Lecture 1 introduction to parallel and distributed computing
5 likes4,797 views

The course on parallel and distributed computing aims to equip students with skills in parallel algorithms, performance analysis, task decomposition, and parallel programming. It covers a wide range of topics including the history of computing, Flynn's taxonomy, various parallel architectures, and the principles of distributed systems. Assessment includes lab assignments and exams, while optional references provide additional resources for deeper understanding.


































Lecture 1 introduction to parallel and distributed computing
- 1. Parallel and Distributed Computing CST342-3 Vajira Thambawita
- 2. Learning Outcomes At the end of the course, the students will be able to • - define Parallel Algorithms • - recognize parallel speedup and performance analysis • - identify task decomposition techniques • - perform Parallel Programming • - apply acceleration strategies for algorithms
- 3. Contents • Sequential Computing, History of Parallel Computation, Flynn’s Taxonomy, Process, threads, Pipeline, parallel models, Shared Memory UMA,NUMA, CCUMA, Ring ,Mesh , Hypercube topologies, Cost and Complexity analysis of the interconnection networks, Task Partition , Data Decomposition, Task Mapping, Tasks and Decomposition , Processes and Mapping ,Processes Versus Processors, Granularity, processing, elements, Speedup , Efficiency , overhead, Practical ,Introduction to Pthered library, CUDA program , MPICH, Introduction to Distributed Computing, Centralized System , Comparison , mini Computer ,Workstation models, Process pool , analysis, Distributed OS, Remote procedure call ,RPC, Sun RPC, Distributed Resource Management, Fault Tolerance
- 4. References • Ananth,G, Anshul,G, Karypis,G and Kumar,V, 2003, Introduction to Parallel Computing , 2nd Edition , Addison Wesley Optional References: • CUDA Toolkit Documentation • Introduction to Parallel Computing, Second Edition By Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar • Programming on Parallel Machines, Norm Matloff • Introduction to High Performance Computing for Scientists and Engineers, Georg Hager, Gerhard Wellein
- 5. Evaluation • Continuous Assessment: • 60% - Lab assignments, Tutorials, Quizzes, • End Semester Examination: • 40% - 2hrs or 3hrs paper
- 6. Knowledge • Data structures and algorithms • C programming
- 8. Four decades of computing • Batch Era • Time sharing Era • Desktop Era • Network Era
- 9. Batch era • Batch processing • Is execution of a series of programs on a computer without manual intervention • The term originated in the days when users entered programs on punch cards
- 10. Time-sharing Era • time-sharing is the sharing of a computing resource among many users by means of multiprogramming and multi-tasking • Developing a system that supported multiple users at the same time
- 11. Desktop Era • Personal Computers (PCs) • With WAN
- 12. Network Era • Systems with: • Shared memory • Distributed memory • Example for parallel computers: Intel iPSC, nCUBE
- 13. FLYNN's taxonomy of computer architecture Two types of information flow into processor: Instructions Data what are instructions and data?
- 14. FLYNN's taxonomy of computer architecture 1. single-instruction single-data streams (SISD) 2. single-instruction multiple-data streams (SIMD) 3. multiple-instruction single-data streams (MISD) 4. multiple-instruction multiple-data streams (MIMD)
- 17. Parallel Computers • all stand-alone computers today are parallel from a hardware perspective
- 18. Parallel Computers • Networks connect multiple stand-alone computers (nodes) to make larger parallel computer clusters.
- 19. Why Use Parallel Computing? • SAVE TIME AND/OR MONEY:
- 20. Why Use Parallel Computing? • SOLVE LARGER / MORE COMPLEX PROBLEMS Grand Challenge Problems ?
- 21. Why Use Parallel Computing? • PROVIDE CONCURRENCY
- 22. Why Use Parallel Computing? • TAKE ADVANTAGE OF NON-LOCAL RESOURCES:
- 23. Why Use Parallel Computing? • MAKE BETTER USE OF UNDERLYING PARALLEL HARDWARE • Modern computers, even laptops, are parallel in architecture with multiple processors/cores
- 24. BACK to Flynn's Classical Taxonomy
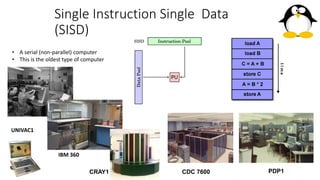
- 25. Single Instruction Single Data (SISD) • A serial (non-parallel) computer • This is the oldest type of computer UNIVAC1 IBM 360 CRAY1 CDC 7600 PDP1
- 26. Single Instruction Multiple Data (SIMD) ILLIAC IV MasPar Cray X-MP Cray Y-MP Cell Processor (GPU)
- 27. Multiple Instruction Single Data The Space Shuttle flight control computers
- 28. Multiple Instruction Multiple Data (MIMD) IBM POWER5 HP/Compaq Alphaserver Intel IA32 AMD Opteron
- 29. What are we going to learn?
- 30. Shared Memory System • A shared memory system typically accomplishes interprocessor coordination through a global memory shared by all processors. • Ex: Server systems, GPGPU
- 31. Message Passing System (Distributed Memory) • This kind of systems typically combine the local memory and processor at each node of the interconnection network • There is no global memory • Use message passing technique to move data from one local memory to another
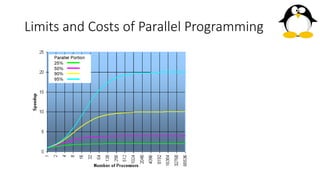
- 32. Limits and Costs of Parallel Programming • Amdahl's Law: Amdahl's Law states that potential program speedup is defined by the fraction of code (P) that can be parallelized: 𝑆𝑝𝑒𝑒𝑑𝑢𝑝 = 1 1 − 𝑝 • If none of the code can be parallelized, P = 0 and the speedup = 1 (no speedup). • If all of the code is parallelized, P = 1 and the speedup is infinite (in theory).
- 33. Limits and Costs of Parallel Programming • If 50% of the code can be parallelized, maximum speedup = 2, meaning the code will run twice as fast.
- 34. Limits and Costs of Parallel Programming • Introducing the number of processors performing the parallel fraction of work, the relationship can be modeled by: 𝑠𝑝𝑒𝑒𝑑𝑢𝑝 = 1 𝑃 𝑁 + 𝑆 • where P = parallel fraction, N = number of processors and S = serial fraction
- 35. Limits and Costs of Parallel Programming
- 36. Next • Parallel Computer Memory Architectures