Semantics-aware Techniques for Social Media Analysis, User Modeling and Recommender Systems - Tutorial @UMAP 2016
4 likes1,167 views

This document provides an overview and agenda for a tutorial on semantics-aware techniques for social media analysis, user modeling, and recommender systems. The tutorial will discuss how to represent content to improve information access and build new services for social media. It will cover why intelligent information access is needed to effectively cope with information overload, and how semantics can be introduced through natural language processing and by encoding endogenous and exogenous semantics. The agenda includes explaining recommendations, semantic user profiles based on social data, and semantic analysis of social streams.




















































![Information Retrieval and Filtering
Two sides of the same coin (Belkin&Croft,1992)
Information
Retrieval
information need expressed
through a query
goal: retrieve information which
might be relevantto a
user
Information
Filtering
information need expressed
through a
user profile
goal: expose users to only the
information that is
relevantto them,
according to personal profiles
[Belkin&Croft, 1992] Belkin, Nicholas J., and W. Bruce Croft.
"Information filtering and information retrieval: Two sides of the same
coin?." Communications of the ACM 35.12 (1992): 29-38.
It’s all about searching!](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-53-320.jpg)












































![Sense Repository
WordNet groups words into sets of synonyms called synsets
It contains nouns, verbs, adjectives, adverbs
Word
Meanings
Word Forms
F1 F2 F3 … … Fn
M1 V(1,1) V(2,1)
M2 V(2,2) V(3,2)
M3
M…
Mm V(m,n)
Synonym
word forms
(synset)
polysemous word:
disambiguation needed
WordNet linguistic ontology [*]
[*] Miller, George A. "WordNet: a lexical database for
English." Communications of the ACM 38.11 (1995): 39-41.](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-99-320.jpg)


![Word Sense Disambiguation
State of the art: JIGSAW algorithm [*]
Input
o D = {w1, w2, …. , wh} document
Output
o X = {s1, s2, …. , sk} (kh)
Each si obtained by disambiguating wi based on the context
of each word
Some words not recognized by WordNet
Groups of words recognized as a single concept
[*] Basile, P., de Gemmis, M., Gentile, A. L., Lops, P., & Semeraro, G. (2007, June). UNIBA:
JIGSAW algorithm for word sense disambiguation. InProceedings of the 4th International
Workshop on Semantic Evaluations (pp. 398-401). Association for Computational Linguistics.](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-102-320.jpg)


































































































![Explicit Semantic Analysis (ESA)
ESA builds a vector-space
semantic
representation
of natural language texts in a
high-dimensional space of
comprehensible
concepts derived from
Wikipedia [Gabri06]
[Gabri06] E. Gabrilovich and S. Markovitch. Overcoming the Brittleness Bottleneck using Wikipedia: Enhancing Text
Categorization with Encyclopedic Knowledge. In Proceedings of the 21th National Conf. on Artificial Intelligence and the
18th Innovative Applications of Artificial Intelligence Conference, pages 1301–1306. AAAI Press, 2006.
Panthera
World
War II
Jane
Fonda
Island](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-202-320.jpg)








![The semantics of a text fragment is the
centroid of the semantics of its words
Game
Controller
[0.32]
Mickey
Mouse
[0.81]
Game
Controller
[0.64]
Explicit Semantic Analysis (ESA)](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-211-320.jpg)






![Explicit Semantic Analysis (ESA)
Artificial
Intelligence
[0.61]](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-218-320.jpg)



















![Dimensionality reduction
..even if it sounds weird
theory: Johnson-Lindenstrauss’ lemma [*]
Bm,k ≈ Am,n Rn,k k << n
distances between the points in the reduced space
approximately preserved if
context vectors are nearly orthogonal
(and they are)
[*] Johnson, W. B., & Lindenstrauss, J. (1984). Extensions of Lipschitz mappings
into a Hilbert space. Contemporary mathematics, 26(189-206), 1.](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-238-320.jpg)








![Word2Vec
Hidden Layer:
• N nodes
• N = size of the embeddings
• Parameter of the model
Weight of the network:
• Randomly set (initially)
• Updated through the training
Final Representation for term tk
• Weights Extracted from the network
• tk=[wtkv1, wtkv2 … wtkvn]
Input Layer:
• Vocabulary V
• |V| number of terms
• |V| nodes
• One-hot representation
(Partial) Structure of the network](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-247-320.jpg)

![Word2Vec
Training Procedure: how to create training examples?
Skip-Gram Methodology
Given a word w(t), predict its
context w(t-2), t(t-1).. w(t+1), w(t+2)
Example
Input: ”the quick brown fox
jumped over the lazy dog”
Window Size: 1
Contexts:
• ([the, brown], quick)
• ([quick, fox], brown)
• ([brown, jumped], fox) ...
Training Examples:
• (quick, the)
• (quick, brown)
• (brown, quick)
• (brown, fox) ...](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-249-320.jpg)


































![Graph-based RecSys
Personalized PageRank [*] to identify
the most relevant nodes in the graph
[*] T. H. Haveliwala. Topic-
Sensitive PageRank: A
Context-Sensitive Ranking
Algorithm for Web Search.
IEEE Trans. Knowl. Data
Eng., 15(4):784–796, 2003.](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-284-320.jpg)



















![Word2Vec
• Empirical Comparison of Word Embedding Techniques
for Content-based Recommender Systems [*]
• Methodology
• Build a WordSpace using different Word Embedding
techniques (and different sizes)
• Build a DocSpace as the centroid vectors of term vectors
• Build User Profiles as centroid of the items they liked
• Provide Users with Recommendations
• Compare the approaches
European Conference on Information Retrieval](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-304-320.jpg)


![eVSM
• Enhanced Vector Space Model [*]
• Content-based Recommendation Framework
• Cornerstones
• Semantics modeled through Distributional Models
• Random Indexing for Dimensionality Reduction
• Negative Preferences modeled through Quantum Negation [^]
• User Profiles as centroid vectors of items representation
• Recommendations through Cosine Similarity
[*] Musto, Cataldo. "Enhanced vector space models for content-based recommender systems." Proceedings of the fourth
ACM conference on Recommender systems. ACM, 2010.
Mathematics of language](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-307-320.jpg)









![C-eVSM
• Contextual Enhanced Vector Space Model [*]
• Extension of eVSM: context-aware Framework
• Cornerstones
• Entity Linking of the content through Tag.me
• Semantics modeled through Distributional Models
• Random Indexing for Dimensionality Reduction
• Distributional Models also used to build a representation of
the context
• Context-aware User Profiles as centroid vectors
• Recommendations through Cosine Similarity
Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based
recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-317-320.jpg)













![C-eVSM
Incorporating contextual information in recommender systems using a multi-
dimensional approach
Compared to Context-aware Collaborative Filtering (CACF)
[*] algorithm: better in 7 contextual segments](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-331-320.jpg)

![Text Categorization [Gabri09]
experiments on diverse datasets
Semantic relatedness of
words and texts [Gabri09]
cosine similarity between vectors of ESA concepts
Information Retrieval [Egozi08, Egozi11]
ESA-based IR algorithm enriching documents and queries
ESA effectively used for
[Gabri09] E. Gabrilovich and S. Markovitch. Wikipedia-based Semantic Interpretation for Natural Language Processing. Journal of Artificial
Intelligence Research 34:443-498, 2009.
[Egozi08] Ofer Egozi, Evgeniy Gabrilovich, Shaul Markovitch: Concept-Based Feature Generation and Selection for Information Retrieval.
AAAI 2008, 1132-1137, 2008.
[Egozi11] Ofer Egozi, Shaul Markovitch, Evgeniy Gabrilovich. Concept-Based Information Retrieval using Explicit Semantic Analysis.
ACM Transactions on Information Systems 29(2), April 2011.
370
what about ESA for Information Filtering?](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-333-320.jpg)
![Electronic Program Guides
problem
description of TV shows too short or
poorly meaningful to feed a
content-based recommendation algorithm
solution
Explicit Semantic Analysis exploited to obtain an
enhanced representation
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199.
Springer, 2012
372](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-334-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
373](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-335-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
374](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-336-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
375
Wikipedia Articles related to the
TV show are added to the
description](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-337-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
376
user profile tv show
motogp
sports
motorbike
...
competition
2012 Superbike
Italian Grand Prix](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-338-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
377
user profile tv show
motogp
sports
motorbike
...
competition
2012 Superbike
Italian Grand Prix
XNo matching!](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-339-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
378
user profile tv show
2012 Superbike
Italian Grand Prix
motogp
superbike
sports
motorbike
formula 1
…
competition
Through ESA we can
add new features to
the profile and we
can improve the
overlap between
textual description](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-340-320.jpg)
![Electronic Program Guides
[Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout.
Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012
379
user profile tv show
2012 Superbike
Italian Grand Prix
motogp
superbike
sports
motorbike
formula 1
…
competition
Matching!
✔](https://image.slidesharecdn.com/umap2016tutorialfinal-160725085009/85/Semantics-aware-Techniques-for-Social-Media-Analysis-User-Modeling-and-Recommender-Systems-Tutorial-UMAP-2016-341-320.jpg)















































































