


















![Vestigial abstractions
Many optimizations are simply not feasible when
functions are present
int replace(int* ptr, int value) { void *malloc(size_t size) {
int tmp = *ptr; void *ret;
*ptr = value; // [various checks]
return tmp; ret = imalloc(size);
} if (ret == NULL)
errno = ENOMEM;
int A(int* ptr, int value) { return ret;
return replace(ptr, value); }
}
// ...
int B(int* ptr, int value) { type *ptr = malloc(size);
replace(ptr, value); if (ptr == NULL)
return value; return NOT_ENOUGH_MEMORY;
} // ...](https://image.slidesharecdn.com/compileroptimizations-110928074259-phpapp01/85/Compiler-optimizations-based-on-call-graph-flattening-21-320.jpg)











































Compiler optimizations based on call-graph flattening
- 1. Compiler optimizations based on call-graph flattening Carlo Alberto Ferraris professor Silvano Rivoira Master of Science in Telecommunication Engineering Third School of Engineering: Information Technology Politecnico di Torino July 6th, 2011
- 2. Increasing complexities Everyday objects are becoming multi-purpose networked interoperable customizable reusable upgradeable
- 3. Increasing complexities Everyday objects are becoming more and more complex
- 4. Increasing complexities Software that runs smart objects is becoming more and more complex
- 5. Diminishing resources Systems have to be resource-efficient
- 6. Diminishing resources Systems have to be resource-efficient Resources come in many different flavours
- 7. Diminishing resources Systems have to be resource-efficient Resources come in many different flavours Power Especially valuable in battery-powered scenarios such as mobile, sensor, 3rd world applications
- 8. Diminishing resources Systems have to be resource-efficient Resources come in many different flavours Power, density Critical factor in data-center and product design
- 9. Diminishing resources Systems have to be resource-efficient Resources come in many different flavours Power, density, computational CPU, RAM, storage, etc. are often growing slower than the potential applications
- 10. Diminishing resources Systems have to be resource-efficient Resources come in many different flavours Power, density, computational, development Development time and costs should be as low as possible for low TTM and profitability
- 11. Diminishing resources Systems have to be resource-efficient Resources come in many non-orthogonal flavours Power, density, computational, development
- 12. Do more with less
- 13. Abstractions We need to modularize and hide the complexity Operating systems, frameworks, libraries, managed languages, virtual machines, …
- 14. Abstractions We need to modularize and hide the complexity Operating systems, frameworks, libraries, managed languages, virtual machines, … All of this comes with a cost: generic solutions are generally less efficient than ad-hoc ones
- 15. Abstractions We need to modularize and hide the complexity Palm webOS User interface running on HTML+CSS+Javascript
- 16. Abstractions We need to modularize and hide the complexity Javascript PC emulator Running Linux inside a browser
- 17. Optimizations We need to modularize and hide the complexity without sacrificing performance
- 18. Optimizations We need to modularize and hide the complexity without sacrificing performance Compiler optimizations trade off compilation time with development, execution time
- 19. Vestigial abstractions The natural subdivision of code in functions is maintained in the compiler and all the way down to the processor Each function is self-contained with strict conventions regulating how it relates to other functions
- 20. Vestigial abstractions Processors don’t care about functions; respecting the conventions is just additional work Push the contents of the registers and return address on the stack, jump to the callee; execute the callee, jump to the return address; restore the registers from the stack
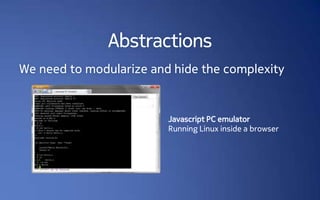
- 21. Vestigial abstractions Many optimizations are simply not feasible when functions are present int replace(int* ptr, int value) { void *malloc(size_t size) { int tmp = *ptr; void *ret; *ptr = value; // [various checks] return tmp; ret = imalloc(size); } if (ret == NULL) errno = ENOMEM; int A(int* ptr, int value) { return ret; return replace(ptr, value); } } // ... int B(int* ptr, int value) { type *ptr = malloc(size); replace(ptr, value); if (ptr == NULL) return value; return NOT_ENOUGH_MEMORY; } // ...
