Scaling python to_hpc_big_data-maidanov

This document discusses scaling Python to HPC and big data environments. It describes how Intel provides Python distributions to improve performance and parallelism. Key points include: - Intel distributions optimize Python packages like NumPy and SciPy with Intel MKL to improve performance of dense and sparse linear algebra operations. - Composable multi-threading is supported using Intel TBB to better balance workloads across CPU threads. - Intel DAAL provides optimized algorithms for machine learning in scikit-learn to accelerate tasks like PCA. The document outlines techniques Intel uses to make Python more suitable for high performance and big data computing through parallelism, optimized libraries, and integration with frameworks like Spark and TensorFlow.




















Scaling python to_hpc_big_data-maidanov
- 2. Scaling Out Python* To HPC and Big Data Sergey Maidanov Software Engineering Manager for Intel® Distribution for Python*
- 3. What Problems We Solve: Scalable Performance Make Python usable beyond prototyping environment by scaling out to HPC and Big Data environments
- 4. What Problems We Solve: Ease of Use 4 “Any articles I found on your site that related to actually using the MKL for compiling something were overly technical. I couldn't figure out what the heck some of the things were doing or talking about.“ – Intel® Parallel Studio 2015 Beta Survey Response https://software.intel.com/en-us/forums/intel-math-kernel-library/topic/280832 https://software.intel.com/en-us/articles/building-numpyscipy-with-intel-mkl-and-intel-fortran-on-windows https://software.intel.com/en-us/articles/numpyscipy-with-intel-mkl
- 5. Why Yet Another Python Distribution? Intel® Xeon® Processors Intel® Xeon Phi™ Product Family Configuration Info: apt/atlas: installed with apt-get, Ubuntu 16.10, python 3.5.2, numpy 1.11.0, scipy 0.17.0; pip/openblas: installed with pip, Ubuntu 16.10, python 3.5.2, numpy 1.11.1, scipy 0.18.0; Intel Python: Intel Distribution for Python 2017;. Hardware: Xeon: Intel Xeon CPU E5-2698 v3 @ 2.30 GHz (2 sockets, 16 cores each, HT=off), 64 GB of RAM, 8 DIMMS of 8GB@2133MHz; Xeon Phi: Intel Intel® Xeon Phi™ CPU 7210 1.30 GHz, 96 GB of RAM, 6 DIMMS of 16GB@1200MHz Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 . Mature AVX2 instructions based product New AVX512 instructions based product
- 6. Scaling To HPC & Big Data Environments • Hardware and software efficiency crucial in production (Perf/Watt, etc.) • Efficiency = Parallelism – Instruction Level Parallelism with effective memory access patterns – SIMD – Multi-threading – Multi-node Roofline Performance Model* Arithmetic Intensity SpMVBLAS1 Stencils FFT BLAS3 Particle Methods Low High Gflop/s Peak Gflop/s * Roofline Performance Model https://crd.lbl.gov/departments/computer-science/PAR/research/roofline/
- 7. Efficiency = Parallelism and Python? • CPython as interpreter inhibits parallelism but… • … Overall Python tools evolved far toward unlocking parallelism Native extensions numpy*, scipy*, scikit- learn* accelerated with Intel® MKL, Intel® DAAL, Intel® IPP Composable multi- threading with Intel® TBB and Dask* Multi-node parallelism with mpi4py* accelerated with Intel® MPI* Language extensions for vectorization & multi-threading (Cython*, Numba*) Integration with Big Data platforms and Machine Learning frameworks (pySpark*, Theano*, TensorFlow*, etc.) Mixed language profiling with Intel® VTune™ Amplifier
- 8. Composable Multi-Threading With Intel® TBB • Amhdal’s law suggests extracting parallelism at all levels • If software components do not coordinate on threads use it may lead to oversubscription • Intel TBB dynamically balances HW thread loads and effectively manages oversubscription • Intel engineers extended Cpython* and Numba* thread pools with support of Intel® TBB >python –m TBB myapp.py Application Component 1 Component N Subcomponent 1 Subcomponent 2 Subcomponent K Subcomponent 1 Subcomponent M Subcomponent 1 Subcomponent 1 Subcomponent 1 Subcomponent 1 Subcomponent 1 Subcomponent 1 Subcomponent 1 Subcomponent 1 MKL TBB DAAL pyDAAL NumPy SciPy TBB Joblib Dask Application PythonpackagesNativelibs
- 9. Composable Multi-Threading Example: Batch QR Performance Numpy 1.00x Numpy 0.22x Numpy 0.47x Dask 0.61x Dask 0.89x Dask 1.46x 0.0x 0.2x 0.4x 0.6x 0.8x 1.0x 1.2x 1.4x Default MKL Serial MKL Intel® TBB Speedup relative to Default Numpy* Intel® MKL, OpenMP* threading Intel® MKL, Serial Intel® MKL, Intel® TBB threading Over- subscription App-level parallelism only TBB- composable nested parallelism System info: 32x Intel(R) Xeon(R) CPU E5-2698 v3 @ 2.30GHz, disabled HT, 64GB RAM; Intel(R) MKL 2017.0 Beta Update 1 Intel(R) 64 architecture, Intel(R) AVX2; Intel(R)TBB 4.4.4; Ubuntu 14.04.4 LTS; Dask 0.10.0; Numpy 1.11.0. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 .
