Fast, Scalable Quantized Neural Network Inference on FPGAs with FINN and LogicNets
0 likes345 views

This document provides a summary of a presentation about quantized neural network inference on FPGAs using FINN and LogicNets. It discusses: - Xilinx Research Labs in Dublin and their work quantifying machine learning applications on Xilinx devices. - How neural network quantization can improve efficiency by reducing precision while trading off accuracy, and how this is well-suited for FPGAs. - The FINN toolflow which includes quantization-aware training in PyTorch with Brevitas, the FINN compiler to map networks to hardware, and deployment with PYNQ. - LogicNets which further improves efficiency by unfolding DNNs into fully pipelined datapath circuits for



















![© Copyright 2020 Xilinx
LogicNets for Network Intrusion Detection
>> 25
4Mark incoming packets as suspicious (or not)
4UNSW-NB15 dataset [Moustafa et al.]
¬ 49-input, 1-output classification problem
¬ Inputs derived from TCP packet fields
Config Accuracy LUT Performance* Latency
2-layer
𝛽 = 2, 𝛾 = 7 83.88% 3.5 k 666 M SPS 3 ns
4-layer
𝛽 = 2, 𝛾 = 7 91.30% 15.9 k 471 M SPS 10.5 ns
More info:
https://arxiv.org/abs/2004.03021 [FPL’20 preprint]
http://y2u.be/jJRwyHD_UUI [5-min FCCM’20 video]](https://image.slidesharecdn.com/scalablequantizedneuralnetworkinferenceonfpgaswithfinnandlogicnetsxilinx-200714160732/85/Fast-Scalable-Quantized-Neural-Network-Inference-on-FPGAs-with-FINN-and-LogicNets-25-320.jpg)

Fast, Scalable Quantized Neural Network Inference on FPGAs with FINN and LogicNets
- 1. © Copyright 2020 Xilinx Fast, Scalable Quantized Neural Network Inference on FPGAs with FINN & LogicNets @ KTN AI Webinar on Vision Systems, 2020-07-03 Yaman Umuroglu, Senior Research Scientist Xilinx Research Labs
- 2. © Copyright 2020 Xilinx Xilinx Research, Dublin • Established over 14 years ago • Slowly expanding and increasingly leveraging external funding (IDA, H2020) • 6 full-time researchers + interns • Applications & Architectures • Quantifying the value proposition of Xilinx devices in machine learning • In collaboration with Partners, Customers and Universities Lucian Petrica, Giulio Gambardella, Alessandro Pappalardo, Ken O’Brien, Michaela Blott (leader), Nick Fraser, Yaman Umuroglu (from left to right)
- 3. © Copyright 2020 Xilinx How Efficient Does Your DNN Need To Be? A Spectrum of FPGA Inference Alternatives less efficient generic broad scope more efficient co-designed specialized
- 4. © Copyright 2020 Xilinx Deep Neural Networks with Floating Point Arithmetic 4 sum 0.12 -1.35 7.77 ReLU * 1.1 * -0.1 * -0.3 0.3 float32 weights float32 inputs float32 output energy intensive! Fundamentally caps (performance and power) efficiency
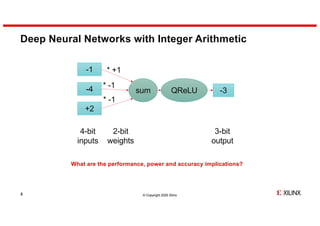
- 5. © Copyright 2020 Xilinx Deep Neural Networks with Integer Arithmetic 5 2-bit weights 4-bit inputs 3-bit output sum -1 -4 +2 QReLU * +1 * -1 * -1 -3 What are the performance, power and accuracy implications?
- 6. Benefits of Quantization on FPGAs 6 On-chip weights ~60 M ~30 M ~10 M ~5 M ~2 M Precision 1b 4b 8b 16b 32b Xilinx UltraScale+ MPSoC ZU19EG (Vivado HLS, conservative estimates) 30x Approx. Peak GOPS 66 000 20 000 4 000 1 000 300 200x Trillions of quantized operations per second Weights can stay entirely on-chip compute memory Great for energy efficiency! But what about accuracy?
