



![SCAN [Xu+, KDD’07]
2
5
• Structural Similarity Computation
• based on neighbors of two vertices 𝑢 and 𝑣 (cosine measure):
• 𝑠𝑖𝑚 𝑢, 𝑣 = 𝑁 𝑢 ∩ 𝑁 𝑣 / |𝑁(𝑢)| ∙ |𝑁(𝑣)|
• 𝑢 and 𝑣 are similar neighbors, if
• they are connected
• their structural similarity 𝑠𝑖𝑚(𝑢, 𝑣) ≥ 𝜀
𝑁 6 = 5,6,7,8,9
𝑁 9 = 6,7,8,9,10,11
𝑠𝑖𝑚 6,9 = 4/ 5 ∙ 6 ≈ 0.73 similar:
𝑠𝑖𝑚(6,9) ≥ 0.6
𝜀 = 0.6, 𝜇 = 3](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-5-320.jpg)
![SCAN [Xu+, KDD’07]
2
6
• Core Checking
• a vertex 𝑢 is a core, if it has ≥ 𝜇 similar neighbors
• Structural Clustering
• clustering by similar neighbors from cores
• adopting Breadth-First-Search (BFS) for cluster expansion
core
non-core
corenon-core
similar
not-similar
𝜀 = 0.6, 𝜇 = 3](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-6-320.jpg)
![• Structural Clustering
• clustering by similar neighbors from cores
• adopting Breadth-First-Search (BFS) for cluster expansion
SCAN [Xu+, KDD’07]
2
7clusters
core
non-core
𝜀 = 0.6, 𝜇 = 3](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-7-320.jpg)
![pSCAN [Chang+, ICDE’16]
2
8
𝑁 6 = 5,6,7,8,9
𝑁 9 = 6,7,8,9,10,11
𝑠𝑖𝑚 6,9 = 4/ 5 ∙ 6 ≈ 0.73
• Pruning Similarity Computations
• adopt union-find data-structure, change algorithmic design
• avoid redundant similarity computation, apply pruning techniques
• apply early termination in similarity computation
set-intersection
expensive](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-8-320.jpg)












![Core Consolidating
2
21
finalizing all vertex roles
two phases
work-efficiency-proof: the similarity computation is at most invoked once for
the similarity values 𝒔𝒊𝒎[𝒆(𝒖, 𝒗)] and 𝒔𝒊𝒎[𝒆(𝒗, 𝒖)]](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-21-320.jpg)






![Experimental Setup
2
28
• Environments
• Xeon Phi Processor (KNL): 64 cores (2 VPUs / core), AVX512,
64KB/1024KB L1/L2 caches, 16GB MCDRAM (cache mode),
96GB RAM
• Xeon CPU E5-2650: 20 cores, AVX2, 64KB/256KB/25MB
L1/L2/L3 cache, 64GB RAM
• Algorithms
• Sequential: SCAN [Xu+, KDD’07], pSCAN [Chang+, ICDE’16]
• Parallel: anySCAN [Mai+, ICDE’17], SCAN-XP [Takahashi,
NDA’17], our ppSCAN, ppSCAN-NO (without vectorization)
• Graphs (Billion-Edge)
• Real-World: Orkut/Twitter/Friendster (Social), Webbase (Web)
• Synthetic Power-Law: ROLL Graphs [Hadian+, SIGMOD’16]](https://image.slidesharecdn.com/ppscan-180816221004/85/Parallelizing-Pruning-based-Graph-Structural-Clustering-28-320.jpg)







Parallelizing Pruning-based Graph Structural Clustering
- 1. Yulin Che, Shixuan Sun, Qiong Luo Hong Kong University of Science and Technology 1 Parallelizing Pruning-based Graph Structural Clustering
- 2. 2 2 Outline 3、Parallelization & Vectorization 1、Pruning-based Graph Structural Clustering 2、Performance Bottleneck & Challenge 4、Experimental Study 5、Conclusion Outline
- 3. Graph Structural Clustering 2 3 • Graph Clustering • group vertices into clusters: dense intra connection and sparse inter connection • Application • do recommendations on social networks, web graphs and co- purchasing graphs • Graph Structural Clustering (Our Focus) • utilize structural similarity among vertices for clustering • identify clusters and vertex roles (cores, non-cores)
- 4. • Graph Structural Clustering (Our Focus) • utilize structural similarity among vertices for clustering • identify clusters and vertex roles (cores, non-cores: hubs, outliers) Graph Structural Clustering Example 2 4clusters core non-core