- 10. NumPy* and SciPy* Continuous Improvement • MKL-level performance for dense linear algebra and FFT • NumPy random, umath & NumExpr* exploit SIMD and multi-threading out-of-the-box • Better memory allocation and copy in NumPy 0 10 20 30 40 50 1024 2048 4096 8192 16384 AxisTitle Black Scholes Formula NumPy* umath scalability Numpy - U1+TBB Numpy - U1-opt+TBB Intel Python 2017U1 Intel Python 2017U1.1 4X See system configuration details on the next slide MOPS Does not scale beyond 16K options
- 11. NumExpr* Scalability: Black-Scholes Formula System info: 32x Intel® Xeon® CPU E5-2698 v3 @ 2.30GHz, disabled HT, 64GB RAM; Intel® Distribution for Python* 2017 Update Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 . 0 100 200 300 400 500 600 700 800 900 1024 2048 4096 8192 16384 32768 65536 131072 262144 524288 1048576 2097152 4194304 8388608 16777216 33554432 67108864 MOPS Black-Scoles Formula with NumExpr* What’s a magic?
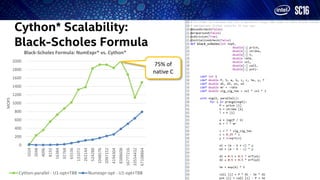
- 12. Cython* Scalability: Black-Scholes Formula 0 200 400 600 800 1000 1200 1400 1600 1800 2000 1024 2048 4096 8192 16384 32768 65536 131072 262144 524288 1048576 2097152 4194304 8388608 16777216 33554432 67108864 MOPS Black-Scholes Formula: NumExpr* vs. Cython* Cython-parallel - U1-opt+TBB Numexpr-opt - U1-opt+TBB 75% of native C
- 13. Skt-Learn* Optimizations With Intel® MKL... And Intel® DAAL 0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Approximate neighbors Fast K-means GLM GLM net LASSO Lasso path Least angle regression, OpenMP Non-negative matrix factorization Regression by SGD Sampling without replacement SVD Speedups of Scikit-Learn Benchmarks Intel® Distribution for Python* 2017 Update 1 vs. system Python & NumPy/Scikit-Learn System info: 32x Intel® Xeon® CPU E5-2698 v3 @ 2.30GHz, disabled HT, 64GB RAM; Intel® Distribution for Python* 2017 Gold; Intel® MKL 2017.0.0; Ubuntu 14.04.4 LTS; Numpy 1.11.1; scikit-learn 0.17.1. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 . Effect of Intel MKL optimizations for NumPy* and SciPy* 1 1.11 54.13 0x 10x 20x 30x 40x 50x 60x System Sklearn Intel SKlearn Intel PyDAAL Speedup Potential Speedup of Scikit-learn* due to PyDAAL PCA, 1M Samples, 200 Features Effect of DAAL optimizations for Scikit-Learn* Intel® Distribution for Python* ships Intel® Data Analytics Acceleration Library with Python interfaces, a.k.a. pyDAAL
- 14. Ideas Behind Intel® DAAL: Heterogeneous Analytics • Data is different, data analytics pipeline is the same • Data transfer between devices is costly, protocols are different – Need data analysis proximity to Data Source – Need data analysis proximity to Client – Data Source device ≠ Client device – Requires abstraction from communication protocols Pre-processing Transformation Analysis Modeling Decision Making Decompression, Filtering, Normalization Aggregation, Dimension Reduction Summary Statistics Clustering, etc. Machine Learning (Training) Parameter Estimation Simulation Forecasting Decision Trees, etc. Scientific/Engineering Web/Social Business Compute (Server, Desktop, … ) Client EdgeData Source Edge Validation Hypothesis testing Model errors
- 15. Ideas Behind Intel® DAAL: Effective Data Management, Streaming and Distributed Processing … Observations, n Time Memory Capacity Categorical Blank/Missing Numeric Features,p Big Data Attributes Computational Solution Distributed across different devices •Distributed processing with communication-avoiding algorithms Huge data size not fitting into device memory •Distributed processing •Streaming algorithms Data coming in time •Data buffering & asynchronous computing •Streaming algorithms Non-homogeneous data •CategoricalNumeric (counters, histograms, etc) •Homogeneous numeric data kernels • Conversions, Indexing, Repacking Sparse/Missing/Noisy data •Sparse data algorithms •Recovery methods (bootstrapping, outlier correction) Outlier
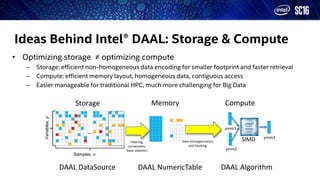
