OpenEssayist: Extractive Summarisation and Formative Assessment (DCLA13)
Download as PPTX, PDF1 like3,617 views

The document discusses the development of an automated system, OpenEssayist, aimed at providing formative feedback on free-text essays submitted by postgraduate students at the Open University. It explores the techniques of extractive summarization, focusing on the identification of key phrases and sentences, and the integration of various tools for analyzing essay structure and content. The project also addresses challenges related to the educational context, self-regulation, and the effectiveness of feedback in improving essay quality.





![openEssayist
localhost:8065
phaeros.open.ac.uk:80
openEssayist
PHP, Epiphany
[Symfony2]
User
openEssayist
RESTful API
PHP, Epiphany
User
User
pyEA
RESTful API
Python, Flask
localhost:8064
AfterTheDeadline
Spell/Grammar
checker
Java
User
localhost:9998
Apache Tika
Text Extractor
Java
Orchestrator
(Open)
Learner Model
pyEssayAnalyser
Python, NLTK](https://image.slidesharecdn.com/openessayistdcla13-130409061120-phpapp02/85/OpenEssayist-Extractive-Summarisation-and-Formative-Assessment-DCLA13-6-320.jpg)

























OpenEssayist: Extractive Summarisation and Formative Assessment (DCLA13)
- 1. OpenEssayist: Extractive Summarisation and Formative Assessment of Free-Text Essays Nicolas Van Labeke, Denise Whitelock , Debora Field , Stephen Pulman, John Richardson Institute of Educational Technology – The Open University Department of Computer Science – University of Oxford
- 2. SAFeSEA: Research Questions • How can an automated system detect passages on which a human marker would usually give some feedback ? • Can existing methods of information extraction, summarization be adapted to select content for such feedback ? • How effectively can these methods deliver feedback ? • What effect does these techniques have on essay improvement? On current essay and in future ones ? On self-regulation and metacognition ?
- 3. Context • Essays: Open University (UK) postgraduate assignments – Distance learning, adult learners – 1500+ words, free-text & open-ended questions • No “Gold Standard”, wide range of content – Perfect test ground for extractive techniques – Impact of lack of (or limited) domain knowledge? • Bulk of activity (i.e. writing) takes place outside system – Usage of drafts “varies a lot” among students – Nature, scope and timing of feedback? • Limited possibility for “mock” experiments: • testing & evaluation on “live” material • Connection with summative (tutor-based) assessment ?
- 4. Education Postgraduate Course H810 Accessible online learning: supporting disabled students TMA1 (Tutor-Marked Assignment) – 1500 words Write a report explaining the main accessibility challenges for disabled learners that you work with or support in your own work context(s). Critically evaluate the influence of the context (e.g. country, institution, perceived role of online learning within education) on the: (1) identified challenges; (2) influence of legislation; (3) roles and responsibilities of key individuals; (4) role of assistive technologies in addressing these challenges. TMA2 – 3000 words Critically Evaluate your own learning resource in the following ways: 1. Briefly describe the resource and its accessibility features. 2. Evaluate the accessibility of your resource, identifying its strengths and weaknesses. 3. Reflect on the processes of creating and evaluating accessible resources.
- 5. Context • Essays: Open University (UK) postgraduate assignments – Distance learning, adult learners – 1500+ words, free-text & open-ended questions • No “Gold Standard”, wide range of content – Perfect test ground for extractive techniques – Impact of lack of (or limited) domain knowledge? • Bulk of activity (i.e. writing) takes place outside system – Usage of drafts “varies a lot” among students – Nature, scope and timing of feedback? • Limited possibility for “mock” experiments: • testing & evaluation on “live” material • Connection with summative (tutor-based) assessment ?
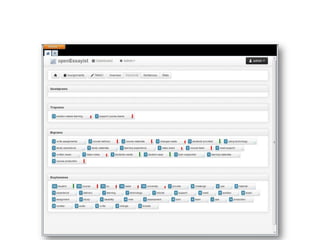
- 6. openEssayist localhost:8065 phaeros.open.ac.uk:80 openEssayist PHP, Epiphany [Symfony2] User openEssayist RESTful API PHP, Epiphany User User pyEA RESTful API Python, Flask localhost:8064 AfterTheDeadline Spell/Grammar checker Java User localhost:9998 Apache Tika Text Extractor Java Orchestrator (Open) Learner Model pyEssayAnalyser Python, NLTK
- 7. Extractive Summarisation • Hypothesis – quality and position of key phrases and key sentences within an essay (i.e., relative to the position of its structural components) give idea of how complete and well-structured the essay – provide a basis for building suitable models of feedback • Experimenting with two simpler summarisation strategies – key phrase extraction : identifying individual words or short phrases are the most suggestive of the content of a discourse – extractive summarisation: identifying whole key sentences. • Rapid implementation and testing
- 8. Summarisation Processes 1. NL pre-processing of text 2. unsupervised recognition of structural elements 3. unsupervised extraction of key words/phrases 4. unsupervised extraction of key sentences.
