MADlib Architecture and Functional Demo on How to Use MADlib/PivotalR
Download as PPTX, PDF2 likes950 views

This document discusses the MADlib architecture for performing scalable machine learning and analytics on large datasets using massively parallel processing. It describes how MADlib implements algorithms like linear regression across distributed database segments to solve challenges like multiplying data across nodes. It also discusses how MADlib uses a convex optimization framework to iteratively solve machine learning problems and the use of streaming algorithms to compute analytics in a single data scan. Finally, it outlines how the MADlib architecture provides scalable machine learning capabilities to data scientists through interfaces like PivotalR.



![4Pivotal Confidential–Internal Use Only
Architecture
C API
(HAWQ, GPDB, PostgreSQL)
Low-level Abstraction Layer
(array operations,
C++ to DB type-bridge, …)
RDBMS
Built-in
Functions
User Interface
Functions for Inner Loops
(implements ML logic)
SQL, generated per
specification
C++
3.&Lack&of&language&support&for&
linear&algebra&
• C++&AbstracOon&Layer&uses&Eigen&
• (Dense)&Vectors&and&matrices:&
DOUBLE PRECI SI ON[ ] !
• Example:&
AnyType!
sol ve: : r un( AnyType& ar gs) { !
MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; !
MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; !
!
Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; !
x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; !
r et ur n x; !
} ! Performance:&
• No&unnecessary©ing&
• No&internal&type&conversion&
18&
Eigen](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-4-320.jpg)








![15Pivotal Confidential–Internal Use Only
In general, use a convex optimization
framework
7 2.383 0.3904
6 2.869 0.4769
8 4.475 1.151
3 13.35 3.263
0 45.48 13.10
171.7 84.59
cution times
ure6: TheArchetypical Convex Function f(x) = x2
.
Application Objective
Least Squares
P
(u,y)2⌦(xT u − y)2
Lasso [38]
P
(u,y)2⌦(xT u − y)2 + µkxk1
Logisitic Regression
P
(u,y)2⌦log(1 + exp(−yxtu))
P T
Each step has an analytical formulation
that can be performed in parallel
Gradient Descent
Start at a random point
Repeat
Determine a descent direction
Choose a step size
Update the model
Until stopping criterion is satisfied](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-14-320.jpg)
![16Pivotal Confidential–Internal Use Only
Architecture
C API
(HAWQ, GPDB, PostgreSQL)
Low-level Abstraction Layer
(array operations,
C++ to DB type-bridge, …)
RDBMS
Built-in
Functions
User Interface
Functions for Inner Loops
(implements ML logic)
SQL, generated per
specification
C++
3.&Lack&of&language&support&for&
linear&algebra&
• C++&AbstracOon&Layer&uses&Eigen&
• (Dense)&Vectors&and&matrices:&
DOUBLE PRECI SI ON[ ] !
• Example:&
AnyType!
sol ve: : r un( AnyType& ar gs) { !
MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; !
MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; !
!
Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; !
x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; !
r et ur n x; !
} ! Performance:&
• No&unnecessary©ing&
• No&internal&type&conversion&
18&
Eigen](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-15-320.jpg)
![17Pivotal Confidential–Internal Use Only
Architecture
C API
(Greenplum, PostgreSQL, HAWQ)
Low-level Abstraction Layer
(array operations,
C++ to DB type-bridge, …)
RDBMS
Built-in
Functions
User Interface
High-level Iteration Layer
(iteration controller, …)
Functions for Inner Loops
(implements ML logic)
Python
SQL, generated per
specification
C++
3.&Lack&of&language&support&for&
linear&algebra&
• C++&AbstracOon&Layer&uses&Eigen&
• (Dense)&Vectors&and&matrices:&
DOUBLE PRECI SI ON[ ] !
• Example:&
AnyType!
sol ve: : r un( AnyType& ar gs) { !
MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; !
MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; !
!
Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; !
x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; !
r et ur n x; !