- 22. Vestigial abstractions Many optimizations are simply not feasible when functions are present interpreter_setup(); while (opcode = get_next_instruction()) interpreter_step(opcode); interpreter_shutdown(); function interpreter_step(opcode) { switch (opcode) { case opcode_instruction_A: execute_instruction_A(); break; case opcode_instruction_B: execute_instruction_B(); break; // ... default: abort("illegal opcode!"); } }
- 23. Vestigial abstractions Many optimization efforts are directed at working around the overhead caused by functions Inlining clones the body of the callee in the caller; optimal solution w.r.t. calling overhead but causes code size increase and cache pollution; useful only on small, hot functions
- 25. Call-graph flattening What if we dismiss functions during early compilation…
- 26. Call-graph flattening What if we dismiss functions during early compilation and track the control flow explicitely instead?
- 27. Call-graph flattening What if we dismiss functions during early compilation and track the control flow explicitely instead?
- 28. Call-graph flattening What if we dismiss functions during early compilation and track the control flow explicitely instead?
- 29. Call-graph flattening We get most benefits of inlining without code duplication, including the ability to perform contextual code optimizations, without the code size issues
- 30. Call-graph flattening We get most benefits of inlining without code duplication, including the ability to perform contextual code optimizations, without the code size issues Where’s the catch?
- 31. Call-graph flattening The load on the compiler increases greatly both directly due to CGF itself and also indirectly due to subsequent optimizations Worse case complexity (number of edges) is quadratic w.r.t. the number of callsites being transformed (heuristics may help)
- 32. Call-graph flattening During CGF we need to statically keep track of all live values across all callsites in all functions A value is alive if it will be needed in subsequent instructions A = 5, B = 9, C = 0; // live: A, B C = sqrt(B); // live: A, C return A + C;
- 33. Call-graph flattening Basically the compiler has to statically emulate ahead-of-time all the possible stack usages of the program This has already been done on microcontrollers and resulted in a 23% decrease of stack usage (and 5% performance increase)
- 34. Call-graph flattening The indirect cause of increased compiler load comes from standard optimizations that are run after CGF CGF does not create new branches (each call and return instruction is turned into a jump) but other optimizations can
- 35. Call-graph flattening The indirect cause of increased compiler load comes from standard optimizations that are run after CGF Most optimizations are designed to operate on small functions with limited amounts of branches
- 36. Call-graph flattening Many possible application scenarios beside inlining
- 37. Call-graph flattening Many possible application scenarios beside inlining Code motion Move instructions between function boundaries; avoid unneeded computations, alleviate register pressure, improve cache locality
- 38. Call-graph flattening Many possible application scenarios beside inlining Code motion, macro compression Find similar code sequences in different parts of the code and merge them; reduce code size and cache pollution
- 39. Call-graph flattening Many possible application scenarios beside inlining Code motion, macro compression, nonlinear CF CGF supports natively nonlinear control flows; almost-zero-cost EH and coroutines
- 40. Call-graph flattening Many possible application scenarios beside inlining Code motion, macro compression, nonlinear CF, stackless execution No runtime stack needed in fully-flattened programs
- 41. Call-graph flattening Many possible application scenarios beside inlining Code motion, macro compression, nonlinear CF, stackless execution, stack protection Effective stack poisoning attacks are much harder or even impossible