Semantics-aware Techniques for Social Media Analysis, User Modeling and Recommender Systems - Tutorial @UMAP 2016
- 1. cataldo musto and pasquale lops dept. of computer science university of bari “aldo moro”, italy semantics-aware techniques for social media analysis user modelling and recommender systems tutorial@UMAP 2016 Halifax, Canada – July 16, 2015
- 3. in this tutorial how to represent content to improve information access and build a new generation of services for social media analysis, user modeling and recommender systems?
- 4. Agenda Why? How? What? Why do we need intelligent information access? Why do we need content? Why do we need semantics? How to introduce semantics? Basics of Natural Language Processing Encoding exogenous semantics (top-down approaches) Encoding endogenous semantics (bottom-up approaches) Semantics-aware Recommender Systems Cross-lingual Recommender Systems Explaining Recommendations Semantic User Profiles based on Social Data Semantic Analysis of Social Streams
- 5. Why? Why do we need intelligent information access?
- 7. physiologically impossible to follow the information flow in real time
- 8. (Source: Adrian C.Ott, The 24-hour customer) we can handle 126 bits of information/day we deal with 393 bits of information/day ratio: 3x
- 9. Information overload (Appeared for the first time in «Future Shock» by Alvin Toffler, 1970)
- 10. Information overload (Appeared for the first time in «Future Shock» by Alvin Toffler, 1970)
- 11. Information overload (Appeared for the first time in «Future Shock» by Alvin Toffler, 1970)
- 12. Information overload “It is not information overload. It is filter failure” Clay Shirky talk @Web2.0 Expo
- 13. Challenge To effectively cope with information overload we need to filter the information flow We need technologies and algorithms for intelligent information access … and we already have some evidence!
- 14. Intelligent Information Access Information Retrieval (Search Engines)
- 15. Intelligent Information Access Information Filtering (Recommender Systems)
- 16. Why? Why do we need content?
- 17. Search engines need content Why do we need content? Trivial: search engines can’t work without content
- 18. Why do we need content? Recommender Systems: not trivial!
- 19. Why do we need content? Recommender Systems can work without content
- 20. Why do we need content? Several Recommender Systems perfectly work without using any content! (e.g.Amazon) Collaborative Filtering and Matrix Factorization are state of the art techniques for implementing Recommender Systems (ACM RecSys 2009, by Neflix Challenge winners)
- 21. Why do we need content? Content can tackle some issues of collaborative filtering
- 22. Why do we need content? Collaborative Filtering issues: sparsity
- 23. Why do we need content? Collaborative Filtering issues: new item problem
- 24. Why do we need content? Collaborative Filtering: lack of transparency!
- 25. Why do we need content? Collaborative Filtering: poor explanations! Who knows the «customers who bought…»?
- 26. Why do we need content? User Modeling based on simple graph-based representation of social connections is quite poor. User Models can benefit of information about the items the user has consumed (news content, hashtag contained in the Tweets she liked, etc.) To enrich and improve user modeling
- 27. Why do we need content? Because a relevant part of the information spread on social media is content! And social media really matter
- 28. Because a relevant part of the information spread on social media is content!
- 29. can be considered as novel data silos Social Media
- 30. Social Media information about preferences
- 31. information about People feelings and connections Social Media
- 32. changed the rule for user modeling and personalization Social Media
- 33. Recap #1 Why do we need content? In general: to extend and improve user modeling To exploit the information spread on social media To overcome typical issues of collaborative filtering and matrix factorization Because search engines can’t simply work without content
- 34. Why? Why do we need semantics?
- 35. Why do we need semantics? A deep comprehension of the information conveyed by textual content is crucial to improve the quality of user profiles and the effectiveness of intelligent information access platforms.
- 36. Why do we need semantics? …some scenarios can be more convincing (But we need some basics, before)
- 37. Basics: Content-based RecSys (CBRS) Suggest items similar to those the user liked in the past Recommendations generated by matching the description of items with the profile of the user’s interests use of specific features Recommender Systems Handbook, The Adaptive Web
- 38. Basics: Content-based RecSys (CBRS) user profile items
- 39. Basics: Content-based RecSys (CBRS) user profile items Recommendation are generated by matching the features stored in the user profile with those describing the items to be recommended.
- 40. Basics: Content-based RecSys (CBRS) user profile items Recommendation are generated by matching the features stored in the user profile with those describing the items to be recommended. X
- 41. Lack of Semantics in User Models “I love turkey. It’s my choice for these #holidays! Social Media can be helpful to avoid cold start
- 42. Lack of Semantics in User Models “I love turkey. It’s my choice for these #holidays! ..but pure content-based representations can’t handle polysemy
- 43. Lack of Semantics in User Models “I love turkey. It’s my choice for these #holidays! Pure Content-based Representation can easily drive a recommender systems towards failures! ?
- 44. Lack of Semantics in Social Media Analysis ? What are people worried about? Are they worried about the eagle or about the city of L’Aquila?
- 45. Lack of Semantics in User Models AI Artificial Intelligence apple multi-word concepts ? Book recommendation
- 46. AI Artificial Intelligence apple synonymy Lack of Semantics in User Models …is not only about polysemy ? Book recommendation Most of the preferences regard AI, but due to synonymy «apple» is the most relevant feature in the profile
- 47. italian english Lack of Semantics in CBRS
- 48. Lack of Semantics in CBRS user profile items
- 49. Lack of Semantics in CBRS user profile items It is likely that the algorithm is not able to suggest a (relevant) english news since no overlap between the features occurs! X
- 50. Lack of Semantics in CBRS user profile items It is likely that the algorithm is not able to suggest a (relevant) english news since no overlap between the features occurs! X
- 51. Recap #2 In general: to improve content representation in intelligent information access platforms To avoid typical issues of natural language representations (polysemy, synonymy, etc.) To better model user preferences To better understand the information spread on social media To provide multilingual recommendations Why do we need semantics? Becuase language is inherently ambiguous
- 52. How? How to introduce semantics?
- 53. Information Retrieval and Filtering Two sides of the same coin (Belkin&Croft,1992) Information Retrieval information need expressed through a query goal: retrieve information which might be relevantto a user Information Filtering information need expressed through a user profile goal: expose users to only the information that is relevantto them, according to personal profiles [Belkin&Croft, 1992] Belkin, Nicholas J., and W. Bruce Croft. "Information filtering and information retrieval: Two sides of the same coin?." Communications of the ACM 35.12 (1992): 29-38. It’s all about searching!
- 54. Search (and Content-based Recommendation) is not so simple as it might seem Meno: and how will you enquire, Socrates, into that which you do not know? What will you put forth as the subject of enquiry? And if you find what you want, how will you know that this is the thing you did not know? Socrates: I know, Meno, what you mean; but just see what a tiresome dispute you are introducing. You argue that a man cannot search either for what he knows or for what he does not know; if he knows it, there is no need to search; and if not, he cannot; he does not know the very subject about which he is to search. Plato Meno 80d-81a http://www.gutenberg.org/etext/1643 60 Meno’s Paradox of Inquiry
- 55. Meno’s question at our times: the “vocabulary mismatch” problem (revisited) How to discover the concepts that connect us to the the information we are seeking (search task) or we want to be exposed to (recommendation and user modeling tasks) ? 61
- 56. Meno’s question at our times: the “vocabulary mismatch” problem (revisited) How to discover the concepts that connect us to the the information we are seeking (search task) or we want to be exposed to (recommendation and user modeling tasks) ? 62 We need some «intelligent» support (as intelligent information access technologies)
- 57. Meno’s question at our times: the “vocabulary mismatch” problem (revisited) How to discover the concepts that connect us to the the information we are seeking (search task) or we want to be exposed to (recommendation and user modeling tasks) ? 63 We need to better understand and represent the content We need some «intelligent» support (as intelligent information access technologies)
- 58. Meno’s question at our times: the “vocabulary mismatch” problem (revisited) How to discover the concepts that connect us to the the information we are seeking (search task) or we want to be exposed to (recommendation and user modeling tasks) ? 64 We need to better understand and represent the content We need some «intelligent» support (as intelligent information access technologies)
- 59. …before semantics some basics of Natural Language Processing (NLP)
- 60. How? basics of NLP and keyword-based representations
- 61. Scenario Pasquale really loves the movie «The Matrix», and he asks a content-based recommender system for some suggestions. How can we feed the algorithm with some textual features related to the movie to build a (content-based) profile and provide recommendations? ? Question Recommendation Engine
- 62. Scenario the plot can be a rich source of content-based features
- 63. Scenario …but we need to properly process it through a pipeline of Natural Language Processing techniques the plot can be a rich source of content-based features
- 64. Basic NLP operations o normalization strip unwanted characters/markup (e.g. HTML/XML tags, punctuation, numbers, etc.) o tokenization break text into tokens o stopword removal exclude common words having little semantic content o lemmatization reduce inflectional/variant forms to base form (lemma in the dictionary), e.g. am, are, is be o stemming reduce terms to their “roots”, e.g. automate(s), automatic, automation all reduced to automat vocabulary
- 65. Example The Matrix is a 1999 American-Australian neo-noir science fiction action film written and directed by the Wachowskis, starring Keanu Reeves, Laurence Fishburne, Carrie-Anne Moss, Hugo Weaving, and Joe Pantoliano. It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called "the Matrix", created by sentient machines to subdue the human population, while their bodies' heat and electrical activity are used as an energy source. Computer programmer "Neo" learns this truth and is drawn into a rebellion against the machines, which involves other people who have been freed from the "dream world".
- 66. X X X X X X X XX XX X XXX X X X X The Matrix is a 1999 American-Australian neo-noir science fiction action film written and directed by the Wachowskis, starring Keanu Reeves, Laurence Fishburne, Carrie-Anne Moss, Hugo Weaving, and Joe Pantoliano. It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called "the Matrix", created by sentient machines to subdue the human population, while their bodies' heat and electrical activity are used as an energy source. Computer programmer "Neo" learns this truth and is drawn into a rebellion against the machines, which involves other people who have been freed from the "dream world". Example normalization
- 67. Example The Matrix is a 1999 American Australian neo noir science fiction action film written and directed by the Wachowskis starring Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving and Joe Pantoliano It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called the Matrix created by sentient machines to subdue the human population while their bodies heat and electrical activity are used as an energy source Computer programmer Neo learns this truth and is drawn into a rebellion against the machines which involves other people who have been freed from the dream world tokenization
- 68. Tokenization issues compound words o science-fiction: break up hyphenated sequence? o Keanu Reeves: one token or two? How do you decide it is one token? numbers and dates o 3/20/91 Mar. 20, 1991 20/3/91 o 55 B.C. o (800) 234-2333
