




































Scalable gradientbasedtuningcontinuousregularizationhyperparameters ppt
- 1. Scalable Gradient-Based Tuning of Continuous Regularization Hyperparameters ICML 2016 1 citations Jelena Luketina Aalto University, Finland Mathias Berglund Aalto University, Finland Klaus Greff The Swiss AI Lab, Switzerland Tapani Raiko Aalto University, Finland
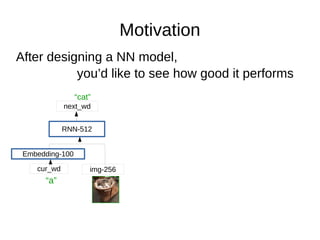
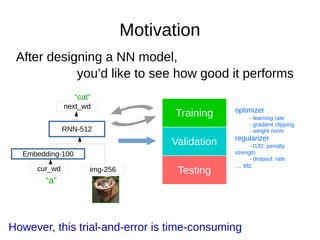
- 2. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat”
- 3. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” However, there’re many hyperparameters for training optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc
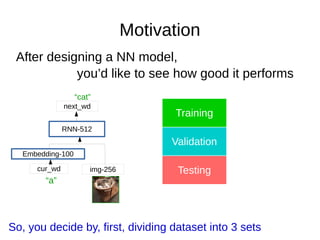
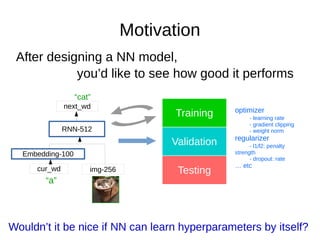
- 4. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing So, you decide by, first, dividing dataset into 3 sets
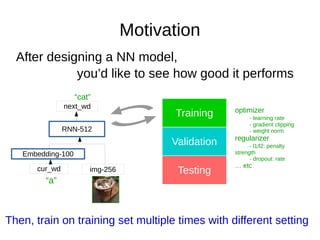
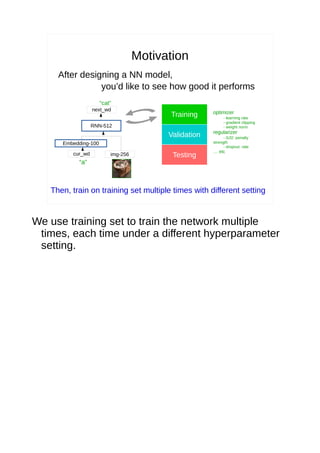
- 5. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing Then, train on training set multiple times with different setting optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc
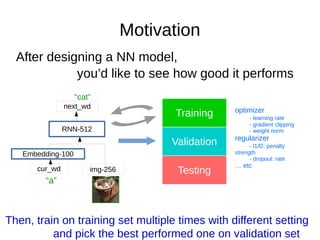
- 6. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing and pick the best performed one on validation set Then, train on training set multiple times with different setting optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc
- 7. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing However, this trial-and-error is time-consuming optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc
- 8. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing Wouldn’t it be nice if NN can learn hyperparameters by itself? optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc
- 9. Problem Formulation ● Suppose objective function where is the model parameter, and is regularization hyperparameters ● How to learn as well as during training?
- 10. Algorithm model parameter update regularization hyperameter fixed model parameter fixed regularization hyperameter update ● Take turns to descend model parameter and regularization hyperparameter
- 12. Algorithm ● training objective ● validation objective
- 13. Algorithm ● training objective ● validation objective ● model parameter update
- 14. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update
- 15. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update
- 16. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update
- 17. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update
- 18. Experiment (1/4) ● Regularization – noise injection ● to input by Gaussian noise with std ● to each hidden layer by Gaussian noise with std – L2 penalty ● on each hidden layer with strength
- 19. Experiment (1/4) ● Hyperparameter trajectory
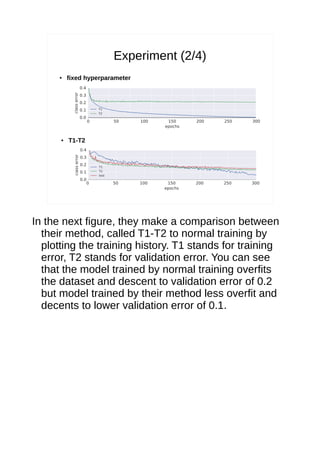
- 20. Experiment (2/4) ● fixed hyperparameter ● T1-T2
- 21. Experiment (3/4) ● T1-T2 as meta-algorithm
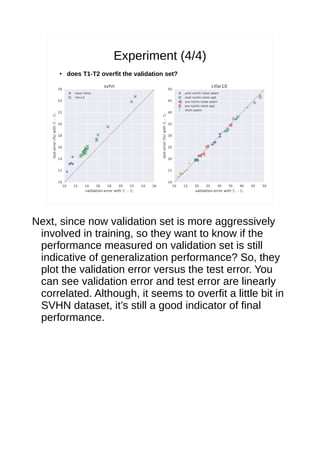
- 22. Experiment (4/4) ● does T1-T2 overfit the validation set?
