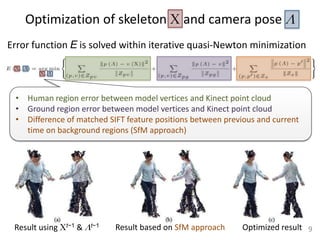
- 9. Optimization of skeleton and camera pose Error function E is solved within iterative quasi-Newton minimization • Human region error between model vertices and Kinect point cloud • Ground region error between model vertices and Kinect point cloud • Difference of matched SIFT feature positions between previous and current time on background regions (SfM approach) Result using t−1 & t−1 Result based on SfM approach Optimized result 9
- 10. Comparison with Multi-view Video Tracking Multi-view video trachking system with 10 calibrated cameras vs. Proposed method “Rolling” with slow motion Similar results “Jump” with fast motion proposed method gets better results 10
- 11. Performance capture results on a variety of Sequences 11
- 12. Conclusion • Simultaneously marker-less performance capture system with several hand-held Kinects – Iterative robust matching of tracked 3D models and input Kinect data 12
- 13. References • Linear Blend Skinning (Accessed on Nov. 25th 2012 ) – http://bit.ly/RaijkQ • Motion Capture Using Joint Skeleton Tracking and Surface Estimation (Accessed on Nov. 26th 2012) – http://www.vision.ee.ethz.ch/~gallju/projects/skelsurf/ind ex.html 13