- 16. Ideas Behind Intel® DAAL: Storage & Compute • Optimizing storage ≠ optimizing compute – Storage: efficient non-homogeneous data encoding for smaller footprint and faster retrieval – Compute: efficient memory layout, homogeneous data, contiguous access – Easier manageable for traditional HPC, much more challenging for Big Data … Samples, n Variables,p Storage ComputeMemory Filtering, conversions, basic statistics Data homogenization and blocking DAAL DataSource DAAL NumericTable DAAL Algorithm SIMD ymm1 ymm3 ymm2
- 17. Ideas Behind Intel® DAAL: Languages & Platforms DAAL has multiple programming language bindings • C++ – ultimate performance for real-time analytics with DAAL • Java*/Scala* – easy integration with Big Data platforms (Hadoop*, Spark*, etc) • Python* – advanced analytics for data scientist
- 18. 50% 60% 70% 80% 90% 100% 110% 120% 130% pyDAAL (Offline) pyDAAL (Offline+Basic Statistics) pyDAAL (Online) 10% faster if basic statistics pre-computed while reading dataset 25% incremental cost for streaming computing support Ex 1. Compute Basic Statistics While Reading Dataset Ex 2. Offline vs. Online • 𝑐𝑜𝑣 𝑋, 𝑌 = 𝐸((𝑋 − 𝐸 𝑋 )(𝑌 − 𝐸 𝑌 ) • Algorithm: Maximum Likelihood Estimator • Dataset: CSV file n=1M, p=100 … Samples, n Variables,p Storage ComputeMemory Basic statistics Data blocking SIMD ymm1 ymm3 ymm2 System Info: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz, 504GB, 2x24 cores, HT=on, OS RH7.2 x86_64, Intel Distribution for Python 2017 Update 1 (Python 3.5) Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 . Better memory management in pyDAAL allows bigger datasets even for offline processing • Ex.: Scikit-learn fails to process n=50M, p=1000 while pyDAAL successfully completes work Online processing removes dataset size limitation
- 19. Ex 3: Read vs. Compute • Algorithm: SVM Classification with RBF kernel • Training dataset: CSV file (PCA-preprocessed MNIST, 40 principal components) n=42000, p=40 • Testing dataset: CSV file (PCA-preprocessed MNIST, 40 principal components) n=28000, p=40 System Info: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz, 504GB, 2x24 cores, HT=on, OS RH7.2 x86_64, Intel Distribution for Python 2017 Update 1 (Python 3.5) Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 . 0 5 10 15 20 25 Scikit-Learn, Pandas pyDAAL Training (sec) Read Training Dataset (incl. labels) Training Compute 0 5 10 15 20 25 Scikit-Learn, Pandas pyDAAL Prediction (sec) Read Test Dataset Prediction Compute 60% faster CVS file read, 2.2x faster training 66x faster prediction in pyDAAL. Read and compute balanced
- 20. Distributed Parallelism • Intel® MPI* accelerates Intel® Distribution for Python (mpi4py*, ipyparallel*) • Intel Distribution for Python also supports – PySpark* - Python* interfaces for Spark*, an engine for large-scale data processing – Dask* - flexible parallel computing library for numerical computing 1.7x 2.2x 3.0x 5.3x 0x 1x 2x 3x 4x 5x 6x 2 nodes 4 nodes 8 nodes 16 nodes PyDAAL Implicit ALS with Mpi4Py* Scales with MPI, Spark, Dask and other distributed computing engines Configuration Info: Hardware (each node): Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30GHz, 2x18 cores, HT is ON, RAM 128GB; Versions: Oracle Linux Server 6.6, Intel® DAAL 2017 Gold, Intel® MPI 5.1.3; Interconnect: 1 GB Ethernet. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 .
- 21. Summary And Call To Action • Intel created the Python* distribution for out-of-the-box performance and scalability on Intel® Architecture – With minimum to no code modification Python aims to scale • Multiple technologies applied to unlock parallelism at all levels – Numerical libraries, libraries for parallelism, Python code compilation/JITing, profiling – Enhancing mature Python packages and bringing new technologies, e.g. pyDAAL, TBB • With multiple choices available Python developer needs to be conscious what will scale best – Intel® VTune™ Amplifier helps making conscious decisions Intel Distribution for Python is free! https://software.intel.com/en-us/intel-distribution-for-python Commercial support included for Intel® Parallel Studio XE customers! Easy to install with Anaconda* https://anaconda.org/intel/