- 23. Conclusion ● Introduce a novel and significant topic and the method makes intuitive totally sense
- 24. Scalable Gradient-Based Tuning of Continuous Regularization Hyperparameters ICML 2016 1 citations Jelena Luketina Aalto University, Finland Mathias Berglund Aalto University, Finland Klaus Greff The Swiss AI Lab, Switzerland Tapani Raiko Aalto University, Finland Today I’m gonna present a paper called …. It’s published on last track of ICML, and so far has 1 citation count. From the title, you can expect that this is a paper that aims to boost the hyperparameter selecting procedure of neural network.
- 25. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Let me give a motivative example to show you why boosting the hyperparameter selecting procedure is an important thing. Suppose now, you’ve designed a neural network model. For example, for task of image-captioning, you’re given an image and have to output a sentence to describe that image. Then you may want to try a model like this. So, after deciding a model, the next thing is to evaluate how good it performs.
- 26. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” However, there’re many hyperparameters for training optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc So, you start training your model, however, there’re so many hyperparameters to decide. For example, we’ll use iterative learning process like SGD to train the network, then you’d have decide the learning rate and most of time for RNN we’ll use additional techniques like gradient clipping or weight norm constraints to prevent sudden error shooting, then you’d have to decide the clipping threshold. And if you observe the network is overfitting the data, then you might want to use some regularizer, like adding l1 or l2 penalty terms to objective function, or chage the dropout rate of your model and so on. So, in order to evaluate if it’s a good model, there’re so many determining hyperparameters for a successful training, and totally they’ll make an exponentially large number of combinations to try.
- 27. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing So, you decide by, first, dividing dataset into 3 sets Unfortunately, currently there’re no good algorithm to find hyperparameter, mostly we’ll use brute-force algorithm like grid search or come out some candidate hyperparameters by ourself. In either way, we’ll pick the best combination by a procedure called cross-validation. Cross-Validation goes like this, first, we divide the dataset into 3 sets, training set, validation set and test set
- 28. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing Then, train on training set multiple times with different setting optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc We use training set to train the network multiple times, each time under a different hyperparameter setting.
- 29. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing and pick the best performed one on validation set Then, train on training set multiple times with different setting optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc At the end of each training round, the model is evaluated on validation set. So, the combination which has the best performance on validation set is our best hyperparameter.
- 30. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing However, this trial-and-error is time-consuming optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc But, the hyperparameter selecting procedure requires multiple full-training rounds. It’s very inefficient and time-consuming. It only works fine when you have some experience or good intuitions to make the exploration space small.
- 31. Motivation After designing a NN model, you’d like to see how good it performs Embedding-100 img-256cur_wd RNN-512 next_wd “a” “cat” Training Validation Testing Wouldn’t it be nice if NN can learn hyperparameters by itself? optimizer - learning rate - gradient clipping - weight norm regularizer - l1/l2: penalty strength - dropout: rate … etc So, wouldn’t it be nice, if we can make the network learn those training hyperparameters by itself?