- 69. Tokenization issues language issues o German noun compounds not segmented Lebensversicherungsgesellschaftsangestellter means life insurance company employee o Chinese and Japanese have no spaces between words (not always guaranteed a unique tokenization) 莎拉波娃现在居住在美国东南部的佛罗里达 o Arabic (or Hebrew) is basically written right to left, but with certain items like numbers written left to right Algeria achieved its independence in 1962 after 132 years of French occupation
- 70. X X X X X X X X X X X X XX XX X X X X X X X X X X X X X X XX X X X X XX X X X Example stopword removal The Matrix is a 1999 American Australian neo noir science fiction action film written and directed by the Wachowskis starring Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving and Joe Pantoliano It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called the Matrix created by sentient machines to subdue the human population while their bodies heat and electrical activity are used as an energy source Computer programmer Neo learns this truth and is drawn into a rebellion against the machines which involves other people who have been freed from the dream world
- 71. Example The Matrix is a 1999 American Australian neo noir science fiction action film written and directed by the Wachowskis starring Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving and Joe Pantoliano It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called the Matrix created by sentient machines to subdue the human population while their bodies heat and electrical activity are used as an energy source Computer programmer Neo learns this truth and is drawn into a rebellion against the machines which involves other people who have been freed from the dream world stopword removal
- 72. Example The Matrix is a 1999 American Australian neo noir science fiction action film written and directed by the Wachowskis starring Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving and Joe Pantoliano It depicts a dystopian future in which reality as perceived by most humans is actually a simulated reality called the Matrix created by sentient machines to subdue the human population while their bodyies heat and electrical activity are used as an energy source Computer programmer Neo learns this truth and is drawn into a rebellion against the machines which involves other people who have been freed from the dream world lemmatization
- 73. Example Matrix 1999 American Australian neo noir science fiction action film write direct Wachowskis star Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving Joe Pantoliano depict dystopian future reality perceived human simulate reality call Matrix create sentient machine subdue human population body heat electrical activity use energy source Computer programmer Neo learn truth draw rebellion against machine involve people free dream world next step: to give a weight to each feature (e.g. through TF-IDF)
- 74. Weighting features: TF-IDF terms frequency – inverse document frequency best known weighting scheme in information retrieval. Weight of a term as product of tf weight and idf weight tf number of times the term occurs in the document idf depends on rarity of a term in a collection tf-idf increases with the number of occurrences within a document, and with the rarity of the term in the collection. )df/log()tflog1(w ,, tdt Ndt
- 75. Example Matrix 1999 American Australian neo noir science fiction action film write direct Wachowskis star Keanu Reeves Laurence Fishburne Carrie Anne Moss Hugo Weaving Joe Pantoliano depict dystopian future reality perceived human simulate reality call Matrix create sentient machine subdue human population body heat electrical activity use energy source Computer programmer Neo learn truth draw rebellion against machine involve people free dream world green=high IDF red=low IDF
- 76. The Matrix representation Matrix 1999 American Australian fiction world keywords a portion of Pasquale’s content-based profile given a content-based profile, we can easily build a basic recommender system through Vector Space Model and similarity measures science Hugo
- 77. Vector Space Model (VSM) given a set of n features (vocabulary) f = {f1, f2 ,..., fn} given a set of M items, each item I represented as a point in a n-dimensional vector space I = (wf1,.....wfn) wfi is the weight of feature i in the item
- 78. Similarity between vectors cosine similarity V i i V i i V i ii JI JI J J I I JI JI JI 1 2 1 2 1 ),cos( dot product unit vectors
- 79. Basic Content-based Recommendations o documents represented as vectors o features identified through NLP operations o features weigthed using tf-idf o cosine measure for computing similarity between vectors
- 80. Drawbacks a portion of Pasquale’s content-based profile Recommendation: Notre Dame de Paris, by Victor Hugo Basic Content-based Recommendations Why? Entities as «Hugo Weaving» were not modeled Matrix 1999 American Australian fiction world science Hugo
- 81. Drawbacks Basic Content-based Recommendations Why? More complex concepts as «science fiction» were not modeled as single features Recommendation: The March of Penguins Matrix 1999 American Australian fiction world science Hugo a portion of Pasquale’s content-based profile
- 83. Vision Basic Content-based Recommendations Bad recommendations
- 84. Recap #3 Natural Language Processing techniques necessary to build a content-based profile basic content-based algorithms can be easily built through TF-IDF keyword-based representation too poor and can drive to bad modeling of preferences (and bad recommendations) we need to shift from keywords to concepts basics of NLP and keyword-based representation
- 87. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics
- 88. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics top-down approaches based on the integration of external knowledge for representing content. Able to provide the linguistic, cultural and backgroud knowledge in the content representation
- 89. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics top-down approaches based on the integration of external knowledge for representing content. Able to provide the linguistic, cultural and backgroud knowledge in the content representation bottom-up approaches that determine the meaning of a word by analyzing the rules of its usage in the context of ordinary and concrete language behavior
- 90. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 91. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Word Sense Disambiguation Entity Linking ……. Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the item to a knowledge graph
- 92. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Ontologies Linked Open Data Introduce semantics by linking the Item to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 93. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 94. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 95. How? Encoding exogenous semantics (top-down approaches)
- 96. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Word Sense Disambiguation Entity Linking ……. Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 97. Word Sense Disambiguation (WSD) using linguistic ontologies WSD selects the proper meaning, i.e. sense, for a word in a text by taking into account the context in which it occurs
- 98. Word Sense Disambiguation (WSD) using linguistic ontologies WSD selects the proper meaning, i.e. sense, for a word in a text by taking into account the context in which it occurs
- 99. Sense Repository WordNet groups words into sets of synonyms called synsets It contains nouns, verbs, adjectives, adverbs Word Meanings Word Forms F1 F2 F3 … … Fn M1 V(1,1) V(2,1) M2 V(2,2) V(3,2) M3 M… Mm V(m,n) Synonym word forms (synset) polysemous word: disambiguation needed WordNet linguistic ontology [*] [*] Miller, George A. "WordNet: a lexical database for English." Communications of the ACM 38.11 (1995): 39-41.
- 100. an example of synset Sense Repository WordNet linguistic ontology
- 101. Sense Repository WordNet Hierarchies WordNet linguistic ontology
- 102. Word Sense Disambiguation State of the art: JIGSAW algorithm [*] Input o D = {w1, w2, …. , wh} document Output o X = {s1, s2, …. , sk} (kh) Each si obtained by disambiguating wi based on the context of each word Some words not recognized by WordNet Groups of words recognized as a single concept [*] Basile, P., de Gemmis, M., Gentile, A. L., Lops, P., & Semeraro, G. (2007, June). UNIBA: JIGSAW algorithm for word sense disambiguation. InProceedings of the 4th International Workshop on Semantic Evaluations (pp. 398-401). Association for Computational Linguistics.
- 103. How to use WordNet for WSD? Semantic similarity between synsets inversely proportional to their distance in the WordNet IS-A hierarchy Path length similarity between synsets used to assign scores to synsets of a polysemous word in order to choose the correct sense Placental mammal Carnivore Rodent Feline, felid Cat (feline mammal) Mouse (rodent) 1 2 3 4 5 JIGSAW WSD algorithm
- 104. SINSIM(cat,mouse) = -log(5/32)=0.806 Placental mammal Carnivore Rodent Feline, felid Cat (feline mammal) Mouse (rodent) 1 2 3 4 5 Synset semantic similarity
- 107. through WSD can we obtain a semantics-aware representation of textual content
- 108. Synset-based representation {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man")
- 109. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation through WSD we process the textual description of the item and we obtain a semantics-aware representation of the item as output keyword-based features replaced with the concepts (in this case WordNet synsets) they refer to Matrix 1999 American Australian fiction world keywords science Hugo
- 110. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Word Sense Disambiguation recap polysemy and synonymy effectively handled classical NLP techniques helpful to remove further noise (e.g. stopwords) potentially language-independent (later) entities (e.g. Hugo Weaving) still not recognized Matrix 1999 American Australian fiction world keywords science Hugo
- 111. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Word Sense Disambiguation Entity Linking Introduce semantics by linking the item itself to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 112. • Basic Idea • Input: free text • e.g. Wikipedia abstract • Output: identification of the entities mentioned in the text. Entity Linking Algorithms
- 113. Why Entity Linking? because we need to identify the entities mentioned in the textual description to better catch user preferences and information needs. … and many more Several state-of-the-art implementations are already available
- 115. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords entities
- 116. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords entities entities are correctly recognized and modeled partially multilingual (entities are inherently multilingual, but other concepts aren’t) common sense and abstract concepts now ignored.
- 117. very transparent and human-readable content representation non-trivial NLP tasks automatically performed (stopwords removal, n-grams identification, named entities recognition and disambiguation) Entity Linking Algorithms Tag.me Output
- 118. each entity identified in the content can be a feature of a semantics-aware content representation based on entity linking Entity Linking Algorithms Tag.me Output
- 119. Advantage #1: several common sense concepts are now identified Entity Linking Algorithms Tag.me Output
- 120. Output Advantage #2: each entity is a reference to a Wikipedia page http://en.wikipedia.org/wiki/The_Wachowskis not a simple textual feature! Entity Linking Algorithms Tag.me
- 121. We can enrich this entity-based representation by exploiting the Wikipedia categories’ tree Entity Linking Algorithms Tag.me + Wikipedia Categories
- 122. final representation of items obtained by merging entities identified in the text with the (most relevant) Wikipedia categories each entity is linked to +entities wikipedia categoriesfeatures = Entity Linking Algorithms Tag.me + Wikipedia Categories
- 123. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords Wikipedia pages
- 124. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords Wikipedia pages entities recognized and modeled (as in OpenCalais) Wikipedia-based representation: some common sense terms included, and new interesting features (e.g. «science-fiction fil director») can be generated terms without a Wikipedia mapping are ignored
- 125. traditional resources collaborative resources o manually curated by experts o available for a few languages o difficult to maintain and update o collaboratively built by the crowd o highly multilingual o up-to-date Entity Linking Algorithms Babelfy
- 127. Entity Linking Algorithms Babelfy we have both Named Entities and Concepts!
- 130. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords Babel synsets