- 5. SCAN [Xu+, KDD’07] 2 5 • Structural Similarity Computation • based on neighbors of two vertices 𝑢 and 𝑣 (cosine measure): • 𝑠𝑖𝑚 𝑢, 𝑣 = 𝑁 𝑢 ∩ 𝑁 𝑣 / |𝑁(𝑢)| ∙ |𝑁(𝑣)| • 𝑢 and 𝑣 are similar neighbors, if • they are connected • their structural similarity 𝑠𝑖𝑚(𝑢, 𝑣) ≥ 𝜀 𝑁 6 = 5,6,7,8,9 𝑁 9 = 6,7,8,9,10,11 𝑠𝑖𝑚 6,9 = 4/ 5 ∙ 6 ≈ 0.73 similar: 𝑠𝑖𝑚(6,9) ≥ 0.6 𝜀 = 0.6, 𝜇 = 3
- 6. SCAN [Xu+, KDD’07] 2 6 • Core Checking • a vertex 𝑢 is a core, if it has ≥ 𝜇 similar neighbors • Structural Clustering • clustering by similar neighbors from cores • adopting Breadth-First-Search (BFS) for cluster expansion core non-core corenon-core similar not-similar 𝜀 = 0.6, 𝜇 = 3
- 7. • Structural Clustering • clustering by similar neighbors from cores • adopting Breadth-First-Search (BFS) for cluster expansion SCAN [Xu+, KDD’07] 2 7clusters core non-core 𝜀 = 0.6, 𝜇 = 3
- 8. pSCAN [Chang+, ICDE’16] 2 8 𝑁 6 = 5,6,7,8,9 𝑁 9 = 6,7,8,9,10,11 𝑠𝑖𝑚 6,9 = 4/ 5 ∙ 6 ≈ 0.73 • Pruning Similarity Computations • adopt union-find data-structure, change algorithmic design • avoid redundant similarity computation, apply pruning techniques • apply early termination in similarity computation set-intersection expensive
- 9. Motivation of Parallelization 2 9 On Twitter (0.7-billion-edge) • Motivation of Parallelizing pSCAN • cost too much time for interactive exploration of clustering results • cost most from the set-intersection based similarity computation
- 10. 2 10 Outline 3、Parallelization & Vectorization 1、Pruning-based Graph Structural Clustering 2、Performance Bottleneck & Challenge 4、Experimental Study 5、Conclusion
- 11. Time BreakDown (SCAN and pSCAN) 2 11 On LiveJournal/Orkut/Twitter • Observations • similarity computation is the performance bottleneck • workload reduction of pSCAN is light-weight but useful
- 12. pSCAN Parallelization Challenge 2 12 • Data Dependency • there exists concurrent access of lower and upper bounds of number of similar neighbors • a priority queue for selecting vertex with max upper bound of similar neighbors requires heavy synchronization • owing to the similarity reuse technique, similarity values 𝒔𝒊𝒎(𝒖, 𝒗) and 𝒔𝒊𝒎(𝒗, 𝒖) are dependent • Clustering Concurrency Issues • union-find operations should be thread-safe • cluster id initialization and assignment should be thread-safe • Workload Skew and Irregularity • the workload for each vertex depends on its degree and role • pruning techniques make the workload irregular
- 13. 2 13 Outline 3、Parallelization & Vectorization 1、Pruning-based Graph Structural Clustering 2、Performance Bottleneck & Challenge 4、Experimental Study 5、Conclusion
- 14. Two-Step Multi-Phase Design Overview 2 14 • Step 1: Role Computing (Determining Core or Non-Core) • similarity pruning phase (without similarity computation) • core checking phase • core consolidating phase (finalizing roles of all the vertices) • Step 2: Core and Non-Core Clustering • core clustering without similarity computation phase • finalizing core clustering with similarity computation phase • cluster id initialization phase • non-core clustering (cluster id assignment) phase • Computation Optimizations • degree-based task scheduling: dealing with the workload skewness • pivot-based set-intersection vectorization: improving the efficiency of similarity computation