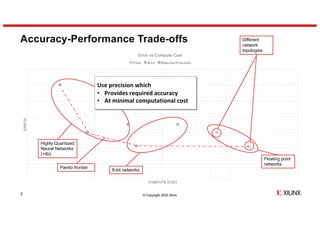
- 7. © Copyright 2020 Xilinx ERROR COMPUTE COST Error vs Compute Cost Float 8-bit Reduced Precision Accuracy-Performance Trade-offs 7 Floating point networks Different network topologies 8-bit networks Highly Quantized Neural Networks (<4b) Use precision which • Provides required accuracy • At minimal computational cost Pareto frontier
- 8. © Copyright 2020 Xilinx Customizing Hardware Architectures ML Operations 4Hardened arithmetic ¬ Specific operators ¬ Specific data types (INT8) 4Benefits of reduced precision 4Popular layer-by-layer compute ¬ One size fits all CNN Matrix of Processing Engines DPUDMA On-chip buffering MAC, VLIW, Vector Processor 8
- 9. © Copyright 2020 Xilinx How Efficient Does Your DNN Need To Be? A Spectrum of FPGA Inference Alternatives Layer-by-layer compute (Matrix of Processing Engines) Optimizing compiler/scheduler Down to 4-bit DPU, overlays (10k+ FPS) less efficient generic broad scope more efficient co-designed specialized FINN (10M+ FPS) Generated heterogeneous streaming architecture Custom topologies, arithmetic and hardware
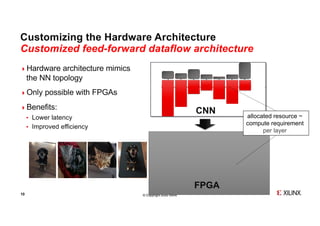
- 10. © Copyright 2020 Xilinx dogcat catdog Customizing the Hardware Architecture Customized feed-forward dataflow architecture 10 4Hardware architecture mimics the NN topology 4Only possible with FPGAs 4Benefits: ¬ Lower latency ¬ Improved efficiency FPGA CNN allocated resource ~ compute requirement per layer
- 11. © Copyright 2020 Xilinx Few-bit QNNs + FPGA Dataflow: Showcases 11 ResNet-50 on Alveo U250 2000 FPS @ 70 W 2 ms latency Complex Topologies High Throughput & Low Latency MNIST MLP on ZC706 12.3 M FPS @ 20 W 310 ns latency Low-Power, Real-Time Image Classification CIFAR-10 CNV on Pynq-Z1 3000 FPS @ 2.5 W 1 ms latency
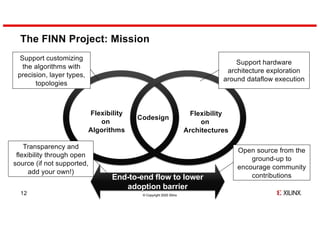
- 12. © Copyright 2020 Xilinx End-to-end flow to lower adoption barrier The FINN Project: Mission 12 Codesign Support hardware architecture exploration around dataflow execution Support customizing the algorithms with precision, layer types, topologies Open source from the ground-up to encourage community contributions Transparency and flexibility through open source (if not supported, add your own!) Flexibility on Algorithms Flexibility on Architectures
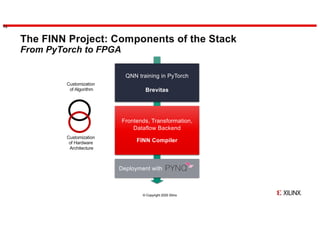
- 13. © Copyright 2020 Xilinx The FINN Project: Components of the Stack From PyTorch to FPGA 13 QNN training in PyTorch Brevitas Frontends, Transformation, Dataflow Backend FINN Compiler Deployment with Customization of Algorithm Customization of Hardware Architecture
- 14. 14 QNN training in PyTorch Brevitas Frontends, Transformation, Dataflow Backend FINN Compiler Deployment with Quantization-Aware Training in PyTorch with Brevitas
- 15. © Copyright 2020 Xilinx accuracy loss L Brevitas: A PyTorch library for Quantization-Aware Training Precision Preset or learned Scaling Factors Granularities, strategies and constraints Target Tensors Weights, activations, accumulators Loss Function to take HW implementation cost into account add quantization resize layers change hyperparameters retrain FP32 INT 15 https://github.com/Xilinx/brevitas