- 131. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation Matrix 1999 American Australian neo science fiction world keywords Babel synsets entities recognized and modeled (as in OpenCalais and Tag.me) Wikipedia-based representation: some common sense terms included, and new interesting features (e.g. «science-fiction director) can be generated includes linguistic knowledge and is able to disambiguate terms also multilingual!
- 132. Recap #4 o «Exogenous» techniques use external knowledge sources to inject semantics o Word Sense Disambiguation algorithms process the textual description and replace keywords with semantic concepts (as synsets) o Entity Linking algorithms focus on the identification of the entities. Some recent approaches also able to identify common sense terms o Combination of both approaches is potentially the best strategy encoding exogenous semantics by processing textual descriptions
- 133. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Ontologies Linked Open Data Introduce semantics by linking the Item to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 134. Ontologies o used to describe domain-specific knowledge o hierarchies of concepts with attributes and relations o “An ontology is a formal, explicit specification of a shared conceptualization” Guarino, Nicola. "Understanding, building and using ontologies." International Journal of Human-Computer Studies 46.2 (1997): 293-310.
- 135. Exogenous Semantics through Ontologies why do we need an ontology? to share common understanding of the structure of information o among people o among software agents to enable reuse of domain knowledge o to avoid “re-inventing the wheel” o to introduce standards to allow interoperability
- 136. Exogenous Semantics through Ontologies why do we need an ontology? to share common understanding of the structure of information o among people o among software agents to enable reuse of domain knowledge o to avoid “re-inventing the wheel” o to introduce standards to allow interoperability …let’s have an example!
- 137. Exogenous Semantics through Ontologies A Movie Ontology
- 138. Exogenous Semantics through Ontologies A Movie Ontology (a small portion, actually) we formally encode relevant aspects and the relationships among them
- 139. Exogenous Semantics through Ontologies A Movie Ontology (a small portion, actually) every item formally modeled by following this structure and encoded through a Semantic Web language (e.g. OWL, RDF)
- 140. Exogenous Semantics through Ontologies A Movie Ontology (a small portion, actually) every item formally modeled by following this structure and encoded through a Semantic Web language (e.g. OWL, RDF)
- 141. Exogenous Semantics through Ontologies A Movie Ontology (a small portion, actually) why is it useful?
- 142. Exogenous Semantics through Ontologies A Movie Ontology why is it useful? each feature has a non-ambiguous «meaning»
- 143. Exogenous Semantics through Ontologies A Movie Ontology why is it useful? we don’t need to process unstructured content
- 144. Exogenous Semantics through Ontologies A Movie Ontology (a small portion, actually) why is it useful? we can perform some «reasoning» on user preferences. How?
- 145. Exogenous Semantics through Ontologies The Movie Ontology We can reason on the preferences and infer that a user interested in The Matrix (SciFi_and_Fantasy genre) is interested in Imaginational_Entertainment and potentially in Logical_Thrilling
- 146. The Matrix representation from a flat representation toward a graph-based representation
- 147. The Matrix representation from a flat representation toward a graph-based representation semantics explicitly encoded explicit relations between concepts exist: reasoning to infer interesting information ontologies typically domain-dependant huge effort to build and mantain an ontology very huge effort to populate an ontology!
- 148. Vision
- 149. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Ontologies Linked Open Data Introduce semantics by linking the Item to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 150. Linked Open Data the giant global graph
- 151. Linked Open Data (cloud) what is it? (large) set of interconnected semantic datasets
- 152. Linked Open Data (cloud) statistics 149 billions triples, 3,842 datasets (http://stats.lod2.eu)
- 153. Linked Open Data (cloud) DBpedia core of the LOD cloud RDF mapping of Wikipedia
- 154. Linked Open Data cornerstones 1. 2. methodology to publish, share and link structured data on the Web use of RDF o every resource/entity/relation identified by a (unique) URI o URI: http://dbpedia.org/resource/Halifax re-use of existing properties to express an agreed semantics and connect data sources
- 155. Linked Open Data (cloud)
- 156. Linked Open Data (cloud) representation The Matrix dbpedia-owl:directordbo:runtime interesting non-trivial features come into play dcterms:subjectdcterms:subject
- 157. The Matrix representation from a flat representation toward a (richer) graph-based representation
- 158. The Matrix representation we have the advantage of formal semantics defined in RDF, with interesting features coming from Wikipedia without the need of building and manually populating an ontology
- 159. 1. 2. graph-based data models can be exploited to define more semantic features based on graph topology another advantage
- 160. i4 (bipartite graph) users = nodes items = nodes preferences = edges Very intuitive representation! u1 i1 u2 i2 u3 i3 u4 i4 Graph-based Data Model
- 161. i4 u1 i1 u2 u3 i3 u4 Semantic Graph-based Data Model
- 162. i4 DBpedia mapping u1 i1 u2 u3 i3 u4 Semantic Graph-based Data Model
- 163. i4 u1 i1 u2 u3 i3 u4 dcterms:subject Films about Rebellions Quentin Tarantino 1999 films http://dbpedia.org/resource/1999_films dcterms:subject Semantic Graph-based Data Model (1-hop)
- 164. i 4 u1 i 1u2 u3 i 3u4 dcterms:subject Films about Rebellions Quentin Tarantino 1999 films http://dbpedia.org/resource/1999_films dcterms:subject American film directors dbo:award Lynne Thigpen http://dbpedia.org/resource/Lynne_Thigpen Semantic Graph-based Data Model (2-hop)
- 165. i 4 u1 i 1u2 u3 i 3u4 dcterms:subject Films about Rebellions Quentin Tarantino 1999 films http://dbpedia.org/resource/1999_films dcterms:subject American film directors dbo:award Lynne Thigpen http://dbpedia.org/resource/Lynne_Thigpen Semantic Graph-based Data Model (n-hop)
- 166. PageRank Spreading activation Average Neighbors Degree Centrality … Semantic Graph-based Data Model (Feature Generation) new semantic features describing the item can be inferred by mining the structure of the tripartite graph
- 167. Recap #5 o Ontologies enrich the representation by introducing formal semantics, but they are very complicated to maintain and build o Linked Open Data merge the advantages of ontologies with the simplicity of a collaborative knowledge source as Wikipedia o Such approaches build a graph-based representation that triggers the generation of semantic topological features o Inherently multilingual! encoding exogenous semantics through Knowledge Graphs
- 168. How? Encoding endogenous semantics (bottom-up approaches)
- 169. Insight Very huge availability of textual content
- 170. Insight We can use this huge amount of content to directly learn a representation of words
- 171. Insight What is «Peroni» ? Pass me a Peroni! I like Peroni Football and Peroni, what a perfect Saturday!
- 172. Insight What is «Budweiser» ? Pass me a Budweiser! I like Budweiser Football and Budweiser, what a perfect Saturday!
- 173. Insight What is «Budweiser» ? Pass me a Budweiser! I like Budweiser Football and Budweiser, what a perfect Saturday!
- 174. Insight What is «Peroni» ? Pass me a Peroni! I like Peroni Football and Peroni, what a perfect Saturday!
- 175. Insight Distributional Hypothesis «Terms used in similar contexts share a similar meaning»
- 176. Insight The semantics learnt according to terms usage is called «distributional»
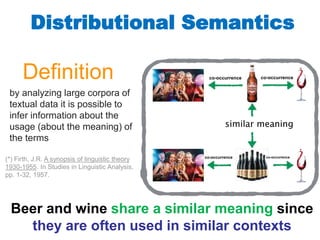
- 178. Distributional Semantics by analyzing large corpora of textual data it is possible to infer information about the usage (about the meaning) of the terms Definition co-occurrence co-occurrence co-occurrence co-occurrence (*) Firth, J.R. A synopsis of linguistic theory 1930-1955. In Studies in Linguistic Analysis, pp. 1-32, 1957.
- 179. Distributional Semantics by analyzing large corpora of textual data it is possible to infer information about the usage (about the meaning) of the terms Definition co-occurrence co-occurrence co-occurrence co-occurrence Beer and wine share a similar meaning since they are often used in similar contexts (*) Firth, J.R. A synopsis of linguistic theory 1930-1955. In Studies in Linguistic Analysis, pp. 1-32, 1957.
- 180. Distributional Semantics Term-Contexts Matrix A vector-space representation is learnt by encoding in which context each term is used (This representation is called WordSpace)
- 181. Distributional Semantics Term-Contexts Matrix A vector-space representation is learnt by encoding in which context each term is used Each row of the matrix is a vector!
- 182. Distributional Semantics Term-Contexts Matrix beer vs wine: good overlap Similar!
- 183. Distributional Semantics Term-Contexts Matrix beer vs wine: no overlap Not Similar!
- 184. WordSpace beer wine mojito dog A vector space representation (called WordSpace) is learnt according to terms usage in contexts
- 185. WordSpace beer wine mojito dog A vector space representation (called WordSpace) is learnt according to terms usage in contexts Terms sharing a similar usage are very close in the space
- 186. Distributional Semantics Term-Contexts Matrix Key question: what is the context?
- 187. Distributional Semantics Term-Contexts Matrix Key question: what is the context? These approaches are very flexible since the «context» can be set according to the granularity required by the representation
- 188. Distributional Semantics Term-Contexts Matrix Key question: what is the context? Coarse-grained granularity: context=whole document
- 189. Distributional Semantics Term-Contexts Matrix = Term-Document Matrix Key question: what is the context? (This is Vector Space Model!) Vector Space Model is a Distributional Model
- 190. Distributional Semantics Term-Contexts Matrix Key question: what is the context? Fine-grained granularities: context=paragraph, sentence, window of words
- 191. Distributional Semantics Term-Contexts Matrix Fine-grained granularities: PROs: the more fine-grained the representation, more precise the vectors CONs: the more fine-grained the representation, the bigger the matrix
- 192. Distributional Semantics Term-Contexts Matrix The flexibility of distributional semantics models also regards the rows of the matrix
- 193. Distributional Semantics Term-Contexts Matrix The flexibility of distributional semantics models also regards the rows of the matrix Keywords can be replaced with concepts (as synsets or entities!)
- 194. Distributional Semantics Term-Contexts Matrix The flexibility of distributional semantics models also regards the rows of the matrix Keywords can be replaced with concepts (as synsets or entities!) ✔ ✔
- 195. Distributional Semantics ✔ ✔ Term-Contexts Matrix Keanu Reeves and Al Pacino are «connected» because they both acted in Drama Films
- 196. Distributional Semantics Representing Documents Given a WordSpace, a vector space representation of documents (called DocSpace) is typically built as the centroid vector of word representations ✔ ✔
- 198. DocSpace Given a WordSpace, a vector space representation of documents (called DocSpace) is typically built as the centroid vector of word representations Matrix Revolutions Donnie Darko Up! similarity calculations between items semantic representation The Matrix
- 199. Distributional Semantics • We can exploit the (big) corpora of data to directly learn a semantic vector-space representation of the terms of a language • Lightweight semantics, not formally defined • High flexibility: everything is a vector: term/term similarity, doc/term, term/doc, etc.. • Context can have different granularities • Huge amount of content is needed • Matrices are particularly huge and difficult to build • Too many features: need for dimensionality reduction
- 200. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Distributional Semantics models share the same insight but have important distinguishing aspects
- 201. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Distributional Semantics models share the same insight but have important distinguishing aspects
- 202. Explicit Semantic Analysis (ESA) ESA builds a vector-space semantic representation of natural language texts in a high-dimensional space of comprehensible concepts derived from Wikipedia [Gabri06] [Gabri06] E. Gabrilovich and S. Markovitch. Overcoming the Brittleness Bottleneck using Wikipedia: Enhancing Text Categorization with Encyclopedic Knowledge. In Proceedings of the 21th National Conf. on Artificial Intelligence and the 18th Innovative Applications of Artificial Intelligence Conference, pages 1301–1306. AAAI Press, 2006. Panthera World War II Jane Fonda Island