} ! Performance:&
• No&unnecessary©ing&
• No&internal&type&conversion&
18&
Eigen](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-16-320.jpg)


![20Pivotal Confidential–Internal Use Only
PivotalR: Bringing MADlib and HAWQ to a
familiar R interface
Challenge
Want to harness the familiarity of R’s interface and
the performance & scalability benefits of in-DB
analytics
d <- db.data.frame(”houses")
houses_linregr <-
madlib.lm(price ~ tax
+ bath
+ size
, data=d)
Pivotal R
SELECT madlib.linregr_train( 'houses’,
'houses_linregr’,
'price’,
'ARRAY[1, tax, bath, size]’);
SQL Code](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-19-320.jpg)



![26Pivotal Confidential–Internal Use Only
Class hierarchy
db.obj
db.data.frame db.Rquery
db.table db.view
Wrapper of objects in database
x = db.data.frame("table")
Resides in R only
x[,1:2],
merge(x, y, by="column")
Operations/
MADlib
functions
lookat
as.db.data.frame
operation](https://image.slidesharecdn.com/madlibandpivotalr-architecture-2-151218062220/85/MADlib-Architecture-and-Functional-Demo-on-How-to-Use-MADlib-PivotalR-23-320.jpg)













MADlib Architecture and Functional Demo on How to Use MADlib/PivotalR
- 1. 1Pivotal Confidential–Internal Use Only BUILT FOR THE SPEED OF BUSINESS
- 2. 2Pivotal Confidential–Internal Use Only 2Pivotal Confidential–Internal Use Only MADlib Architecture
- 3. 3Pivotal Confidential–Internal Use Only MPP (Massively Parallel Processing) Network Interconnect ... ... ...... Master Servers Query planning & dispatch Segment Servers Query processing & data storage SQL MapReduce External Sources Loading, streaming, etc. Shared-Nothing Database Architecture
- 4. 4Pivotal Confidential–Internal Use Only Architecture C API (HAWQ, GPDB, PostgreSQL) Low-level Abstraction Layer (array operations, C++ to DB type-bridge, …) RDBMS Built-in Functions User Interface Functions for Inner Loops (implements ML logic) SQL, generated per specification C++ 3.&Lack&of&language&support&for& linear&algebra& • C++&AbstracOon&Layer&uses&Eigen& • (Dense)&Vectors&and&matrices:& DOUBLE PRECI SI ON[ ] ! • Example:& AnyType! sol ve: : r un( AnyType& ar gs) { ! MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; ! MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; ! ! Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; ! x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; ! r et ur n x; ! } ! Performance:& • No&unnecessary©ing& • No&internal&type&conversion& 18& Eigen
- 5. 5Pivotal Confidential–Internal Use Only How do we implement scalability? Example: Linear Regression • Finding linear dependencies between variables y ≈ c0 + c1 · x1 + c2 · x2 + …? y | x1 | … -------+------------- 10.14 | 0 | … 11.93 | 0.69 | … 13.57 | 1.1 | … 14.17 | 1.39 | … 15.25 | 1.61 | … 16.15 | 1.79 | … Design matrix X Vector of dependent variables y Predictor (x1) Regressor(y)
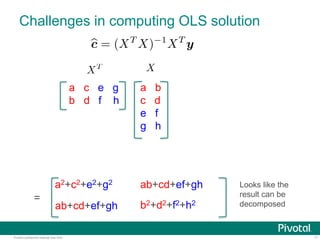
- 6. 7Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h Segment 1 Segment 2
- 7. 8Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h Segment 1 Segment 2 a c e g b d f h Segment1 Segment2
- 8. 9Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h a c e g b d f h a2+c2+e2+g2 = Data across nodes are multiplied
- 9. 10Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h a c e g b d f h a2+c2+e2+g2 = Data across nodes are multiplied! ab+cd+ef+gh
- 10. 11Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h a c e g b d f h a2+c2+e2+g2 = Looks like the result can be decomposed ab+cd+ef+gh b2+d2+f2+h2 ab+cd+ef+gh
- 11. 12Pivotal Confidential–Internal Use Only Challenges in computing OLS solution a b c d e f g h a c e g b d f h a2+c2+e2+g2 = Data across nodes are multiplied! ab+cd+ef+gh b2+d2+f2+h2 ab+cd+ef+gh = +a b e f e f a b +c d g h g hc d +
- 12. 13Pivotal Confidential–Internal Use Only Linear Regression: Streaming Algorithm How to compute with a single table scan? XT X XT y -1 XTyXTX + + -1
- 13. 14Pivotal Confidential–Internal Use Only Problem solved? … Not Yet Many ML solutions are iterative without analytical formulations Initialize problem Perform single step Has converged? Return results false true
- 14. 15Pivotal Confidential–Internal Use Only In general, use a convex optimization framework 7 2.383 0.3904 6 2.869 0.4769 8 4.475 1.151 3 13.35 3.263 0 45.48 13.10 171.7 84.59 cution times ure6: TheArchetypical Convex Function f(x) = x2 . Application Objective Least Squares P (u,y)2⌦(xT u − y)2 Lasso [38] P (u,y)2⌦(xT u − y)2 + µkxk1 Logisitic Regression P (u,y)2⌦log(1 + exp(−yxtu)) P T Each step has an analytical formulation that can be performed in parallel Gradient Descent Start at a random point Repeat Determine a descent direction Choose a step size Update the model Until stopping criterion is satisfied