- 9. Pre-processing • Using NLTK (Python-base Natural Language Processing Toolkit) – tokenisers, – lemmatiser, – part-of-speech tagger, – List(s) of stop words. • Experimenting different approaches to define suitable stop word list(s) – domain-independent list? – Generated from appropriate reference materials (using TF-IDF, for example)?
- 10. Essay Structure • Restructure text as paragraphs/sentences • Automatic Identification of each paragraph’s structural role – Summary, Introduction, conclusion, body, references, … – Regardless of presence of content-specific headings – No clues from formatting markup (plain text submission) • Decision trees developed through manual experimentation – corpus of 135 student essays submitted in previous years for the same module that the evaluation will be carried out on. • Still need formal evaluation but output good enough for first rounds of OpenEssayist testing, and continually improving
- 12. Key words, lemmas and phrases • Unsupervised extractive summarisation using graph-based ranking methods (TextRank, Mihalcea & Tarau 2004, 2005) • Each unique word is represented by a node in the graph, and co- occurrence relations (specifically, within-sentence word adjacency) are represented by edges in the graph. • Compute a 'key-ness' value for each word in the essay ('Key-ness' can be understood as 'significance within the context of the essay‘) • Centrality algorithm used to calculate the significance of each word – betweenness centrality (Freeman 1977) and PageRank (Brin & Page 1998) – Roughly speaking, a word with a high centrality score is a word that sits adjacent to many other unique words which sit adjacent to many other unique words which…, and so on. • The words with high(est) centrality scores are the key words. – Decision needs to be made as to what proportion of the essay's words qualify as key words. • Sequences of keywords in the surface text identify within-sentence key phrases (bigrams, trigrams and quadgrams).
- 13. Key words, lemmas and phrases
- 14. Key Sentences • Similar graph-based ranking approach used to compute key-ness scores for whole sentences. • Instead of word adjacency (as in the key word graph), co-occurrence of words across pairs of sentences is the relation used to construct the graph. – similarity measures of every pair of sentences. • The similarity scores become edge weights in the graph, while whole sentences become the nodes. • TextRank key sentence algorithm (based on PageRank but with added edge weights) is then applied.
- 15. Extractive Summarisation - Sentences
- 16. Extractive Summarisation – Overview
- 17. Exploring The Design Space ❶Researcher-centred Design – Data-driven – Architecture setup, integration & refinement of tools – From discourse to summarisation – Emerging properties, hypotheses building
- 25. • Multiple External Representation • Mash-ups, reports, summaries, … • Highlighting co-occurrence of terms (or lack of) • Exploration & discovery, hypotheses building, eliciting recommendations & heuristics
- 26. Exploring The Design Space ① Researcher-centred Design – Data-driven – Architecture setup, integration & refinement of tools – From discourse to summarisation – Emerging properties, hypotheses building ❷ Learner-centred Design – Task-driven – Hypotheses testing & validation, refinement – From summarisation to formative feedback – Live evaluation
- 27. Question: What kind of feedback?
- 28. Section of essay Purpose of section Title Write the full question (title) at the top of your assignment. It will contain keywords (known as content and process words). See the 'Understanding the question' webpage for these. Introduction A paragraph or two to define key terms and themes and indicate how you intend to address the question. Main body A series of paragraphs written in full sentences that include specific arguments relating to your answer. It’s vital to include evidence and references to support your arguments. Conclusions A short section to summarise main points and findings. Try to focus on the question but avoid repeating what you wrote in the introduction. References A list of sources (including module materials) that are mentioned in the essay. • Introductions – An introduction provides your reader with an overview of what your essay will cover and what you want to say. – Essays introductions should • set out the aims of the assignment and signpost how your argument will unfold • introduce the issue and give any essential background information including a brief description of the major debates that lie behind the question • define the key words and terms • be between 5% and 10% of the total word count – Some students prefer to write the introduction at an early stage, others save it for when they have almost completed the assignment. If you write it early, don't allow it to constrain what you want to write. It's a good idea to check and revise the introduction after the first draft. • The body of your essay – … Open University - Skills for OU Study http://www.open.ac.uk/skillsforstudy/essays.php
- 29. Question: Reflective activities? • “Advice for action” – Expectation vs. intention – Reflection, self-report, validation of advices, … • Introducing user interventions in the system • Feeding back to the system? To the Essay Analyser?