- 203. Explicit Semantic Analysis (ESA) ESA matrix ESA Concept 1 … Concept n term 1 TF-IDF TF-IDF TF-IDF … TF-IDF TF-IDF TF-IDF term k TF-IDF TF-IDF TF-IDF Terms 218 ESA is a Distributional Semantic model which uses Wikipedia articles as context Wikipedia articles
- 204. Explicit Semantic Analysis (ESA) ESA matrix ESA Concept 1 … Concept n term 1 TF-IDF TF-IDF TF-IDF … TF-IDF TF-IDF TF-IDF term k TF-IDF TF-IDF TF-IDF Terms 219 Wikipedia articles semantic relatedness between a word and a concept TF-IDF score
- 205. Every Wikipedia article represents a concept Article words are associated with the concept (TF-IDF) Explicit Semantic Analysis (ESA) Each Wikipedia page can be described in terms of the words with the highest TF/IDF score (this is a column of ESA matrix)
- 206. Explicit Semantic Analysis (ESA) ESA matrix ESA Concept 1 … Concept n term 1 TF-IDF TF-IDF TF-IDF … TF-IDF TF-IDF TF-IDF term k TF-IDF TF-IDF TF-IDF 221 The vector-space representation of each term is called semantic interpretation vector
- 207. Explicit Semantic Analysis (ESA) Every Wikipedia article represents a concept Article words are associated with the concept (TF-IDF) The semantics of a word is the vector of its associations with Wikipedia concepts
- 208. Explicit Semantic Analysis (ESA) Important: the semantics of the words is not static. It changes as Wikipedia articles are modified or new articles are introduced. ESA provides a representation which evolves over time!
- 209. Explicit Semantic Analysis (ESA) «web» in 1980 «web» in 2000 Important: the semantics of the words is not static. It changes as Wikipedia articles are modified or new articles are introduced. ESA provides a representation which evolves over time!
- 210. Explicit Semantic Analysis (ESA) «web» in 1980 «web» in 2000 Important: the semantics of the words is not static. It changes as Wikipedia articles are modified or new articles are introduced. ESA provides a representation which evolves over time!
- 211. The semantics of a text fragment is the centroid of the semantics of its words Game Controller [0.32] Mickey Mouse [0.81] Game Controller [0.64] Explicit Semantic Analysis (ESA)
- 212. Explicit Semantic Analysis (ESA) A semantic representation of an item can be built as the centroid vector of the semantic interpretation vectors of the terms in the plot.
- 213. Explicit Semantic Analysis (ESA) A semantic representation of an item can be built as the centroid vector of the semantic interpretation vectors of the terms in the plot.
- 214. Explicit Semantic Analysis (ESA) Representation can be further improved and enriched by processing content through exogenous techniques (e.g. entity linking) in order to catch complex concepts
- 215. Explicit Semantic Analysis (ESA) semantic relatedness of a pair of text fragments (e.g. description of two items) computed by comparing their semantic interpretation vectors using the cosine metric Matrix Revolutions Donnie Darko Up! The Matrix
- 216. Explicit Semantic Analysis (ESA) Another advantage: ESA can be also used to generate a set of relevant extra concepts describing the items. How?
- 217. Explicit Semantic Analysis (ESA) Another advantage: ESA can be also used to generate a set of relevant extra concepts describing the items. The Wikipedia pages with the highest TF/IDF score in the semantic interpretation vector of the item!
- 218. Explicit Semantic Analysis (ESA) Artificial Intelligence [0.61]
- 219. 235 Explicit Semantic Analysis (ESA)
- 220. Explicit Semantic Analysis (ESA) Distributional Model which uses Wikipedia Article as context Very Transparent representation (columns have an explicit meaning) Representation can evolve over time! Also language-independent, thanks to cross-language Wikipedia links The whole matrix is very huge «Empirical» tuning of the parameters: how many articles? How many terms? What is the thresholding?
- 221. When transparency is not so important, it is possible to learn a more compact vector-space representation of terms and items
- 222. When transparency is not so important, it is possible to learn a more compact vector-space representation of terms and items Dimensionality Reduction techniques
- 223. When transparency is not so important, it is possible to learn a more compact vector-space representation of terms and items a.k.a. Word embedding techniques Embedding = a smaller representation of words (more recent – equivalent - buzzword )
- 224. When transparency is not so important, it is possible to learn a more compact vector-space representation of terms and items a.k.a. Word embedding techniques Embedding = a smaller representation of words Is this new?
- 225. Dimensionality reduction techniques Latent Semantic Analysis (LSA) is a widespread distributional semantics model which builds a term/term matrix and calculates SVD over that matrix. Dumais, Susan T. "Latent semantic analysis." Annual review of information science and technology 38.1 (2004): 188-230.
- 226. Dimensionality reduction techniques Dumais, Susan T. "Latent semantic analysis." Annual review of information science and technology 38.1 (2004): 188-230. Truncated Singular Value Decomposition induces higher-order (paradigmatic) relations through the truncated SVD Latent Semantic Analysis (LSA) is a widespread distributional semantics model which builds a term/context matrix and calculates SVD over that matrix.
- 227. Singular Value Decomposition PROBLEM the huge co-occurrence matrix SOLUTION don’t build the huge co-occurrence matrix! Use incremental and scalable techniques Dimensionality reduction techniques
- 228. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 229. Dimensionality reduction Random Indexing It is an incremental and scalable technique for dimensionality reduction. M. Sahlgren. The Word-Space Model: Using Distributional Analysis to Represent Syntagmatic and Paradigmatic Relations between Words in High-dimensional Vector Spaces. PhD thesis, Stockholm University, 2006.
- 230. Dimensionality reduction Random Indexing It is an incremental and scalable technique for dimensionality reduction. Insight Assign a vector to each context (word, documents, etc.). The vector can be as big as you want. Fill the vector with (almost) randomly assigned values. Given a word, collect the contexts where that word appears. Update the representation according to term co-occurrences. The final representation is the «sum» of the contexts. Obtain a (smaller but equivalent) vector space representation of the terms M. Sahlgren. The Word-Space Model: Using Distributional Analysis to Represent Syntagmatic and Paradigmatic Relations between Words in High-dimensional Vector Spaces. PhD thesis, Stockholm University, 2006.
- 231. Dimensionality reduction Random Indexing It is an incremental and scalable technique for dimensionality reduction. Insight Assign a vector to each context (word, documents, etc.). The vector can be as big as you want. Fill the vector with (almost) randomly assigned values. Given a word, collect the contexts where that word appears. Update the representation according to term co-occurrences. The final representation is the «sum» of the contexts. Obtain a (smaller but equivalent) vector space representation of the terms M. Sahlgren. The Word-Space Model: Using Distributional Analysis to Represent Syntagmatic and Paradigmatic Relations between Words in High-dimensional Vector Spaces. PhD thesis, Stockholm University, 2006.
- 232. Random Indexing Algorithm Step 1 - definition of the context granularity: Document? Paragraph? Sentence? Word? Step 2 – building the random matrix R each ‘context’ (e.g. sentence) is assigned a context vector dimension = k allowed values = {-1, 0, +1} small # of non-zero elements, i.e. sparse vectors values distributed in a random way
- 233. Random Indexing Context vectors of dimension k = 8 Each row is a «context»
- 234. Random Indexing Algorithm Step 3 – building the reduced space B the vector space representation of a term t obtained by combining the random vectors of the context in which it occurs in t1 ∈ {c1, c2, c5}
- 235. Random Indexing Algorithm Step 3 – building the reduced space B r1 0, 0, -1, 1, 0, 0, 0, 0 r2 1, 0, 0, 0, 0, 0, 0, -1 r3 0, 0, 0, 0, 0, -1, 1, 0 r4 -1, 1, 0, 0, 0, 0, 0, 0 r5 1, 0, 0, -1, 1, 0, 0, 0 … rn … t1 ∈ {c1, c2, c5} r1 0, 0, -1, 1, 0, 0, 0, 0 r2 1, 0, 0, 0, 0, 0, 0, -1 r5 1, 0, 0, -1, 1, 0, 0, 0 t1 2, 0, -1, 0, 1, 0, 0, -1 Output: WordSpace
- 236. Random Indexing Algorithm Step 4 – building the document space the vector space representation of a document d obtained by combining the vector space representation of the terms that occur in the document Output: DocSpace
- 237. WordSpace and DocSpace c1 c2 c3 c4 … ck t1 t2 t3 t4 … tm c1 c2 c3 c4 … ck d1 d2 d3 d4 … dn DocSpaceWordSpace Uniform representation k is a simple parameter of the model
- 238. Dimensionality reduction ..even if it sounds weird theory: Johnson-Lindenstrauss’ lemma [*] Bm,k ≈ Am,n Rn,k k << n distances between the points in the reduced space approximately preserved if context vectors are nearly orthogonal (and they are) [*] Johnson, W. B., & Lindenstrauss, J. (1984). Extensions of Lipschitz mappings into a Hilbert space. Contemporary mathematics, 26(189-206), 1.
- 239. Random Indexing …. is also multilingual! the same concept, expressed in different languages, assumes the same position in language-based geometric spaces the position of beer in a geometric space based on English and the position of birra in a geometric space based on Italian are (almost) the same
- 240. Random Indexing …. is also multilingual! Italian WordSpace English WordSpace glass spoon dog beer cucchiaio cane birra bicchiere The position in the space can be slightly different, but the relations similarity between terms still hold
- 241. Random Indexing Incremental and Scalable technique for learning word embeddings
- 242. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 243. Word2Vec • Distributional Model to learn Word Embeddings. • Uses a two-layers neural network • Training based on the Skip-Gram methodology • Update of the network through Mini-batch or Stochastic Gradient Descent In a nutshell
- 244. Word2Vec (Partial) Structure of the network Input Layer: • Vocabulary V • |V| number of terms • |V| nodes • Each term is represented through a «one hot representation»
- 245. Word2Vec (Partial) Strucure of the network Input Layer: • Vocabulary V • |V| number of terms • |V| nodes • One-hot representation Hidden Layer: • N nodes • N = size of the embeddings • Parameter of the model
- 246. Word2Vec (Partial) Structure of the network Hidden Layer: • N nodes • N = size of the embeddings • Parameter of the model Weight of the network: • Randomly set (initially) • Updated through the training Input Layer: • Vocabulary V • |V| number of terms • |V| nodes • One-hot representation
- 247. Word2Vec Hidden Layer: • N nodes • N = size of the embeddings • Parameter of the model Weight of the network: • Randomly set (initially) • Updated through the training Final Representation for term tk • Weights Extracted from the network • tk=[wtkv1, wtkv2 … wtkvn] Input Layer: • Vocabulary V • |V| number of terms • |V| nodes • One-hot representation (Partial) Structure of the network
- 248. Word2Vec Training Procedure: how to create training examples? Skip-Gram Methodology Continuous Bag-of-Words Methodology Given a word w(t), predict its context w(t-2), t(t-1).. w(t+1), w(t+2) Given a context w(t-2), t(t-1).. w(t+1), w(t+2) predict word w(t)
- 249. Word2Vec Training Procedure: how to create training examples? Skip-Gram Methodology Given a word w(t), predict its context w(t-2), t(t-1).. w(t+1), w(t+2) Example Input: ”the quick brown fox jumped over the lazy dog” Window Size: 1 Contexts: • ([the, brown], quick) • ([quick, fox], brown) • ([brown, jumped], fox) ... Training Examples: • (quick, the) • (quick, brown) • (brown, quick) • (brown, fox) ...
- 250. Word2Vec Training Procedure: how to optimize the model? And probability is calculated through soft-max The model tries to maximize The probability of predicting a context C given a word w Given a corpus, we create of training examples through Skip-Gram.
- 251. Word2Vec Training Procedure: how to optimize the model? And probability is calculated through soft-max The model tries to maximize The probability of predicting a context C given a word w Intuitively, probability is high when scalar product is close to 1 when vectors are similar! Given a corpus, we create a training examples through Skip-Gram.
- 252. Word2Vec Training Procedure: how to optimize the model? Given a corpus, we create a training examples through Skip-Gram. And probability is calculated through soft-max The model tries to maximize The probability of predicting a context C given a word w Intuitively, probability is high when scalar product is close to 1 when vectors are similar! Word2Vec is a distributional model since it learns a representation such that couples (word,context) appearing together have similar vectors The error is collected and weights in the network are updated accordingly. Typically is used Stochastic Gradient Descent or Mini- Batch (every 128 or 512 training examples)