- 15. 16Pivotal Confidential–Internal Use Only Architecture C API (HAWQ, GPDB, PostgreSQL) Low-level Abstraction Layer (array operations, C++ to DB type-bridge, …) RDBMS Built-in Functions User Interface Functions for Inner Loops (implements ML logic) SQL, generated per specification C++ 3.&Lack&of&language&support&for& linear&algebra& • C++&AbstracOon&Layer&uses&Eigen& • (Dense)&Vectors&and&matrices:& DOUBLE PRECI SI ON[ ] ! • Example:& AnyType! sol ve: : r un( AnyType& ar gs) { ! MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; ! MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; ! ! Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; ! x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; ! r et ur n x; ! } ! Performance:& • No&unnecessary©ing& • No&internal&type&conversion& 18& Eigen
- 16. 17Pivotal Confidential–Internal Use Only Architecture C API (Greenplum, PostgreSQL, HAWQ) Low-level Abstraction Layer (array operations, C++ to DB type-bridge, …) RDBMS Built-in Functions User Interface High-level Iteration Layer (iteration controller, …) Functions for Inner Loops (implements ML logic) Python SQL, generated per specification C++ 3.&Lack&of&language&support&for& linear&algebra& • C++&AbstracOon&Layer&uses&Eigen& • (Dense)&Vectors&and&matrices:& DOUBLE PRECI SI ON[ ] ! • Example:& AnyType! sol ve: : r un( AnyType& ar gs) { ! MappedMat r i x A = ar gs[ 0] . get As<MappedMat r i x>( ) ; ! MappedCol umnVect or b = ar gs[ 1] . get As<MappedCol umnVect or >( ) ; ! ! Mut abl eMappedCol umnVect or x = al l ocat eAr r ay<doubl e>( A. col s( ) ) ; ! x = A. col Pi vHousehol der Qr ( ) . sol ve( b) ; ! r et ur n x; ! } ! Performance:& • No&unnecessary©ing& • No&internal&type&conversion& 18& Eigen
- 17. 18Pivotal Confidential–Internal Use Only 18Pivotal Confidential–Internal Use Only But not all data scientists speak SQL … Accessing scalability through R
- 18. 19Pivotal Confidential–Internal Use Only Why R? O’Reilly: Strata 2013 Data Science Salary Survey “The preponderance of R and Python usage is more surprising … two most commonly used individual tools, even above Excel. R and Python are likely popular because they are easily accessible and effective open source tools.” That SQL/RDBisthetop bar isno surprise: accessingdataisthemeat and potatoes of data analysis, and has not been displaced by other tools. Thepreponderance of R and Python usageismoresurprising —operating systems aside, these werethetwo most commonly used individual tools, even aboveExcel, which for yearshasbeen thego-to
- 19. 20Pivotal Confidential–Internal Use Only PivotalR: Bringing MADlib and HAWQ to a familiar R interface Challenge Want to harness the familiarity of R’s interface and the performance & scalability benefits of in-DB analytics d <- db.data.frame(”houses") houses_linregr <- madlib.lm(price ~ tax + bath + size , data=d) Pivotal R SELECT madlib.linregr_train( 'houses’, 'houses_linregr’, 'price’, 'ARRAY[1, tax, bath, size]’); SQL Code
- 20. 21Pivotal Confidential–Internal Use Only PivotalR Design Overview 2. SQL to execute 3. Computation results 1. R SQL RPostgreSQL PivotalR Data lives hereNo data here Database/HAWQ w/ MADlib • Syntax is analogous to native R function • Data doesn’t need to leave the database • All heavy lifting, including model estimation & computation, are done in the database
- 21. 22Pivotal Confidential–Internal Use Only 22Pivotal Confidential–Internal Use Only Demo
- 22. 23Pivotal Confidential–Internal Use Only library(PivotalR) db.connect(port = 14526, dbname = "madlib") db.objects() x <- db.data.frame("madlibtestdata.dt_abalone") dim(x) names(x) x$rings lookat(x, 10) # look at a sample of table mean(x$rings) lookat(mean(x$rings)) fit <- madlib.lm(rings ~ . - id | sex, data = y) predict(fit, x) mean((x$rings - predict(fit, x))^2) x$sex <- as.factor(v$sex) m0 <- madlib.glm(resp ~ age, family="binomial", data=dbbank) mstep <- step(m0, scope=list( lower=~age, upper=~age + factor(marital) + factor(education) + factor(housing) + factor(loan) + factor(job))) Load the Library Connect to the database “madlib” on port 14526 List all the tables in the active connection Create an R object that references a table in the database Report #/rows and #/columns in the table Column names within the table Database query object representing “select rings from madlibtestdata.dt_abalone” Pull 10 rows of data from the table back into the R environment query object representing “select avg(rings) from madlibtestdata.dt_abalone” execute the query and report back the result Run a linear regression within the database and return a model object Create a query object representing scoring the model in the database Query object calculating the mean square error of the model Add a calculated factor column to the database query object Calculate a logistic regression model Perform stepwise feature selection Demonstration