- 42. Implementation To test if CGF is applicable also to complex architectures and to validate some of the ideas presented in the thesis, a pilot implementation was written against the open-source LLVM compiler framework
- 43. Implementation Operates on LLVM-IR; host and target architecture agnostic; roughly 800 lines of C++ code in 4 classes The pilot implementation can not flatten recursive, indirect or variadic callsites; they can be used anyway
- 44. Implementation Enumerate suitable functions Enumerate suitable callsites (and their live values) Create dispatch function, populate with code Transform callsites Propagate live values Remove original functions or create wrappers
- 45. Examples int a(int n) { return n+1; } int b(int n) { int i; for (i=0; i<10000; i++) n = a(n); return n; }
- 46. int a(int n) { return n+1; } int b(int n) { int i; for (i=0; i<10000; i++) n = a(n); return n; }
- 47. int a(int n) { return n+1; } int b(int n) { int i; for (i=0; i<10000; i++) n = a(n); return n; }
- 48. Examples int a(int n) { return n+1; } int b(int n) { n = a(n); n = a(n); n = a(n); n = a(n); return n; }
- 49. int a(int n) { return n+1; } int b(int n) { n = a(n); n = a(n); n = a(n); n = a(n); return n; }
- 50. .type .Ldispatch,@function .Ldispatch: movl $.Ltmp4, %eax # store the return dispather of a in rax jmpq *%rdi # jump to the requested outer disp. .Ltmp2: # outer dispatcher of b movl $.LBB2_4, %eax # store the address of %10 .Ltmp0: # outer dispatcher of a movl (%rsi), %ecx # load the argument n in ecx jmp .LBB2_4 .Ltmp8: # block %17 movl $.Ltmp6, %eax jmp .LBB2_4 .Ltmp6: # block %18 movl $.Ltmp7, %eax .LBB2_4: # block %10 movq %rax, %rsi incl %ecx # n = n + 1 movl $.Ltmp8, %eax jmpq *%rsi # indirectbr .Ltmp4: # return dispatcher of a movl %ecx, (%rdx) # store in pointer rdx the return value ret # in ecx and return to the wrapper .Ltmp7: # return dispatcher of b movl %ecx, (%rdx) ret
- 51. Fuzzing To stress test the pilot implementation and to perform benchmarks a tunable fuzzer has been written int f_1_2(int a) { a += 1; switch (a%3) { case 0: a += f_0_2(a); break; case 1: a += f_0_4(a); break; case 2: a += f_0_6(a); break; } return a; }
- 53. Benchmarks Due to the shortcomings in the currently available optimizations in LLVM, the only meaningful benchmarks that can be done are those concerning code size and stack usage In literature, average code size increases of 13% were reported due to CGF
- 54. Benchmarks Using our tunable fuzzer different programs were generated and key statistics of the compiled code were gathered
- 55. Benchmarks Using our tunable fuzzer different programs were generated and key statistics of the compiled code were gathered
- 56. Benchmarks In short, when optimizations work the resulting code size is better than the one found in literature
- 57. Benchmarks In short, when optimizations work the resulting code size is better than the one found in literature When they don’t, the register spiller and allocator perform so badly that most instructions simply shuffle data around on the stack
- 58. Benchmarks
- 59. Next steps Reduce live value verbosity Alternative indirection schemes Tune available optimizations for CGF constructs Better register spiller and allocator Ad-hoc optimizations (code threader, adaptive fl.) Support recursion, indirect calls; better wrappers
- 60. Conclusions “Do more with less”; optimizations are required CGF removes unneeded overhead due to low-level abstractions and empowers powerful global optimizations Benchmark results of the pilot implementation are better than those in literature when available LLVM optimizations can cope
- 61. Compiler optimizations based on call-graph flattening Carlo Alberto Ferraris professor Silvano Rivoira
- 64. .type wrapper,@function subq $24, %rsp # allocate space on the stack movl %edi, 16(%rsp) # store the argument n on the stack movl $.Ltmp0, %edi # address of the outer dispatcher leaq 16(%rsp), %rsi # address of the incoming argument(s) leaq 12(%rsp), %rdx # address of the return value(s) callq .Ldispatch # call to the dispatch function movl 12(%rsp), %eax # load the ret value from the stack addq $24, %rsp # deallocate space on the stack ret # return