- 16. The FINN Compiler 16 QNN training in PyTorch Brevitas Frontends, Transformation, Dataflow Backend FINN Compiler Deployment with
- 17. An Overview of the FINN Compiler 17 › Python library of graph transformations » Each consumes and produces an ONNX graph › User calls sequence of transformations to create their own flow » Example end-to-end flows to get started Code Generator Import FINN HLS Library Synthesizable description Hardware Cost Model Vivado Synthesis, PAR Software Library Host Run-time FPGA Platform ONNX Streamlining Hardware Mapping Resource Allocation https://github.com/Xilinx/finn
- 18. Deployment with PYNQ 18 QNN training in PyTorch Brevitas Frontends, Transformation, Dataflow Backend FINN Compiler Deployment with
- 19. Deployment with for Python Productivity 19 › Use PYNQ-provided Python abstractions and drivers › User provides Numpy array in, calls driver, gets Numpy array out » Internally use PYNQ DMA driver to wr/rd NumPy arrays into I/O streams # numpy array shapes for i/o ishape_packed = (1, 49, 2) oshape_packed = (1, 1, 40) # set up the DMA dma.sendchannel.transfer(ibuf_packed_device) dma.recvchannel.transfer(obuf_packed) # wait until all transfers complete dma.sendchannel.wait() dma.recvchannel.wait() https://github.com/Xilinx/PYNQ
- 20. © Copyright 2020 Xilinx Join our Growing Open-Source Community! 20 Japanese documentation effort + «cucumber sorting» University courses, student/hobbyist projects Sketch Recognition (Xilinx Edinburgh)
- 21. © Copyright 2020 Xilinx LogicNets 21
- 22. © Copyright 2020 Xilinx DNNs in Extreme-Throughput Applications 22 4How do we mix DNNs into extreme-throughput applications? ¬ Need DNNs running at 100Ms of FPS, sub-microsecond latency Source:ThomasJames,CERN Level 1 Trigger Front End Pipelines Trigger FPGAs / ASICs Coarse-Grained Data Readout Buffers CERN CMS Experiment Network Intrusion Detection ~ 7 Tb/s 3 𝝁s ~ 500 Tb/s 3 𝝁s ~ 1.2 Tb/s 10-100sGb/s 10-100sGb/s
- 23. © Copyright 2020 Xilinx How Efficient Does Your DNN Need To Be? A Spectrum of FPGA Inference Alternatives Layer-by-layer compute (Matrix of Processing Engines) Optimizing compiler/scheduler DPU, overlays (10k+ FPS) less efficient generic broad scope more efficient co-designed specialized FINN (10M+ FPS) Generated heterogeneous streaming architecture Custom topologies, arithmetic and hardware LogicNets (100M+ FPS) The DNN is the circuit Fully unfolded, pipelined, feedforward datapaths
- 24. © Copyright 2020 Xilinx LogicNets at a Glance 24 PyTorch FPGA Specialized DNN Topology (with sparsity + quantization constraints) circuit Fully-spatial Implementation convertDataset training II=1 low logic depth, high Fclk 100M’s of samples per second
- 25. © Copyright 2020 Xilinx LogicNets for Network Intrusion Detection >> 25 4Mark incoming packets as suspicious (or not) 4UNSW-NB15 dataset [Moustafa et al.] ¬ 49-input, 1-output classification problem ¬ Inputs derived from TCP packet fields Config Accuracy LUT Performance* Latency 2-layer 𝛽 = 2, 𝛾 = 7 83.88% 3.5 k 666 M SPS 3 ns 4-layer 𝛽 = 2, 𝛾 = 7 91.30% 15.9 k 471 M SPS 10.5 ns More info: https://arxiv.org/abs/2004.03021 [FPL’20 preprint] http://y2u.be/jJRwyHD_UUI [5-min FCCM’20 video]
- 26. © Copyright 2020 Xilinx Thank You 26