- 23. 26Pivotal Confidential–Internal Use Only Class hierarchy db.obj db.data.frame db.Rquery db.table db.view Wrapper of objects in database x = db.data.frame("table") Resides in R only x[,1:2], merge(x, y, by="column") Operations/ MADlib functions lookat as.db.data.frame operation
- 24. 27Pivotal Confidential–Internal Use Only Some of current features A wrapper of MADlib • Generalized linear models (lm, glm) • Elastic Net (elnet) • Cross validation (generic.cv) • ARIMA • Tree methods (rpart, randomforest) • Table summary • $ [ [[ $<- [<- [[<- • is.na + - * / %% %/% ^ • & | ! • == != > < >= <= • merge • by • db.data.frame • as.db.data.frame • preview• sort • c mean sum sd var min max length colMeans colSums • db.connect db.disconnect db.list db.objects db.existsObject delete • dim • names • as.factor() • content And more ... (SQL wrapper) • predict
- 25. 28Pivotal Confidential–Internal Use Only We’re looking for contributors • Browse our help pages – Start page: madlib.net – Github pages • github.com/apache/incubator-madlib (SQL) • github.com/pivotalsoftware/pivotalr (R) • github.com/pivotalsoftware/pymadlib (Python) • Use our product and report issues: • https://issues.apache.org/jira/browse/MADLIB (Issue tracker) • user@madlib.incubator.apache.org (User forum) • dev@madlib.incubator.apache.org (Developer forum)
- 26. 29Pivotal Confidential–Internal Use Only Credits Leaders and contributors: Gavin Sherry Caleb Welton Joseph Hellerstein Christopher Ré Zhe Wang Florian Schoppmann Hai Qian Shengwen Yang Xixuan Feng and many others …
- 27. 30Pivotal Confidential–Internal Use Only 30Pivotal Confidential–Internal Use Only Thank you for your attention Important links: Product email: user@madlib.net Product site: madlib.net
- 28. 31Pivotal Confidential–Internal Use Only 31Pivotal Confidential–Internal Use Only Backup slides
- 29. 32Pivotal Confidential–Internal Use Only Performing a linear regression on 10 million rows in seconds Hellerstein et al. "The MADlib analytics library: or MAD skills, the SQL." Proceedings of the VLDB Endowment 5.12 (2012): 1700-1711.
- 30. 33Pivotal Confidential–Internal Use Only Reminder: Linear-Regression Model • • If residuals i.i.d. Gaussians with standard deviation σ: – max likelihood ⇔ min sum of squared residuals • First-order conditions for the following quadratic objective (in c) yield the minimizer
- 31. 34Pivotal Confidential–Internal Use Only Linear Regression: Streaming Algorithm How to compute with a single table scan? XT X XT y -1 XTX XTy
- 32. 35Pivotal Confidential–Internal Use Only PivotalR Architecture
- 33. 36Pivotal Confidential–Internal Use Only
- 34. 37Pivotal Confidential–Internal Use Only 37Pivotal Confidential–Internal Use Only PL/X Procedural Languages
- 35. 38Pivotal Confidential–Internal Use Only PivotalR vs PL/R PivotalR • Interface is R client • Execution is in database • Parallelism handled by PivotalR • Supports a portion of R R> x = db.data.frame(“t1”) R> l = madlib.lm(interlocks ~ assets + nation, data = t) PL/R • Interface is SQL client • Execution is in R • Parallelism via SQL function invocation • Supports all of R psql> CREATE FUNCTION lregr() … LANGUAGE PLR; psql> SELECT lregr( array_agg(interlocks), array_agg(assets), array_agg(nation) ) FROM t1;
- 36. 39Pivotal Confidential–Internal Use Only Parallelized R in Pivotal via PL/R: An Example SQL & R R piggy-backs on Pivotal’s parallel architecture Minimize data movement Build predictive model for each state in parallel TN Data CA Data NY Data PA Data TX Data CT Data NJ Data IL Data MA Data WA Data TN Model CA Model NY Model PA Model TX Model CT Model NJ Model IL Model MA Model WA Model
Editor's Notes
- #33: For a table of 10 million rows Num of independent variables (x axis) = number of columns in table. So a vertical slice allows you to look at scalability. See roughly linear scale in execution time with number of segments. * e.g., 6 segments approx 200 sec, 24 segments approx 50 sec (4x faster)