- 15. Step 1 : Role Computing 2 15 core non-core finalizing vertex roles (either core or non-core), stashing some similarity values (unknow/similar/not-similar)
- 16. Similarity Pruning 2 16 • Utilize Similarity Definition & Min-Max Pruning • do not incur set intersections (similarity computations) • utilize lower and upper bounds of number of similar neighbors similar not-similar 𝑁 0 ∩ 𝑁 1 ≥ 2 𝑠𝑖𝑚(0,1) ≥ 2/ 4 ∙ 2 ≈ 0.71 > 𝜀 𝑁 9 ∩ 𝑁 11 ≤ 𝑁 11 = 2 𝑠𝑖𝑚(9,11) ≤ 2/ 6 ∙ 2 ≈ 0.58 < 𝜀 lower bound upper bound
- 17. Similarity Pruning 2 17 • Utilize Similarity Definition & Min-Max Pruning • do not incur set intersections (similarity computations) • utilize lower and upper bounds of number of similar neighbors this phase determines some vertex roles without similarity computations lower bound upper bound local variables 𝒔𝒅 (similar degree) and 𝒆𝒅 (effective degree): lower and upper bounds of 𝑢’s similar neighborhood size
- 18. • Vertex Exploration Order Constraint (𝒖 < 𝒗): • to guarantee no redundant computation: each undirected edge is computed at most once for the similarity value • Core Checking and Consolidating Two-Phase • to apply similarity reuse technique given vertex order constraint, while finalizing all vertex roles Core Checking and Consolidating 2 18 after the two parallel phases, all vertex roles are known two phases
- 19. Core Checking 2 19 two phases 1) initialize pruning related lower and upper bounds, and see if we can benefit from parallel core checking from 𝑢’s neighbors with the min- max pruning technique
- 20. Core Checking 2 20 two phases 2) determine some vertex roles, and apply the similarity reuse and min-max pruning techniques
- 21. Core Consolidating 2 21 finalizing all vertex roles two phases work-efficiency-proof: the similarity computation is at most invoked once for the similarity values 𝒔𝒊𝒎[𝒆(𝒖, 𝒗)] and 𝒔𝒊𝒎[𝒆(𝒗, 𝒖)]
- 22. Step 2 : Core and Non-Core Clustering 2 22 core and non-core clustering cluster 0 cluster 1 non-core
- 23. Core Clustering 2 23 • Two Phase Separation • core clustering using already known similarity values without set intersections • finalizing core clustering with set intersections union-find pruning vertex order constraint vertex order constraint • Avoiding Redundant Computation • adding 𝑢 < 𝑣 constraint during the clustering for both phases • applying union-find pruning in the second phase two phases
- 24. Non-Core Clustering 2 24 • Two Phase Separation • cluster id initialization using atomic operations • non-core cluster id assignment from all the cores to similar neighbors (to form final results) CAS atomic operations cluster id assignment
- 25. Degree-based Task Scheduling 2 25 degree-accumulation- based-task-submission handling tail task • Dynamic Scheduling • vertex computations relate to the degree and role of the vertex in all the phases, for the exploration of neighbors and computations • a task can be represented with 𝑣 𝑏𝑒𝑔, 𝑣 𝑒𝑛𝑑 , and the parameter of range size is tunable (in our experimental setting: 32768) Dynamic Scheduling Example for Core Checking
- 26. Set-Intersection Vectorization 2 26 1. Find the first element in u’s sorted neighbors ≥ pivot_v 2. Find the first element in v’s sorted neighbors ≥ pivot_u 3. Count the match upper and lower bounds early termination
- 27. 2 27 Outline 3、Parallelization & Vectorization 1、Pruning-based Graph Structural Clustering 2、Performance Bottleneck & Challenge 4、Experimental Study 5、Conclusion