- 253. Representation can be really really small (size<100, typically) Trending - Recent and Very Hot technique Word2Vec Learning Word Embeddings through Neural Networks: it is not based on «counting» co- occurrences. It relies on «predict» the distribution Not transparent anymore Needs more computational resources
- 254. …Let’s put everything together
- 255. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Build a Graph-based Data Model
- 256. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Build a Graph-based Data Model Work on Vector Space Model Work on Vector Space Model
- 257. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Build a Graph-based Data Model Work on Vector Space Model Work on Vector Space Model Can Exogenous and Endogenous approaches be combined?
- 258. Exogenous Approaches as Entity Linking and WSD work on the row of the matrix …Let’s put everything together
- 259. Exogenous Approaches as Entity Linking and WSD work on the row of the matrix …Let’s put everything together Endogenous Approaches as ESA or Word2Vec work on the columns of the matrix
- 260. Exogenous Approaches as Entity Linking and WSD work on the row of the matrix …Let’s put everything together Endogenous Approaches as ESA or Word2Vec work on the columns of the matrix Both approaches can be combined to obtain richer and more precise semantic representations (e.g. Word2Vec over textual description processed with WSD)
- 262. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Word Sense Disambiguation Entity Linking ……. Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 263. synsets {09596828} American -- (a native or inhabitant of the United States) {06281561} fiction -- (a literary work based on the imagination and not necessarily on fact) {06525881} movie, film, picture, moving picture, moving-picture show, motion picture, motion-picture show, picture show, pic, flick -- (a form of entertainment that enacts a story… {02605965} star -- (feature as the star; "The movie stars Dustin Hoffman as an autistic man") The Matrix representation through WSD we process the textual description of the item and we obtain a semantics- aware representation of the item as output. In this case, keyword-based features are replaced with the concepts (in this case, a WordNet synset) they refer to. Matrix 1999 American Australian fiction world keywords science Hugo
- 264. Synset-based representation AI Artificial Intelligence apple M. Degemmis, P. Lops, and G. Semeraro. A Content-collaborative Recommender that Exploits WordNet-based User Profiles for Neighborhood Formation. User Modeling and User-Adapted Interaction: The Journal of Personalization Research (UMUAI), 17(3):217–255, Springer Science + Business Media B.V., 2007. G. Semeraro, M. Degemmis, P. Lops, and P. Basile. Combining Learning and Word Sense Disambiguation for Intelligent User Profiling. In M. M. Veloso, editor, IJCAI 2007, Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, January 6- 12, 2007 , pages 2856–2861. Morgan Kaufmann, 2007. M.Degemmis, P. Lops, G. Semeraro, Pierpaolo Basile: Integrating tags in a semantic content-based recommender ACM Conference on Recommender Systems, RecSys 2008: 163-170
- 265. Keywords- vs synsets-based profiles EachMovie dataset o 1,628 movies grouped into 10 categories o Users who rated between 30 and 100 movies o Movie content crawled from IMDb
- 266. In the context of cultural heritage personalization, does the integration of UGC and textual description of artwork collections cause an increase of the prediction accuracy in the process of recommending artifacts to users? Results in a cultural heritage scenario In RecSys ’08, Proceed. of the 2nd ACM Conference on Recommender Systems, pages 163–170, October 23-25, 2008, Lausanne, Switzerland, ACM, 2008.
- 267. Results in a cultural heritage scenario 5-point rating scale Textual description of items (static content) Personal Tags Social Tags (from other users): caravaggio, deposition, christ, cross, suffering, religion Social Tags passion
- 268. Results in a cultural heritage scenario Personal Tags Static Content Social Tags
- 269. Results in a cultural heritage scenario o Artwork representation o Artist o Title o Description o Tags o change of text representation from vectors of words (BOW) into vectors of WordNet synsets (BOS) o From tags to semantic tags o supervised Learning o Bayesian Classifier learned from artworks labeled with user ratings and tags
- 270. Results in a cultural heritage scenario * Results averaged over the 30 study subjects Augmented Profiles Content-based Profiles Tag-based Profiles Overall accuracy F1 ≈ 85%
- 271. Results in a cultural heritage scenario personalized museum tours by arranging the most interesting items for the active user step forward to take into account spatial layout & time constraint L. Iaquinta, M. de Gemmis, P. Lops, G. Semeraro: Recommendations toward Serendipitous Diversions. ISDA 2009: 1049-1054
- 272. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Ontologies Linked Open Data Introduce semantics by linking the Item to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 273. Semantic Analysis using Ontologies Quickstep & Foxtrot o on-line academic research papers recommenders o items and user profiles represented through a research topic ontology o is-a relationships exploited to infer general interests when specific topics are observed o match based on the correlation between the topics in the user profile and topics in papers ACM Transactions on Information Systems, 22(1):54–88, 2004
- 274. Semantic Analysis using Ontologies . In W. Nejdl, J. Kay, P. Pu, and E. Herder, editors, Adaptive Hypermedia and AdaptiveWeb-Based Systems, volume 5149 of Lecture Notes in Computer Science, pages 279–283. Springer, 2008. News@hand
- 275. Semantic Analysis using Ontologies o user interests propagation from concepts which received the user feedback to others related ones though spreading activation o contextualized propagation strategies of user interests horizontal propagation among siblings anisotropic vertical propagation, i.e. user interests propagated differently upward and downward . Inf. Sci., 250:40–60, 2013.
- 276. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Ontologies Linked Open Data Introduce semantics by linking the Item to a knowledge graph ……. Introduce semantics by mapping the features describing the item with semantic concepts
- 277. Linked Open Data & RecSys structured information source for item descriptions
- 278. LOD & Recommender Systems Vector Space Model for LOD Tommaso Di Noia, Roberto Mirizzi, Vito Claudio Ostuni, Davide Romito, Markus Zanker. Linked Open Data to support Content-based Recommender Systems. 8th International Conference on Semantic Systems (I-SEMANTICS) - 2012 (Best Paper Award)
- 279. LOD & Recommender Systems Vector Space Model for LOD Tommaso Di Noia, Roberto Mirizzi, Vito Claudio Ostuni, Davide Romito, Markus Zanker. Linked Open Data to support Content-based Recommender Systems. 8th International Conference on Semantic Systems (I-SEMANTICS) - 2012 (Best Paper Award) (starring, directors, subject, etc.)
- 280. LOD & Recommender Systems Property subset evaluation subject+broader solution better than only subject or subject+more broaders too many broaders introduce noise best solution achieved with subject+broader+genres Tommaso Di Noia, Roberto Mirizzi, Vito Claudio Ostuni, Davide Romito, Markus Zanker. Linked Open Data to support Content-based Recommender Systems. 8th International Conference on Semantic Systems (I-SEMANTICS) - 2012 (Best Paper Award)
- 281. Graph-based RecSys Recommendations obtained by mining the graph
- 282. Graph-based RecSys Recommendations obtained by mining the graph Identification of the most relevant (target) nodes, according to the recommendation scenario
- 283. Graph-based RecSys Recommendations obtained by mining the graph Identification of the most relevant (target) nodes, according to the recommendation scenario PageRank Spreading Activation Personalized PageRank … Cataldo Musto, Pasquale Lops, Pierpaolo Basile, Marco De Gemmis, Giovanni Semeraro. . UMAP 2016
- 284. Graph-based RecSys Personalized PageRank [*] to identify the most relevant nodes in the graph [*] T. H. Haveliwala. Topic- Sensitive PageRank: A Context-Sensitive Ranking Algorithm for Web Search. IEEE Trans. Knowl. Data Eng., 15(4):784–796, 2003.
- 285. Graph-based RecSys MovieLens 100K dataset G = Personalized PageRank on Bipartite User-Item Graph G+LOD = Tripartite Graph modeling also Linked Open Data
- 286. Graph-based RecSys is it necessary to inject all the properties available in LOD cloud?
- 287. Graph-based RecSys is it necessary to inject all the properties available in LOD cloud?
- 288. Graph-based RecSys is it necessary to inject all the properties available in LOD cloud?
- 289. Graph-based RecSys what are the most promising properties to include? manual selection o domain-specific properties o most frequent properties o … automatic selection o more difficult to implement Cataldo Musto, Pasquale Lops, Pierpaolo Basile, Marco De Gemmis, Giovanni Semeraro. . UMAP 2016
- 290. Feature selection selecting the most promising subset of LOD-based properties possible techniques PageRank Principal Component Analysis Information Gain Information Gain Ratio Mininum Redundancy Maximum Relevance
- 291. Graph-based RecSys tradeoff between accuracy and diversity MovieLens 100K dataset
- 292. Graph-based RecSys Comparison to state of the art MovieLens 100K dataset
- 293. we can further build some extra features by mining the paths occurring in the graph path acyclic sequence of relations ( s , .. rl , .. rL ) frequency of pathj in the sub-graph related to u ad x u3 s i2 p2 e1 p1 i1 (s, p2 , p1) 𝑤 𝑢𝑥(𝑗) = #𝑝𝑎𝑡ℎ 𝑢𝑥(𝑗) #𝑝𝑎𝑡ℎ 𝑢𝑥(𝑗)𝑗 Semantic Graph-based Data Model (Path Based Features) Vito Claudio Ostuni, Tommaso Di Noia, Eugenio Di Sciascio, Roberto Mirizzi: Top-N recommendations from implicit feedback leveraging linked open data. RecSys 2013: 85-92
- 294. LOD & Recommender Systems Sprank Systems o analysis of complex relations between user preferences and the target item o extraction of path-based features Vito Claudio Ostuni, Tommaso Di Noia, Eugenio Di Sciascio, Roberto Mirizzi: Top-N recommendations from implicit feedback leveraging linked open data. RecSys 2013: 85-92
- 295. wu3X1 ? Semantic Graph-based Data Model (Path Based Features)
- 296. path1 (s, s, s) : 1 Semantic Graph-based Data Model (Path Based Features)
- 297. path1 (s, s, s) : 2 Semantic Graph-based Data Model (Path Based Features)
- 298. path1 (s, s, s) : 2 path2 (s, p2, p1) : 1 Semantic Graph-based Data Model (Path Based Features)
- 299. path1 (s, s, s) : 2 path2 (s, p2, p1) : 2 Semantic Graph-based Data Model (Path Based Features)
- 300. path1 (s, s, s) : 2 path2 (s, p2, p1) : 2 path3 (s, p2, p3, p1) : 1 Semantic Graph-based Data Model (Path Based Features)
- 301. path1 (s, s, s) : 2 path2 (s, p2, p1) : 2 path3 (s, p2, p3, p1) : 1 𝑤 𝑢3 𝑥1 1 = 2 5 𝑤 𝑢3 𝑥1 2 = 2 5 𝑤 𝑢3 𝑥1 3 = 1 5 Semantic Graph-based Data Model (Path Based Features)
- 303. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 304. Word2Vec • Empirical Comparison of Word Embedding Techniques for Content-based Recommender Systems [*] • Methodology • Build a WordSpace using different Word Embedding techniques (and different sizes) • Build a DocSpace as the centroid vectors of term vectors • Build User Profiles as centroid of the items they liked • Provide Users with Recommendations • Compare the approaches European Conference on Information Retrieval
- 305. Word2Vec Results on Dbbook and MovieLens data European Conference on Information Retrieval
- 306. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 307. eVSM • Enhanced Vector Space Model [*] • Content-based Recommendation Framework • Cornerstones • Semantics modeled through Distributional Models • Random Indexing for Dimensionality Reduction • Negative Preferences modeled through Quantum Negation [^] • User Profiles as centroid vectors of items representation • Recommendations through Cosine Similarity [*] Musto, Cataldo. "Enhanced vector space models for content-based recommender systems." Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010. Mathematics of language
- 308. eVSM Musto, Cataldo. "Enhanced vector space models for content-based recommender systems." Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010. Distributional Models to build DocSpace of the items (whole document used as context) Random Indexing for Dimensionality Reduction