- 30. Question: Drafts, History & Changes
- 31. Question: “Quality” of output?
- 32. Current and Future Work • Three lines of experimentations: – improve the different aspects of the essay analyser (e.g. different “key-ness” metrics, introduce domain-specific lists of stop-words) – Analyses of summarisation output (e.g. factor analysis) to run on existing corpus of essays • 5 years of essays on the H810 course, all marked and annotated by human tutors), • identify trends and markers to be used as progress/performance indicators; – Iterative, user-centred, design and testing of openEssaysit (refine possible usage scenarios, test pedagogical) • Currently proceeding with second design phase • First live evaluation, in authentic context, by a new cohort of students on the H810 module (Sept 2013)
Editor's Notes
- #10: Before extracting key terms and sentences from the text, the text is automatically pre-processed using some modules from the Natural Language Processing Toolkit (Bird et al. 2009): several tokenisers, a lemmatiser, a part-of-speech tagger, and a list of stop words. We are experimenting with different approaches to defining a suitable stop word list, and are not yet decided whether to use a domain-independent list or whether to use a domain-specific list derived from appropriate reference materials (using TF-IDF, for example).Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma
- #11: The identification of the essay structure is carried out using decision trees developed through manual experimentation with a corpus of 135 student essays submitted in previous years for the same module that the evaluation will be carried out on. The system automatically recognises which structural role is played by each paragraph in the essay (including summary, introduction, conclusion, main body, references, etc.). This identification is achieved regardless of the presence of content-specific headings and without getting clues from formatting mark-up. We have not yet carried out a formal evaluation of the structure identification procedure, but its accuracy rates are good enough to use in first rounds of OpenEssayist testing, and are continually improving.
- #13: Essay Analyser uses graph-based ranking methods to perform unsupervised extractive summarisation, following TextRank (Mihalcea & Tarau 2004, 2005). One graph is used to derive key words and short phrases, and a second graph is used for the derivation of key sentences. Regarding key words, to compute a 'key-ness' value for each word in the essay, each unique word is represented by a node in the graph, and co-occurrence relations (specifically, within-sentence word adjacency) are represented by edges in the graph. 'Key-ness' can be understood as 'significance within the context of the essay'. A centrality algorithm – we have experimented with betweenness centrality(Freeman 1977) and PageRank (Brin & Page 1998) – is used to calculate the significance of each word. Roughly speaking, a word with a high centrality score is a word that sits adjacent to many other unique words which sit adjacent to many other unique words which…, and so on. The words with high centrality scores are the key words. Since a centrality score is attributed to every unique word in the essay, a decision needs to be made as to what proportion of the essay's words qualify as key words. The key word distribution of scores follows the same shape for all essays, an acute elbow and then a very long tail, observed for word adjacency graphs by (FerreriCancho & Solé 2001). We therefore currently take the key-ness threshold to be the place where the elbow bend appears by eye to be sharpest. We are investigating alternative and less subjective methods of deciding where the threshold should be (e.g., investigating graph structure through randomisation methods). Once key words have been identified, the system matches sequences of these against the surface text to identify within-sentence key phrases (bigrams, trigrams and quadgrams).In fact the graph nodes are the lemmas of the unique words, but for brevity's sake, we will speak in terms of words.
- #15: A similar graph-based ranking approach is used to compute key-ness scores to rank the essay's sentences. Instead of word adjacency (as in the key word graph), co-occurrence of words across pairs of sentences is the relation used to construct the graph. More specifically, we currently use cosine similarity to derive a similarity score for every pair of sentences. The similarity scores become edge weights in the graph, while whole sentences become the nodes. The TextRank key sentence algorithm (based on PageRank but with added edge weights) is then applied. We are intending to experiment with alternative similarity measures, including vector space measures of word similarity originally described in (Schütze 1998).
- #18: Vagaries : An unexpected and inexplicable change in something (in a situation or a person's behaviour, etc.)Rule-of Thumb: A rule or principle that provides guidance to appropriate behaviour
- #27: Vagaries : An unexpected and inexplicable change in something (in a situation or a person's behaviour, etc.)Rule-of Thumb: A rule or principle that provides guidance to appropriate behaviour