- 28. Experimental Setup 2 28 • Environments • Xeon Phi Processor (KNL): 64 cores (2 VPUs / core), AVX512, 64KB/1024KB L1/L2 caches, 16GB MCDRAM (cache mode), 96GB RAM • Xeon CPU E5-2650: 20 cores, AVX2, 64KB/256KB/25MB L1/L2/L3 cache, 64GB RAM • Algorithms • Sequential: SCAN [Xu+, KDD’07], pSCAN [Chang+, ICDE’16] • Parallel: anySCAN [Mai+, ICDE’17], SCAN-XP [Takahashi, NDA’17], our ppSCAN, ppSCAN-NO (without vectorization) • Graphs (Billion-Edge) • Real-World: Orkut/Twitter/Friendster (Social), Webbase (Web) • Synthetic Power-Law: ROLL Graphs [Hadian+, SIGMOD’16]
- 29. On KNL Overall Performance (on CPU and KNL) 2 29 On CPU • Algorithm Comparison • SCAN and pSCAN lack parallelization • SCAN-XP lacks usage of pruning techniques • anySCAN suffers from heavy synchronization and poor memory locality, and runs out of memory on webbase and friendster datasets • ppSCAN has good memory locality and negligible synchronization overheads, and utilizes vectorization AVX2 on CPU and AVX512 on KNL
- 30. Set-Intersection Invocation Reduction 2 30 • Work Efficiency • multi-phase computation does not introduce more workload • ppSCAN even compute less because of the similarity pruning and parallel core checking benefits 𝝁 = 𝟏𝟎 𝝁 = 𝟓
- 31. Set-Intersection Vectorization Improvement 2 31 𝝁 = 𝟓 (On Both CPU and KNL) • Core Checking Speedup from Vectorization • on CPU: at most 3.5x, on KNL: at most 4.5x • vectorization have better performance with more workloads (when memory access is not a bottleneck, e.g., when 𝜀 = 0.1 , intensive set intersections hide the memory access latency
- 32. Scalability to Number of threads 2 32 • Scalability and Time Breakdown • all the four phases scale well to number of threads • speedup of core checking is better than other phases, because the intensive set intersection computations hide the memory access latency • time breakdown ratio: • core checking and consolidating > similarity pruning > non-core clustering > core clustering 𝜺 = 𝟎. 𝟐, 𝝁 = 𝟓 (On KNL)
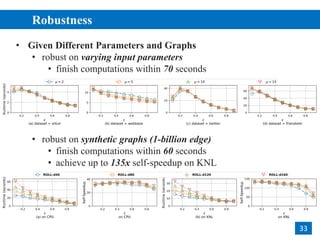
- 33. Robustness 2 33 • Given Different Parameters and Graphs • robust on varying input parameters • finish computations within 70 seconds • robust on synthetic graphs (1-billion edge) • finish computations within 60 seconds • achieve up to 135x self-speedup on KNL
- 34. 2 34 Outline 3、Parallelization & Vectorization 1、Pruning-based Graph Structural Clustering 2、Performance Bottleneck & Challenge 4、Experimental Study 5、Conclusion
- 35. Conclusion 2 35 • Parallelization & Vectorization Design • multi-phase lock-free parallel vertex computations • dynamic degree-based vertex computation task scheduling • pivot-based set intersection vectorization • Experimental Study • ppSCAN is about 2x faster on KNL (64 cores, AVX512) than on Xeon CPU (20 cores, AVX2) because of wider SIMD width • on KNL, two orders of magnitude faster than the sequential pSCAN • on KNL, one order of magnitude faster than the parallel anySCAN and SCAN-XP • on KNL, up to 135x self-speedup (over single-thread ppSCAN)
- 36. • Source Codes / Figures / Related Projects : https://github.com/GraphProcessor/ppSCAN • More Experimental Studies (Scripts / Figures): https://github.com/GraphProcessor/ppSCAN/tree/master/pyt hon_experiments • This PPT: https://www.dropbox.com/sh/i1r45o2ceraey8j/AAD8V3 WwPElQjwJ0-QtaKAzYa?dl=0&preview=ppSCAN.pdf End - Q & A 36