- 309. eVSM Cornerstones • Given two vectors a e b • Through Quantum Negation we can define a Vector (a ∧¬b) • Formally: • Projection of vector a on the subspace orthogonal to that generated by vector b • Intuitively: • Vector «a» models «positive» preferences • Vector «b» models «negative» preferences • Through quantum negation we get a unique vector modeling both aspects • Close to vectors containing as many as possible features from «a» and as less as possible features from «b» Mathematics of language
- 310. eVSM • User Profiles • Calculated as centroid vectors of the items the user liked/disliked Random Indexing- based Profiles (RI) Musto, Cataldo. "Enhanced vector space models for content-based recommender systems." Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010.
- 311. eVSM Cornerstones • User Profiles • Calculated as centroid vectors of the items the user liked/disliked Random Indexing- based Profiles (W-RI) Quantum Negation- based Profiles (W-QN) Musto, Cataldo. "Enhanced vector space models for content-based recommender systems." Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010.
- 312. eVSM Cornerstones • Recommendations • Similarity Calculations on DocSpace
- 313. eVSM Experiments The size of the embeddings does not significantly affect the overall accuracy of eVsm (MovieLens data)
- 314. eVSM Experiments Quantum Negation improves the accuracy of the model (MovieLens data, embedding size=100)
- 315. eVSM Experiments eVSM significantly overcame all the baselines. (MovieLens data, embedding size=400)
- 316. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph Word Sense Disambiguation Entity Linking
- 317. C-eVSM • Contextual Enhanced Vector Space Model [*] • Extension of eVSM: context-aware Framework • Cornerstones • Entity Linking of the content through Tag.me • Semantics modeled through Distributional Models • Random Indexing for Dimensionality Reduction • Distributional Models also used to build a representation of the context • Context-aware User Profiles as centroid vectors • Recommendations through Cosine Similarity Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014
- 318. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 α α Let u be the target user Let ck be a contextual variable (e.g. task, mood, etc.) Let vj be its value (e.g. task=running, mood=sad, etc.)
- 319. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 α α eVSM profile
- 320. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 C-WRI(u,c k ,v j ) = α * WRI(u) + (1-α) * context(u,c k ,v j ) eVSM profile A Vector representing value v for context c is introduced (e.g. company=friends)
- 321. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 C-WRI(u,c k ,v j ) = α * WRI(u) + (1-α) * context(u,c k ,v j ) eVSM profile A Vector representing value v for context c is introduced (e.g. company=friends) Linear Combination (a=1 eVSM no context taken into account)
- 322. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 C-WRI(u,c k ,v j ) = α * WRI(u) + (1-α) * context(u,c k ,v j ) eVSM profile A Vector representing value v for context c is introduced (e.g. company=friends) Linear Combination (a=1 eVSM no context taken into account)
- 323. C-eVSM • Context-aware User Profiles Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 C-WRI(u,c k ,v j ) = α * WRI(u) + (1-α) * context(u,c k ,v j ) eVSM profile A Vector representing value v for context c is introduced (e.g. company=friends) Why this formula?
- 324. C-eVSM • Why this formula? Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 Insight: it exists a set of terms that is more descriptive of items relevant in that specific context for a romantic dinner, e.g. candlelight, seaview, violin
- 325. C-eVSM • Why this formula? Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014
- 326. C-eVSM • Why this formula? Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 Thanks to Distributional Semantics Models it is possible to build a vector-space representation of the context which emphasize the importance of those terms, since they are more used ( more important) in that specific contextual setting.
- 327. C-eVSM Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014
- 328. C-eVSM Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014
- 329. C-eVSM Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014
- 330. C-eVSM Musto, Cataldo, et al. "Combining distributional semantics and entity linking for context-aware content-based recommendation." International Conference on User Modeling, Adaptation, and Personalization. UMAP 2014 Entities are better than simple keywords! Selection of Results
- 331. C-eVSM Incorporating contextual information in recommender systems using a multi- dimensional approach Compared to Context-aware Collaborative Filtering (CACF) [*] algorithm: better in 7 contextual segments
- 332. Semantic representations Explicit (Exogenous) Semantics Implicit (Endogenous) Semantics Explicit Semantic Analysis Random Indexing ……Word2Vec Distributional semantic models Introduce semantics by mapping the features describing the item with semantic concepts Introduce semantics by linking the Item to a knowledge graph
- 333. Text Categorization [Gabri09] experiments on diverse datasets Semantic relatedness of words and texts [Gabri09] cosine similarity between vectors of ESA concepts Information Retrieval [Egozi08, Egozi11] ESA-based IR algorithm enriching documents and queries ESA effectively used for [Gabri09] E. Gabrilovich and S. Markovitch. Wikipedia-based Semantic Interpretation for Natural Language Processing. Journal of Artificial Intelligence Research 34:443-498, 2009. [Egozi08] Ofer Egozi, Evgeniy Gabrilovich, Shaul Markovitch: Concept-Based Feature Generation and Selection for Information Retrieval. AAAI 2008, 1132-1137, 2008. [Egozi11] Ofer Egozi, Shaul Markovitch, Evgeniy Gabrilovich. Concept-Based Information Retrieval using Explicit Semantic Analysis. ACM Transactions on Information Systems 29(2), April 2011. 370 what about ESA for Information Filtering?
- 334. Electronic Program Guides problem description of TV shows too short or poorly meaningful to feed a content-based recommendation algorithm solution Explicit Semantic Analysis exploited to obtain an enhanced representation [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 372
- 335. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 373
- 336. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 374
- 337. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 375 Wikipedia Articles related to the TV show are added to the description
- 338. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 376 user profile tv show motogp sports motorbike ... competition 2012 Superbike Italian Grand Prix
- 339. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 377 user profile tv show motogp sports motorbike ... competition 2012 Superbike Italian Grand Prix XNo matching!
- 340. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 378 user profile tv show 2012 Superbike Italian Grand Prix motogp superbike sports motorbike formula 1 … competition Through ESA we can add new features to the profile and we can improve the overlap between textual description
- 341. Electronic Program Guides [Musto12] C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, and R. Clout. Enhanced semantic tv-show representation for personalized electronic program guides. UMAP 2012, pp. 188–199. Springer, 2012 379 user profile tv show 2012 Superbike Italian Grand Prix motogp superbike sports motorbike formula 1 … competition Matching! ✔
- 342. Electronic Program Guides 380 results on Aprico.tv data The more Wikipedia Concepts are added to the textual description of the items (eBOW+60), the best the precision of the algorithm eBOW = Bag of Words + Wikipedia Concepts
- 343. Semantics User Profiles • Research Question • Is it possible to exploit semantic representation techniques to improve the quality of user profiles? • Methodology • Build User Profiles by extracting data available from social networks • Process User Profiles through Semantics-aware Techniques • Evaluate the effectiveness of the profiles • Accuracy • Transparency • Serendipity Narducci, F., Musto, C., Semeraro, G., Lops, P., & de Gemmis, M. (2013, August). Exploiting big data for enhanced representations in content-based recommender systems. In International Conference on Electronic Commerce and Web Technologies (pp. 182- 193). Springer Berlin Heidelberg.
- 344. Semantics User Profiles • Techniques • Keyword-based Profiles • Entity Linking (Tag.me) • Explicit Semantic Analysis • Scenario I’m in trepidation for my first riding lesson!, I’m really anxious for the soccer match :( , This summer I will flight by Ryanair to London!, Ryanair really cheapest company!, Ryanair lost my luggage :(, This summer holidays are really amazing!, Total relax during these holidays!
- 345. Semantics User Profiles Results – Experiment 1 • User Study involving 63 users • Twitter and Facebook as Social Networks • Users were provided with a set of personalized news • Answers gathered through User Feedback on recommended news
- 346. Semantics User Profiles Results – Experiment 1 • User Study involving 63 users • Twitter and Facebook as Social Networks • Users were provided with a set of personalized news • Answers gathered through User Feedback on recommended news No relevance feedback Avg. rating Min rating Max rating Std. Dev. 1.49 0 5 1.12 1.89 0 5 1.47 2.86 1 5 1.30 2.59 0 5 1.37
- 347. Semantics User Profiles Transparency Serendipity KEYWORDS 1.33 0 3 0.65 0.42 0 2 0.57 TAG.ME 3.88 2 5 0.82 0.54 0 2 0.61 ESA 1.16 0 4 1.00 3.24 0 5 1.24 Results – Experiment 2 • User Study involving 51 users • Twitter and Facebook as Social Networks • Users were provided with a tag cloud describing their profile • Answers gathered through Questionnaires
- 349. Cross-lingual access: motivations relevant information exist in different languages Web is becoming more and more multilingual users are becoming increasing polyglot more than half of the world population bilingual cross-language recommender systems can likely increase the number of tail products suggested (25-30% of sales for online stores) 387
- 350. Cross-lingual access: problems Vocabulary mismatch use of different languages extreme case of vocabulary mismatch 388
- 351. Semantic analytics for cross-lingual access Sense-based representations inherently multilingual terms in each specific language change, while concepts (word meanings) remain the same across different languages match between items and user profiles at a conceptual level
- 353. MultiWordNet 392 Sense-based representations Word Sense Disambiguation (JIGSAW) based on Multiwordnet as sense repository multilingual lexical database that supports English, Italian, Spanish, Portuguese, Hebrew, Romanian, Latin alignment between synsets in the different languages semantic relations imported and preserved
- 354. MultiWordNet 393
- 355. 394 Bag of MultiWordNet synsets bag of MultiWordNet synsets bag of MultiWordNet synsets Match between senses
- 356. Some results cross-language movie recommendation scenario profiles learned from ENG/ITA descriptions recommendation provided on ITA/ENG descriptions MovieLens dataset, F1 measure, Wikipedia source for descriptions 395
- 359. Cross-lingual representation: Tagme Film d’azione Lana e Lilly Wachowskis Laurence Fishburne Keanu Reeves distopia … action film TheWachowskis Keanu Reeves Laurence Fishburne Dystopia Perception Carrie-Anne Moss Cyberspace …
- 360. Text Language L1 Text Language Ln Text Language L2 … Translated Text PIVOT LANGUAGE C1 C2 C3 … … Cn t1 t2 … tk ESA MATRIX PIVOT LANGUAGE Wikipedia articles Termsoccurringin Wikipediaarticles TF-IDF TRANSLATION PROCESS Cross-lingual representation: ESA Translation-based ESA
- 361. ESA MATRIX L1 C1-L1 C2-L1 … Cn-L1 ESA MATRIX L2 C1-L2 C2-L2 … Cn-L2 ESA MATRIX LN C1-LN C2-LN … Cn-LN ESA MATRIX LN C1-LN C2-LN … Cn-LN … Text LanguageL1 Text LanguageLn Text LanguageL2 … Cross-lingual representation: ESA Cross-language ESA
- 363. Preliminary results effectiveness of knowledge-based strategies to provide cross-lingual recommendations MovieLens and DBbook datasets F1 measure, Wikipedia source for descriptions English and Italian languages 406
- 364. Cross-lingual representation: Distributional models distribution of the terms (almost) the same in different languages o cross-lingual representation comes with no costs thanks to the distributional hypothesis
- 365. Distributional Semantics …. is also multilingual! (Recap) Italian WordSpace English WordSpace glass spoon dog beer cucchiaio cane birra bicchiere The position in the space can be slightly different, but the relations similarity between terms still hold
- 366. Distributional Semantics Multilingual DocSpace Italian DocSpace English DocSpace D2_L1 D3_L1 D4_L1 D1_L1 D7_L2 D8_L2 D5_L2 D6_L2 By following the same procedure we can obtain a multilingual DocSpace Different documents in different languages are represented in a uniform space