- 32. Problem Formulation ● Suppose objective function where is the model parameter, and is regularization hyperparameters ● How to learn as well as during training? Let’s define the problem formally. Suppose our objective function is C, and we add regularization terms Omega to penalizes on model parameter theta and the penalty strength is controlled by lambda. Normally, we only learn theta and keep lambda fixed during a training round. So, now the problem is how could we learn both of them simultaneously? You might wonder there’re so many kinds of hyperparameters, why this paper only target at regularization hyperparameters. It’s because for regularization hyperparameters, you can clearly write down its from in objective function, so it’s the easiest one to solve.
- 33. Algorithm model parameter update regularization hyperameter fixed model parameter fixed regularization hyperameter update ● Take turns to descend model parameter and regularization hyperparameter Their method is intuitively straightforward. The model parameter and hyperparameter take turns to descent. For model parameter descending phase, the regularization hyperparameter is kept fixed. And for hyperparameter descending phase, the model parameter is fixed. But there’s one thing to note is that the objective of the two descending phase is different.
- 34. Algorithm ● training objective This is our normal training objective for descending model parameter, it’s a regularized one measured on training set.
- 35. Algorithm ● training objective ● validation objective But for hyperparameter descending phase, we measure the performance on validation set, and there’s no need to add the regularized terms, since the model parameter is fixed. So, the validation objective is a unregularized objective.
- 36. Algorithm ● training objective ● validation objective ● model parameter update We trained the model by SGD. The model parameter update is the same as usual, take the gradient of training objective respect to theta, then descent a step size of eta.
- 37. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update After each model parameter update, we update the regularization hyperparameter. So, we take the gradient of validation objective repect to lambda.
- 38. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update Since there’re no explictly penalty terms in validation objective, lamda in deed only appears in theta in the model parameter update.
- 39. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update We use chain rule to expand gradient, we first take the gradient of validation objective repect to theta, and then multiply by the gradient of theta repect to lamda.
- 40. Algorithm ● training objective ● validation objective ● model parameter update ● regularization hyperparameter update Lamda only appears in the gradient of model parameter update, so you can further simplify the formula.
- 41. Experiment (1/4) ● Regularization – noise injection ● to input by Gaussian noise with std ● to each hidden layer by Gaussian noise with std – L2 penalty ● on each hidden layer with strength In their experiment, they use 2 kinds of regularization, one is noise injection with Gaussian noise to inputs of each hidden layer. You might wonder why adding noise to input introduces regularization terms in objective function. You can think this way, if you define original objective function as the one that’s measure on original clean input, then the penalty terms is difference between the cost measure on noise input and the cost of clean input. And the second regularizer used in their experiment is the l2 norm penalty, separately penalize on the parameter of each layer.
- 42. Experiment (1/4) ● Hyperparameter trajectory The first figure shown is the training trajectory of hyperparameters respect to the background, test negative log likelihood in different color, the larger the better. And the points mark in start represents the starting point of values of regularization hyperparameters before training, and square mark represents the end points after training. You can see by using their method, the regularization hyperparameter gradually move toward better points.
- 43. Experiment (2/4) ● fixed hyperparameter ● T1-T2 In the next figure, they make a comparison between their method, called T1-T2 to normal training by plotting the training history. T1 stands for training error, T2 stands for validation error. You can see that the model trained by normal training overfits the dataset and descent to validation error of 0.2 but model trained by their method less overfit and decents to lower validation error of 0.1.
- 44. Experiment (3/4) ● T1-T2 as meta-algorithm They want to answer the question: in normal training, we assume hyperparameter to be fixed, they want to know does their method which changes hyperparameters along the way has any negative effect at final performance? So, they do experiment by first running their T1-T2 method, then use the values found by T1-T2 to rerun a fixed- hyperparameter experiment. This experiment is run on CIFAR-10, x-axis represents the test error of their method, and y-axis represent the test error of the rerun experiment. The result is yes, there’s slightly negative effect since the test error of rerun experiment is better. So, they make a conclusion that their method can be used as a meta-algorithm to find a good hyperparemter for normal training.
- 45. Experiment (4/4) ● does T1-T2 overfit the validation set? Next, since now validation set is more aggressively involved in training, so they want to know if the performance measured on validation set is still indicative of generalization performance? So, they plot the validation error versus the test error. You can see validation error and test error are linearly correlated. Although, it seems to overfit a little bit in SVHN dataset, it’s still a good indicator of final performance.
- 46. Conclusion ● Introduce a novel and significant topic and the method makes intuitive totally sense