- 367. Distributional Semantics …. is also multilingual! Italian DocSpace English DocSpace D2_L1 D3_L1 D4_L1 D1_L1 D7_L2 D8_L2 D5_L2 D6_L2 By following the same procedure we can obtain a multilingual DocSpace How to build a cross-lingual recommender?
- 368. Distributional Semantics …. is also multilingual! Italian DocSpace English DocSpace D2_L1 D3_L1 D4_L1 D1_L1 D7_L2 D8_L2 D5_L2 D6_L2 P1 We build a user profile in L1 (Italian DocSpace) How to build a cross-lingual recommender?
- 369. Distributional Semantics …. is also multilingual! Italian DocSpace English DocSpace D2_L1 D3_L1 D4_L1 D1_L1 D7_L2 D8_L2 D5_L2 D6_L2 P1 P1 We build a user profile in L1 (Italian DocSpace) We can «move» the profile in L2 (EnglishDocSpace) How to build a cross-lingual recommender?
- 370. Distributional Semantics …. is also multilingual! Italian DocSpace English DocSpace D2_L1 D3_L1 D4_L1 D1_L1 D7_L2 D8_L2 D5_L2 D6_L2 We build a user profile in L1 (Italian DocSpace) We can «move» the profile in L2 (EnglishDocSpace) We can use similarity measures to suggest items in different language How to build a cross-lingual recommender? P1 P1
- 371. Some results effectiveness of knowledge-based strategies to provide cross-lingual recommendations MovieLens dataset F1 measure comparable results (gap not statistically significant) 414 C. Musto, F. Narducci, P. Basile, P. Lops, M. de Gemmis, G. Semeraro:"Cross-language information filtering: Word sense disambiguation vs. distributional models." AI*IA 2011: 250-261
- 373. Graph-based RecSys: explanations are properties useful for providing explanations? advantages readability of properties … disadvantages difficult to generate natural language explanations selection of the properties to include in the explanation
- 374. Graph-based RecSys: explanations main intuition of the EXPLOD system o graph connecting user preferences and recommendations through a set of LOD-based properties o scoring and ranking properties Cataldo Musto, Fedelucio Narducci , Pasquale Lops, Marco de Gemmis, Giovanni Semeraro: . RecSys 2016, to appear
- 375. Scoring properties in EXPLOD items in the user profile items in the recommendation list property number of edges connecting the propertyc with the items in the user profile number of edges connecting the propertyc with the items in the recommendation set Graph-based RecSys: explanations
- 376. Scoring properties in EXPLOD weighting factors adaptation of the Inverse Document Frequency Graph-based RecSys: explanations
- 377. Scoring properties in EXPLOD higher score to properties highly connected to the items in both the user profile and the recommendation list, and which are not common. Graph-based RecSys: explanations
- 378. From properties to Natural Language explanation I recommend you The Dark Knight because you often like Films shot in the United Kingdom as Inception and Forrest Gump. In addition, you sometimes like Films produced by Christopher Nolan as Inception and Screenplays by Christopher Nolan as Inception Graph-based RecSys: explanations
- 379. From properties to Natural Language explanation o top-ranked properties to fill in a template-based structure of the explanation o LOD cloud-properties mapped to natural language expressions o adverbs obtained by mapping the normalized occurrence of that property to a different range of the score Graph-based RecSys: explanations
- 380. Graph-based RecSys: explanations preliminary results aim question transparency I understood why this movie was recommended to me o topic o director o distributor o music composer persuasion The explanation made the recommendation more convincing o awards o director o location o producer engagement The explanation helped me discover new information about this movie o writer o director o producer o distributor trust The explanation increased my trust in the recommender system o awards o composer o producer o topic effectiveness I like this recommendation o director o writer o location o composer user study involving 308 subjects
- 381. What? Semantic analysis of social streams
- 382. Social Networks novel data silos
- 383. Goal To design a unique framework implementing a pipeline of semantic analysis techniques
- 384. Our Contribution: CrowdPulse Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 385. Our Contribution: CrowdPulse Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 386. CrowdPulse Workflow Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 387. CrowdPulse Workflow Each «project» is an instance of such a workflow Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 388. CrowdPulse Workflow Each «project» is an instance of such a workflow Every module is set according to the needs of the scenario Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 389. CrowdPulse Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 390. CrowdPulse Solution: Entity Linking Algorithms Input: textual content Output: identification and disambiguation of the entities mentioned in the text. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 391. CrowdPulse Solution: Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 392. CrowdPulse Solution: Overall sentiment: :-( We implemented: • A lexicon-based approach, which assigns a sentiment according to the words in the social content • A supervised classification algorithm, which exploits labeled examples to learn a classification model Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 393. Supervised learning Unsupervised learning Linguistic Analysis (Distributional Models) classification, regression tasks clustering building word spaces, similarity between concepts, analysis of terms usage, etc. CrowdPulse Step 4: Domain-Specific Processing CrowdPulse natively supports all these methodologies The choice is typically scenario-dependent Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 394. CrowdPulse Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 395. CrowdPulse Workflow Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. (recap)
- 396. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 397. Research Question: Is it possible to extract and process social media to monitor in real time people feelings, opinions and sentiments about the current state of the social capital of L’Aquila? Use Case L’Aquila Social Urban Network Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 398. 4 Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network
- 399. Use Case L’Aquila Social Urban Network Heuristics: - Twitter users (local newspapers, mention to politicians) - Twitter content+geo (50km around l’Aquila and/or specific hashtags as #laquila #earthquake, etc) Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 400. Use Case L’Aquila Social Urban Network Extracted Content Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 401. Use Case L’Aquila Social Urban Network Semantic and Sentiment Analysis of Extracted Content Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146.
- 402. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network Domain-specific Task Given a piece of social content, we have to classify it against the social indicators
- 403. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network Classification Task Build a supervised classification model for each social indicator
- 404. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network Input: Tweet + Social Indicators Classification Model
- 405. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network Output: Social Indicators and Sentiment conveyed
- 406. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network The «score» of a social Indicator is the sum of the Sentiment conveyed by the Tweets
- 407. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network Overall score of the social indicators between March and August 2014
- 408. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case L’Aquila Social Urban Network COMMUNITY PROMOTER DEFINES SOME INITIATIVES TO EMPOWER THE SOCIAL CAPITAL MONITORS THE STATE OF THE SOCIAL INDICATORS Connecting Real Communities With Virtual Communities
- 409. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map http://users.humboldt.edu/mstephens/hate/hate_map.html Inspired by the Hate Map built by the Humboldt University Is it possible to exploit techniques for semantic analysis of social media to detect intolerant content posted on social networks and identify the most at-risk areas of the Italian country? Research Question
- 410. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Heuristics: Twitter content - 76 intolerant seed terms, defined by the psychologists teams - 5 intolerance dimensions: violence (against women), racism, homophobia, disability, anti-semitism
- 411. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Many non-intolerant Tweets are extracted! X X
- 412. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Solution: replace a simple keyword-based approach with a supervised classification model X X
- 413. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Entities and Wikipedia categories used as features
- 414. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Sample of Tweet is manually labeled to build classification models
- 415. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map
- 416. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Tweet about an Italian ministry Tweet about an Italian football player Violence against women Disability Racism Homophobia
- 417. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. Use Case The Italian Hate Map Given the maps and given the output of the linguistic analysis of intolerant Tweets (co-occurrences between terms, time lapse, etc.), the psychologists team defined some guidelines to tackle and prevent intolerant behaviors. These guidelines have been freely distributed to public administrations on early 2015.
- 418. Musto, Cataldo, et al. CrowdPulse: A framework for real-time semantic analysis of social streams Information Systems, 54 (2015): 127-146. CrowdPulse Lessons Learned Pipeline of state of the art techniques Entity Linking, Sentiment Analysis, Machine Learning, Data Visualization Use Cases. L’Aquila Social Urban Network The Italian Hate Map REAL-TIME SEMANTIC CONTENT ANALYSIS 1. 2. The outcomes of both use cases showed that very complex phenomena can be analyzed in a totally new way, thanks to the huge availability of textual data
- 419. Readings Semantics-aware Recommender Systems o C. Musto, G. Semeraro, M. de Gemmis, P. Lops: Learning Word Embeddings from Wikipedia for Content- Based Recommender Systems. ECIR 2016: 729-734 o M. de Gemmis, P. Lops, C. Musto, F.Narducci, G. Semeraro: Semantics-Aware Content-Based Recommender Systems. Recommender Systems Handbook 2015: 119-159 o C. Musto, G. Semeraro, M. de Gemmis, P. Lops: Word Embedding Techniques for Content-based Recommender Systems: An Empirical Evaluation. RecSys Posters 2015 o C. Musto, P. Basile, M. de Gemmis, P. Lops, G. Semeraro, S. Rutigliano: Automatic Selection of Linked Open Data Features in Graph-based Recommender Systems. CBRecSys@RecSys 2015: 10-13 o P. Basile, C. Musto, M. de Gemmis, P. Lops, F. Narducci, G. Semeraro: Content-Based Recommender Systems + DBpedia Knowledge = Semantics-Aware Recommender Systems. SemWebEval@ESWC 2014: 163-169 o C. Musto, P. Basile, P. Lops, M. de Gemmis, G. Semeraro: Linked Open Data-enabled Strategies for Top-N Recommendations. CBRecSys@RecSys 2014: 49-56 o C. Musto, G. Semeraro, P. Lops, M. de Gemmis: Combining Distributional Semantics and Entity Linking for Context-Aware Content-Based Recommendation. UMAP 2014: 381-392 o C. Musto, G. Semeraro, P. Lops, M. de Gemmis: Contextual eVSM: A Content-Based Context-Aware Recommendation Framework Based on Distributional Semantics. EC-Web 2013: 125-136 o C. Musto, F. Narducci, P. Lops, G. Semeraro, M. de Gemmis, M. Barbieri, J. H. M. Korst, V. Pronk, R. Clout: Enhanced Semantic TV-Show Representation for Personalized Electronic Program Guides. UMAP 2012: 188-199 o M. Degemmis, P. Lops, G. Semeraro: A content-collaborative recommender that exploits WordNet-based user profiles for neighborhood formation. User Model. User-Adapt. Interact. 17(3): 217-255 (2007) o G. Semeraro, M. Degemmis, P. Lops, P. Basile: Combining Learning and Word Sense Disambiguation for Intelligent User Profiling. IJCAI 2007: 2856-2861
- 420. Readings Cross-language Recommender Systems o C. Musto, F. Narducci, P. Basile, P. Lops, M. de Gemmis, G. Semeraro: Cross-Language Information Filtering: Word Sense Disambiguation vs. Distributional Models. AI*IA 2011: 250-261 o P. Lops, C. Musto, F. Narducci, M. de Gemmis, P. Basile, G. Semeraro: Cross-Language Personalization through a Semantic Content-Based Recommender System. AIMSA 2010: 52-60 Explanations o C. Musto, F. Narducci, P. Lops, M. de Gemmis, G. Semeraro: ExpLOD: a framework for Explaining Recommendations based on the Linked Open Data cloud. RecSys 2016, to appear Semantic Analysis of Social Streams o C. Musto, G. Semeraro, P. Lops, M. de Gemmis: CrowdPulse: A framework for real-time semantic analysis of social streams. Inf. Syst. 54: 127-146 (2015)